
字节跳动基于Apache Hudi构建实时数据湖平台实践
一篇关于字节跳动基于 Apache Hudi 的实时数据湖平台的分享。 ...
流数据湖平台Apache Paimon(六)集成Spark之DML插入数据
4.4. 插入数据INSERT 语句向表中插入新行。插入的行可以由值表达式或查询结果指定,跟标准的sql语法一致。INSERT INTO table_identifier [ part_spec ] [ column_list ] { value_expr | query }part_spec可选,...

流数据湖平台Apache Paimon(五)集成 Spark 引擎
第4章 集成 Spark 引擎4.1 环境准备Paimon 目前支持 Spark 3.4、3.3、3.2 和 3.1。课程使用的Spark版本是3.3.1。1)上传并解压Spark安装包tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/mv /...
流数据湖平台Apache Paimon(四)集成 Hive 引擎
第3章 集成 Hive 引擎前面与Flink集成时,通过使用 paimon Hive Catalog,可以从 Flink 创建、删除、查询和插入到 paimon 表中。这些操作直接影响相应的Hive元存储。以这种方式创建的表也可以直接从 Hive 访问。更进一步的与 Hive 集成,可以使用 Hiv...
流数据湖平台Apache Paimon(三)Flink进阶使用
2.9 进阶使用2.9.1 写入性能Paimon的写入性能与检查点密切相关,因此需要更大的写入吞吐量:增加检查点间隔,或者仅使用批处理模式。增加写入缓冲区大小。启用写缓冲区溢出。如果您使用固定存储桶模式,请重新调整存储桶数量。2.9.1.1 并行度建议sink的并行度小于等于bucket的数量,最好...

流数据湖平台Apache Paimon(二)集成 Flink 引擎
第2章 集成 Flink 引擎Paimon目前支持Flink 1.17, 1.16, 1.15 和 1.14。本课程使用Flink 1.17.0。2.1 环境准备环境准备2.1.1 安装 Flink1)上传并解压Flink安装包tar -zxvf flink-1.17.0-bin-scala_2.1...
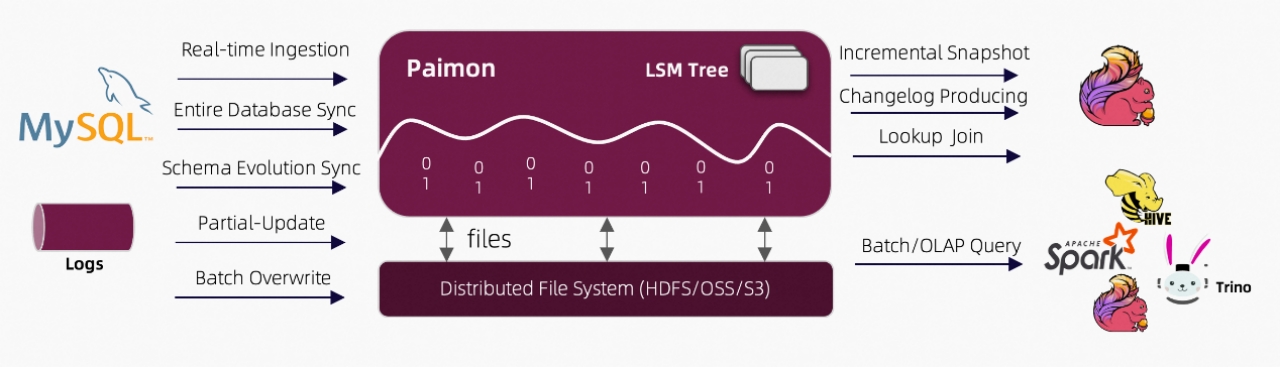
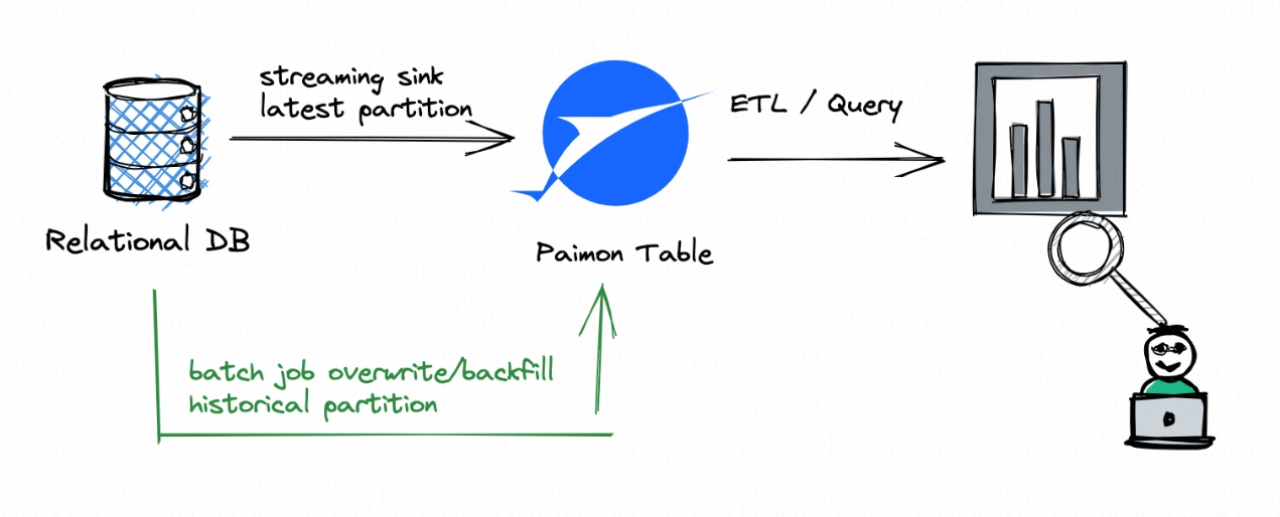
流数据湖平台Apache Paimon(一)概述
第1章 概述1.1 简介Flink 社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。Flink 社区内部...
