请问一个spark任务,之前运行的时间是1个多小时,现在同等量的数据,同样的代码,时间延长了很多,这
请问一个spark任务,之前运行的时间是1个多小时,现在同等量的数据,同样的代码,时间延长了很多,这个是什么原因呢?
Flink 和 Spark Streaming 在时间机制上有什么区别呢?
Flink 和 Spark Streaming 在时间机制上有什么区别呢?

Flink 和Spark Streaming在时间机制上的区别是什么?
Flink 和Spark Streaming在时间机制上的区别是什么?

7月9日Spark社区直播【通过LLVM加速SparkSQL时间窗口计算】
讲师: 王太泽第四范式特征工程数据库负责人曾在百度担任资深研发工程师一直致力于解决机器学习模型从离线到在线特征一致性问题和性能问题。 时间: 7月9日 19:00 观看直播方式: 扫描下方二维码入群,或届时进入直播间(回看链接)https://developer.aliyun.com/live/43...

【译】Apache Spark 数据建模之时间维度(二)
编译:诚历,阿里巴巴计算平台事业部 EMR 技术专家,Apache Sentry PMC,Apache Commons Committer,目前从事开源大数据存储和优化方面的工作。 原文链接 :http://blog.madhukaraphatak.com/data-modeling-spark-p...
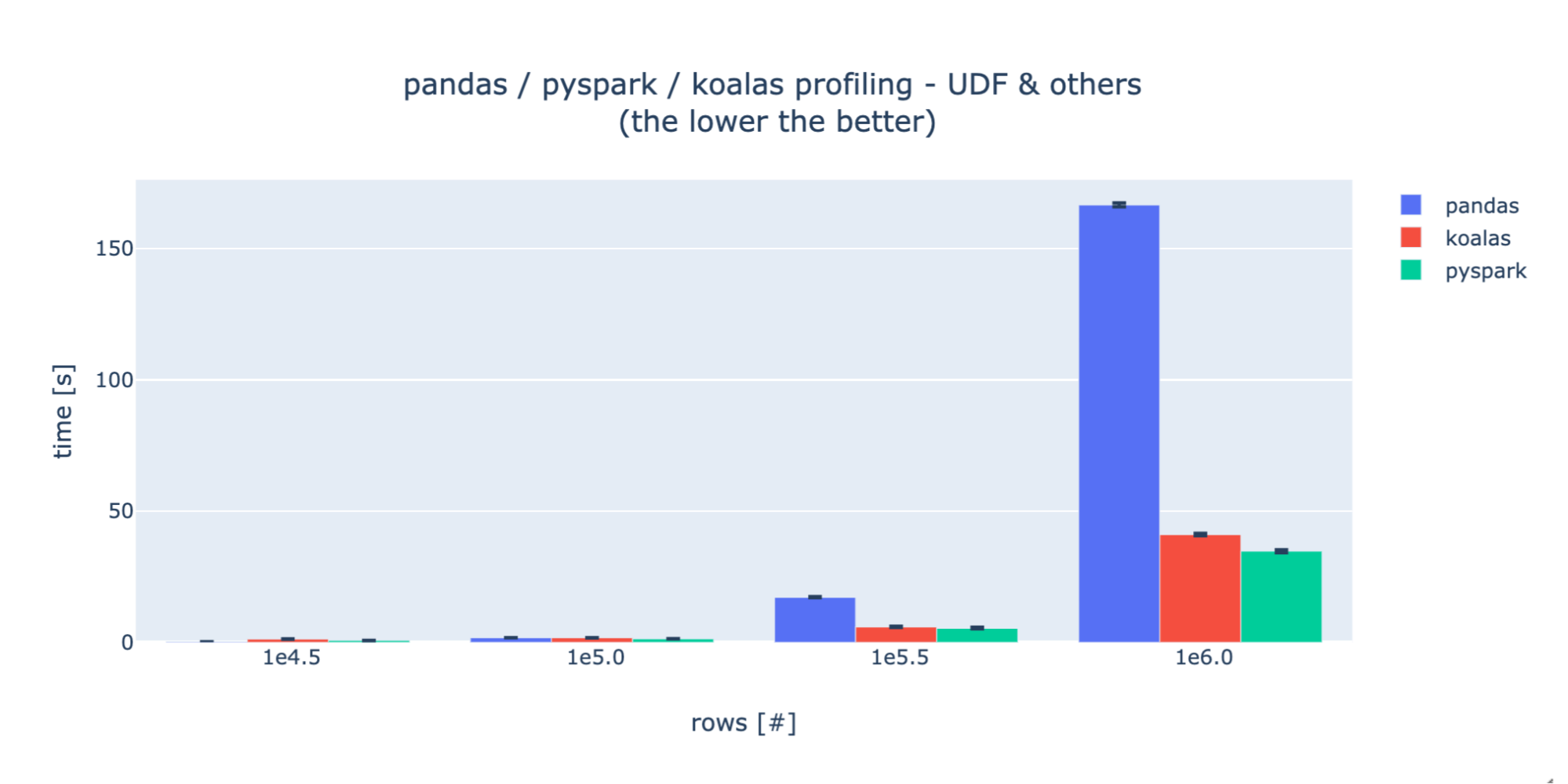
Virgin Hyperloop One如何使用Koalas将处理时间从几小时降到几分钟--无缝的将pandas切换成Apache Spark指南
编译:杨强,花名元战,阿里巴巴高级技术专家。 Virgin Hyperloop One(超级高铁公司)是一家从事超级高铁研究的公司,致力于能让高铁达到飞机的速度并且拥有更低的成本。为了能够制造一个商业的系统,我们需要收集并且分析非常大量的各种不同的数据,包括各种运行测试数据,多种模拟数据,技术设施数...
Virgin Hyperloop One如何使用Koalas将处理时间从几小时降到几分钟--无缝的将pandas切换成Apache Spark指南
Virgin Hyperloop One(超级高铁公司)是一家从事超级高铁研究的公司,致力于能让高铁达到飞机的速度并且拥有更低的成本。为了能够制造一个商业的系统,我们需要收集并且分析非常大量的各种不同的数据,包括各种运行测试数据,多种模拟数据,技术设施数据,甚至社会经济数据等等。我们之前绝大部分处理...
使用Spark Streaming SQL基于时间窗口进行数据统计
作者:关文选,花名云魄,阿里云E-MapReduce 高级开发工程师,专注于流式计算,Spark Contributor 1.背景介绍 流式计算一个很常见的场景是基于事件时间进行处理,常用于检测、监控、根据时间进行统计等系统中。比如埋点日志中每条日志记录了埋点处操作的时间,或者业务系统中记录了用户操...
使用Spark Streaming SQL基于时间窗口进行数据统计
1.背景介绍 流式计算一个很常见的场景是基于事件时间进行处理,常用于检测、监控、根据时间进行统计等系统中。比如埋点日志中每条日志记录了埋点处操作的时间,或者业务系统中记录了用户操作时间,用于统计各种操作处理的频率等,或者根据规则匹配,进行异常行为检测或监控系统告警。这样的时间数据都会包含在事件数据中...
当Spark在S3上读取大数据集时,在“停机时间”期间发生了什么?
我在AWS S3中有一堆JSON数据 - 让我们说100k文件,每个大约5MB - 我正在使用Spark 2.2 DataFrameReader来读取和处理它们:sparkSession.read.json(...)我发现Spark在开始计算之前只会挂起5分钟左右。对于较大的数据集,这可能需要数小时...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作