[帮助文档] Kafka自定义连接器提供的可观测性能力及错误排查步骤
本文介绍Kafka自定义连接器提供的可观测性能力及错误排查步骤。
大佬们,我flink 采用 upsert-kafka作为连接器建表(t1),数据中具有相同更新时间的
大佬们,我flink 采用 upsert-kafka作为连接器建表(t1),数据中具有相同更新时间的多条数据,查询t1表,数据取的是哪条呢

请问kafka 连接器创建kafka source表时配置参数'topic-pattern'='(e
请问kafka 连接器创建kafka source表时配置参数'topic-pattern'='(empty)|(student)',如果正则中的部分topic未创建,此时job运行后,后续创建的topic会被消费吗?或者有什么办法能在任务运行后,将后续创建的,同时能被正则匹配的topic,也被运行...
请问,我这边设置了upsert-kafka 连接器,,为啥读取出来的 主键 没有更新呢,偏移量还是增
请问,我这边设置了upsert-kafka 连接器,,为啥读取出来的 主键 没有更新呢,偏移量还是增长呢,读取的条数还是那么多?
【源码解读】Flink-Kafka连接器自定义序列器和分区器
@TOC开篇导语Flink将数据sink至Kafka的过程中,在初始化生产者对象FlinkKafkaProducer时通常会采用默认的分区器和序列化器,这样数据只会发送至指定Topic的某一个分区中。对于存在多分区的Topic我们一般要自定义分区器和序列化器,指定数据发送至不同分区的逻辑。此篇博客所...
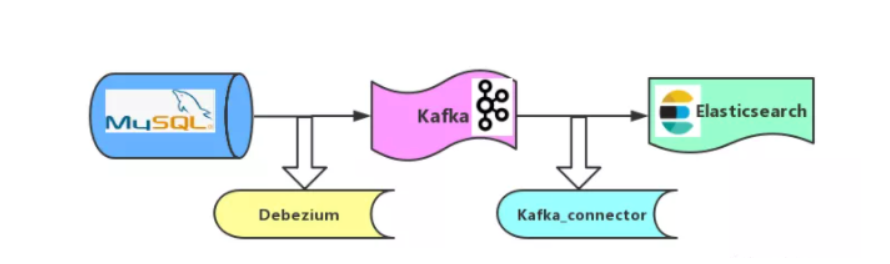
kafka 连接器实现 Mysql 数据同步 Elasticsearch
为什么需要将 Mysql 数据同步到 ElasticsearchMysql 作为传统的关系型数据库,主要面向 OLTP,性能优异,支持事务,但是在一些全文检索,复杂查询上面并不快。Elasticsearch 底层基于 Lucense 实现,天然分布式,采用倒排索引存储数据,全文检索效率...
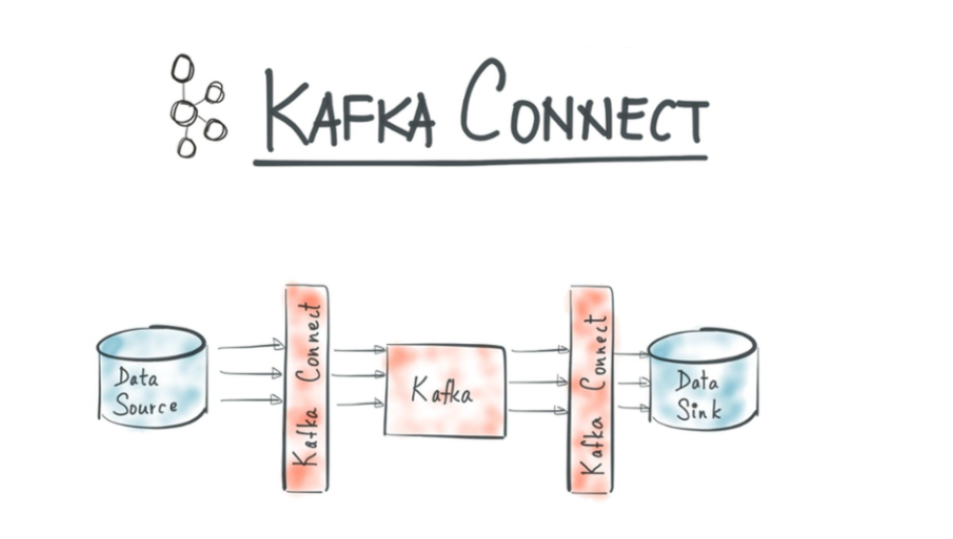
Kafka 连接器使用与开发
Kafka 连接器介绍Kafka 连接器通常用来构建数据管道,一般有两种使用场景:开始和结束的端点:例如,将 Kafka 中的数据导出到 HBase 数据库,或者把 Oracle 数据库中的数据导入 Kafka 中。数据传输的中间介质:例如,为了把海量的日志数据存储到 Elasticsearch 中...
kafka中连接器API的作用是什么?
kafka中连接器API的作用是什么?
Flink 的 kafka 连接器有那些独特的地方?
Flink 的 kafka 连接器有那些独特的地方?
Flink 的 kafka 连接器有什么独特的地方?
Flink 的 kafka 连接器有什么独特的地方?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子




云消息队列 Kafka 版连接器相关内容
云消息队列 Kafka 版您可能感兴趣
- 云消息队列 Kafka 版存储
- 云消息队列 Kafka 版数据
- 云消息队列 Kafka 版延迟
- 云消息队列 Kafka 版rabbitmq
- 云消息队列 Kafka 版区别
- 云消息队列 Kafka 版线程
- 云消息队列 Kafka 版性能
- 云消息队列 Kafka 版模型
- 云消息队列 Kafka 版分区
- 云消息队列 Kafka 版监控
- 云消息队列 Kafka 版flink
- 云消息队列 Kafka 版cdc
- 云消息队列 Kafka 版消费
- 云消息队列 Kafka 版集群
- 云消息队列 Kafka 版mysql
- 云消息队列 Kafka 版配置
- 云消息队列 Kafka 版同步
- 云消息队列 Kafka 版报错
- 云消息队列 Kafka 版apache
- 云消息队列 Kafka 版消息队列
- 云消息队列 Kafka 版安装
- 云消息队列 Kafka 版topic
- 云消息队列 Kafka 版消息
- 云消息队列 Kafka 版sql
- 云消息队列 Kafka 版入门
- 云消息队列 Kafka 版消费者
- 云消息队列 Kafka 版原理
- 云消息队列 Kafka 版实战