Spark 缓存和检查点机制
Spark 缓存和检查点是提高 Spark 性能的两个重要机制。 Spark 缓存机制 Spark 支持将RDD数据缓存在内存中,在后续的操作中直接使用缓存中的数据,避免了重复计算和频繁读写磁盘的开销。Spark 缓存机制主要包括以下几种方法: persist() 和 cache():手动对RDD进...

Spark之Shuffle机制及其文件寻址详解
Spark之Shuffle机制及其文件寻址详解一、SparkShuffle概念Certain operations within Spark trigger an event known as the shuffle. The shuffle is Spark’s mechanism for re-...

Spark是基于什么来计算的机制呢?
Spark是基于什么来计算的机制呢?
Spark的惰性机制是什么?
Spark的惰性机制是什么?
Hadoop和Spark在执行机制方面有什么不同呢?
Hadoop和Spark在执行机制方面有什么不同呢?

Spark的YARN模式运行机制
YARN Client模式在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动Appl...
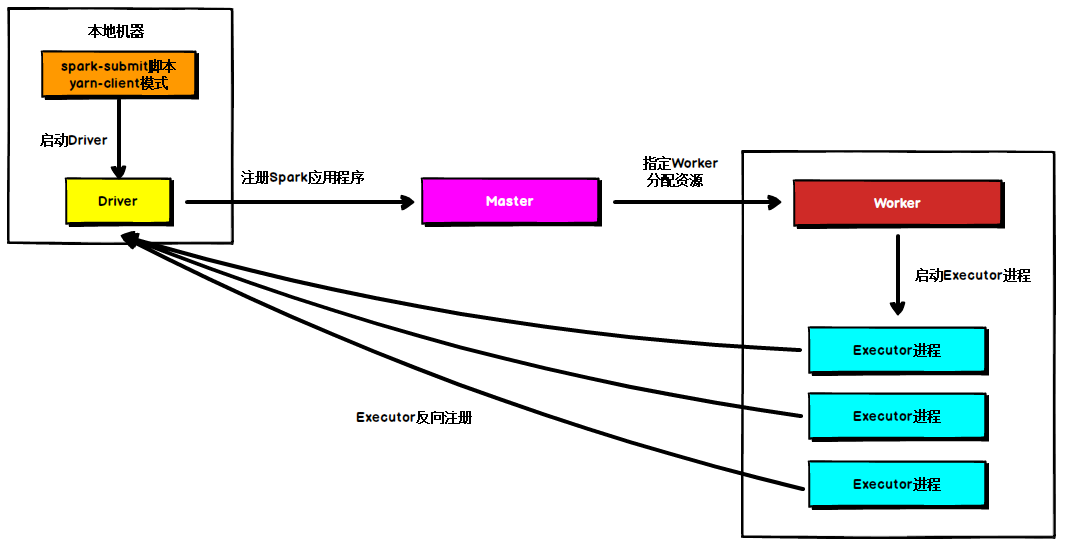
Spark的Standalone模式运行机制