袋鼠云数据湖平台「DataLake」,存储全量数据,打造数字底座
一、什么是数据湖?在探讨数据湖技术或如何构建数据湖之前,我们需要先明确,什么是数据湖?数据湖的起源,应该追溯到 2010 年 10 月。基于对半结构化、非结构化存储的需求,同时为了推广自家的 Pentaho 产品以及 Hadoop,2010 年 Pentaho 的创始人兼 CTO James Dix...
原生数据湖平台为什么需打通云基础设施?
原生数据湖平台为什么需打通云基础设施?
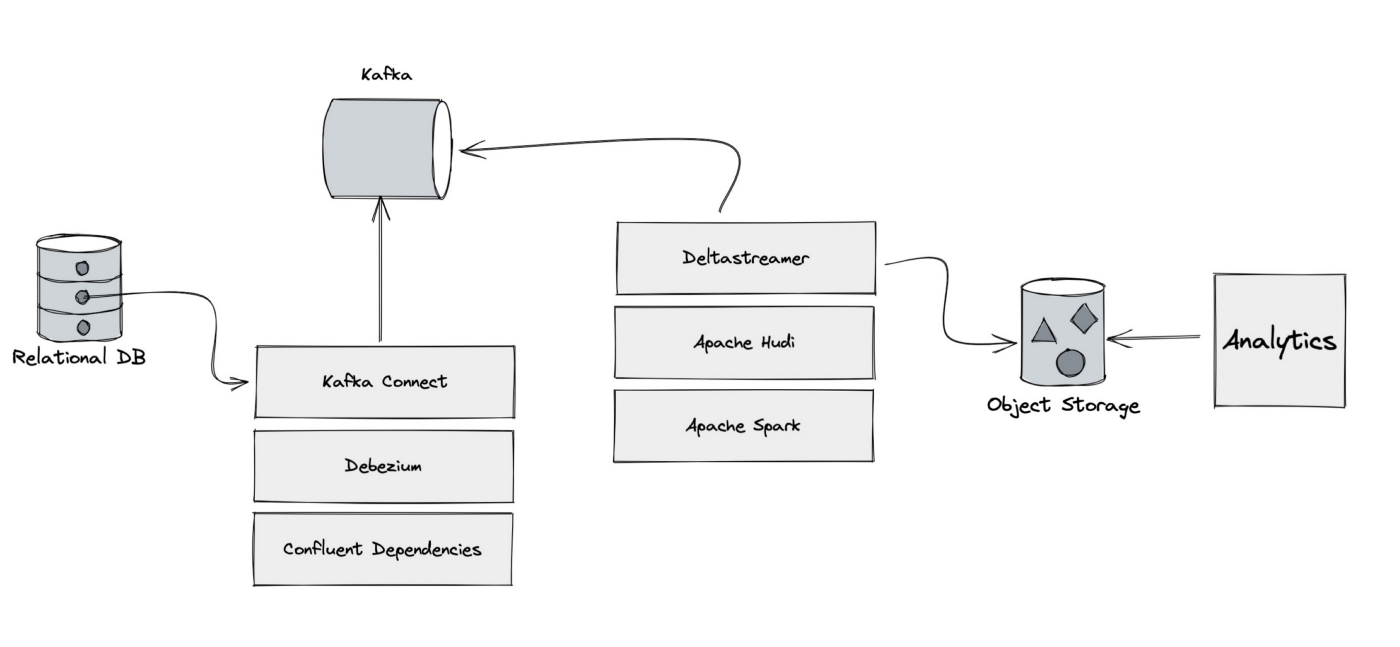
基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品。多年来数据以多种方式存储在计算机中,包括数据库、blob存储和其他方法,为了进行有效的业务分析,必须对现代应...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








