Python使用BeautifulSoup4修改网页内容实战
最近有个小项目,需要爬取页面上相应的资源数据后,保存到本地,然后将原始的HTML源文件保存下来,对HTML页面的内容进行修改将某些标签整个给替换掉。 对于这类需要对HTML进行操作的需求,最方便的莫过于BeautifulSoup4的库了。 样例的HTML代码如下: <html> <...
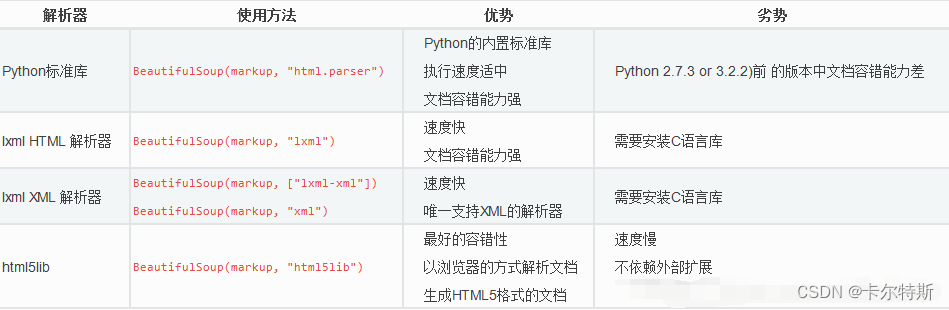
Python BeautifulSoup4 入门使用
一、简介BeautifulSoup4 与 lxml 一样,是一个 html 解析器,主要功能也是解析和提取数据。BeautifulSoup4 是 爬虫 必学的技能。BeautifulSoup 最主要的功能是从网页抓取数据,Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出...

【Python爬虫】Beautifulsoup4中find_all函数
find_all() find_all( name , attrs , recursive , text , **kwargs )find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件.这里有几个例子: soup.find_all("title") #[<tit...
【Python爬虫】用beautifulsoup4库遇到的错误及处理
在这里对使用beautifulsoup时遇到的问题进行汇总。 问题:爬取网页时使用CSS选择器,代码如下,报错 NotImplementedError: Only the following pseudo-classes are implemented: nth-of-type. title = s...

Python beautifulsoup4解析 数据提取 基本使用
Python beautifulsoup4解析 数据提取 使用介绍&常用示例文章目录前言二、from bs4 import BeautifulSoup1.pip install beautifulsoup42.Beautiful用法介绍2.1 解析html源码创建创建Beautifulsou...
python爬虫之BeautifulSoup4遇坑记
#!/usr/bin/python # -*- coding: UTF-8 -*- from urllib import request from bs4 import BeautifulSoup html = request.urlopen("https://movie.douban.com/")...
python爬虫beautifulsoup4系列4-子节点
前言 很多时候我们无法直接定位到某个元素,我们可以先定位它的父元素,通过父元素来找子元素就比较容易 一、子节点 1.以博客园首页的摘要为例:<div class="c_b_p_desc">这个tag为起点 2.那么div这个tag就是父节点 3."摘要: ...
python爬虫beautifulsoup4系列3
前言 本篇手把手教大家如何爬取网站上的图片,并保存到本地电脑 一、目标网站 1.随便打开一个风景图的网站:http://699pic.com/sousuo-218808-13-1.html 2.用firebug定位,打开firepath里css定位目标图片 3.从下图可以看出,所有的图...
python爬虫beautifulsoup4系列2
前言 本篇详细介绍beautifulsoup4的功能,从最基础的开始讲起,让小伙伴们都能入门 一、读取HTML页面 1.先写一个简单的html页面,把以下内容copy出来,保存为html格式文件 <meta charset="UTF-8"> <!-- for HTML...
python爬虫beautifulsoup4系列1
前言 以博客园为例,爬取我的博客上首页的发布时间、标题、摘要,本篇先小试牛刀,先了解下它的强大之处,后面讲beautifulsoup4的详细功能。 一、安装 1.打开cmd用pip在线安装beautifulsoup4 >pip install beautifulsoup4 &nb...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