Standalone集群有四个重要组成部分,分别是:Driver:是一个进程,我们编写的Spark应用程序就运行在Driver上,由Driver进程执行;Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责; 资源分配方式: 尽量集中 尽量打散Worker(NM):是一...
Spark Streaming之容错机制
一、容错机制的背景要理解Spark Streaming提供的容错机制,先回忆一下Spark RDD的基础容错语义:RDD,Ressilient Distributed Dataset,是不可变的、确定的、可重新计算的、分布式的数据集。每个 RDD都会记住确定好的计算操作的血缘关系,这些操作应用在 一...
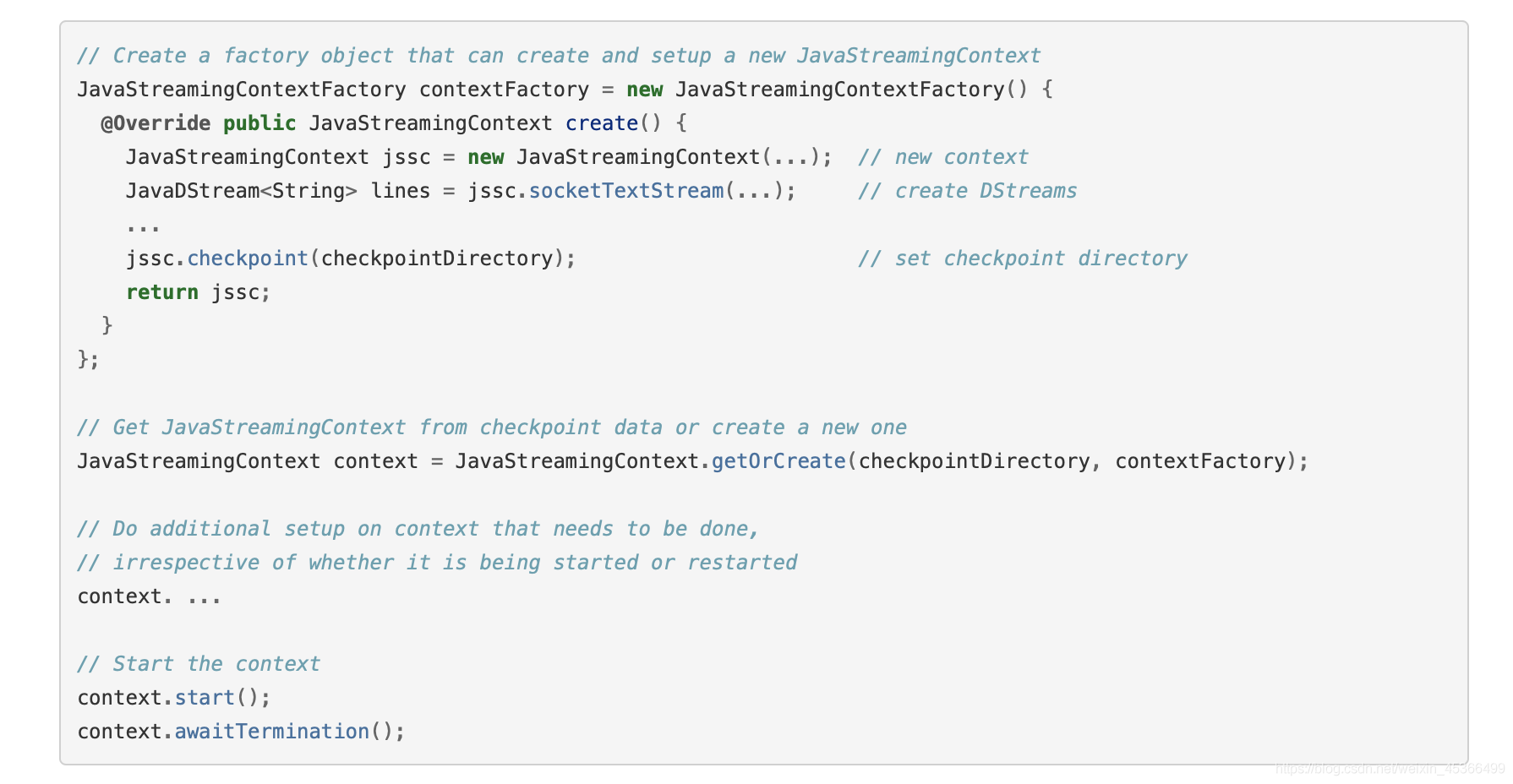
Spark Streaming之checkpoint机制
一、checkpoint机制每一个Spark Streaming应用,正常来说,都是要7 * 24小时运转的,这就是实时计算程序的特点。因为要持续 不断的对数据进行计算。因此,对实时计算应用的要求,应该是必须要能够对与应用程序逻辑无关的失败,进行 容错。如果要实现这个目标,Spark Streami...
Flink 的 checkpoint 机制对比 spark 有到底什么不同和优势?
Flink 的 checkpoint 机制对比 spark 有到底什么不同和优势?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作