
大数据开发!Pandas转spark无痛指南!⛵
作者:韩信子@ShowMeAI 大数据技术◉技能提升系列:https://www.showmeai.tech/tutorials/84 数据分析实战系列:https://www.showmeai.tech/tutorials/40 本文地址:https://www.showmeai.tech/art...

SQL、Pandas和Spark:如何实现数据透视表?
01 数据透视表简介数据透视表,顾名思义,就是通过对数据执行一定的"透视",完成对复杂数据的分析统计功能,常常伴随降维的效果。例如在Excel工具栏数据透视表选项卡中通过悬浮鼠标可以看到这样的描述:在上述简介中,有两个关键词值得注意:排列和汇总,其中汇总意味着要产生聚合...


SQL、Pandas、Spark:窗口函数的3种实现
模拟问题描述:给定一组中学生的历次语文月考成绩表(每名学生含有4次成绩),需要实现以下3个需求:对每名学生的4次成绩表分别进行排序,排序后每人的成绩排名1-2-3-4求每名学生历次月考成绩的变化幅度,即本月较上个月的成绩差值求每名学生历次月考成绩中近3次平均分数据表样例如下:01 窗口...

SQL、Pandas和Spark:常用数据查询操作对比
本文首先介绍SQL查询操作的一般流程,对标SQL查询语句的各个关键字,重点针对Pandas和Spark进行介绍,主要包括10个常用算子操作。01 SQL标准查询谈到数据,必会提及数据库;而提及数据库,则一般指代关系型数据库(R DB),操作关系型数据库的语言则是SQL&#...

Pandas vs Spark:获取指定列的N种方式
无论是pandas的DataFrame还是spark.sql的DataFrame,获取指定一列是一种很常见的需求场景,获取指定列之后可以用于提取原数据的子集,也可以根据该列衍生其他列。在两个计算框架下,都支持了多种实现获取指定列的方式,但具体实现还是有一定区别的。01 pd.DataFrame获取指...

Pandas vs Spark:数据读取篇
数据读取是所有数据处理分析的第一步,而Pandas和Spark作为常用的计算框架,都对常用的数据源读取内置了相应接口。总体而言,数据读取可分为从文件读取和从数据库读取两大类,其中数据库读取包含了主流的数据库,从文件读取又区分为不同的文件类型。基于此,本文首先分别介绍Pandas和Spark常用的数据...
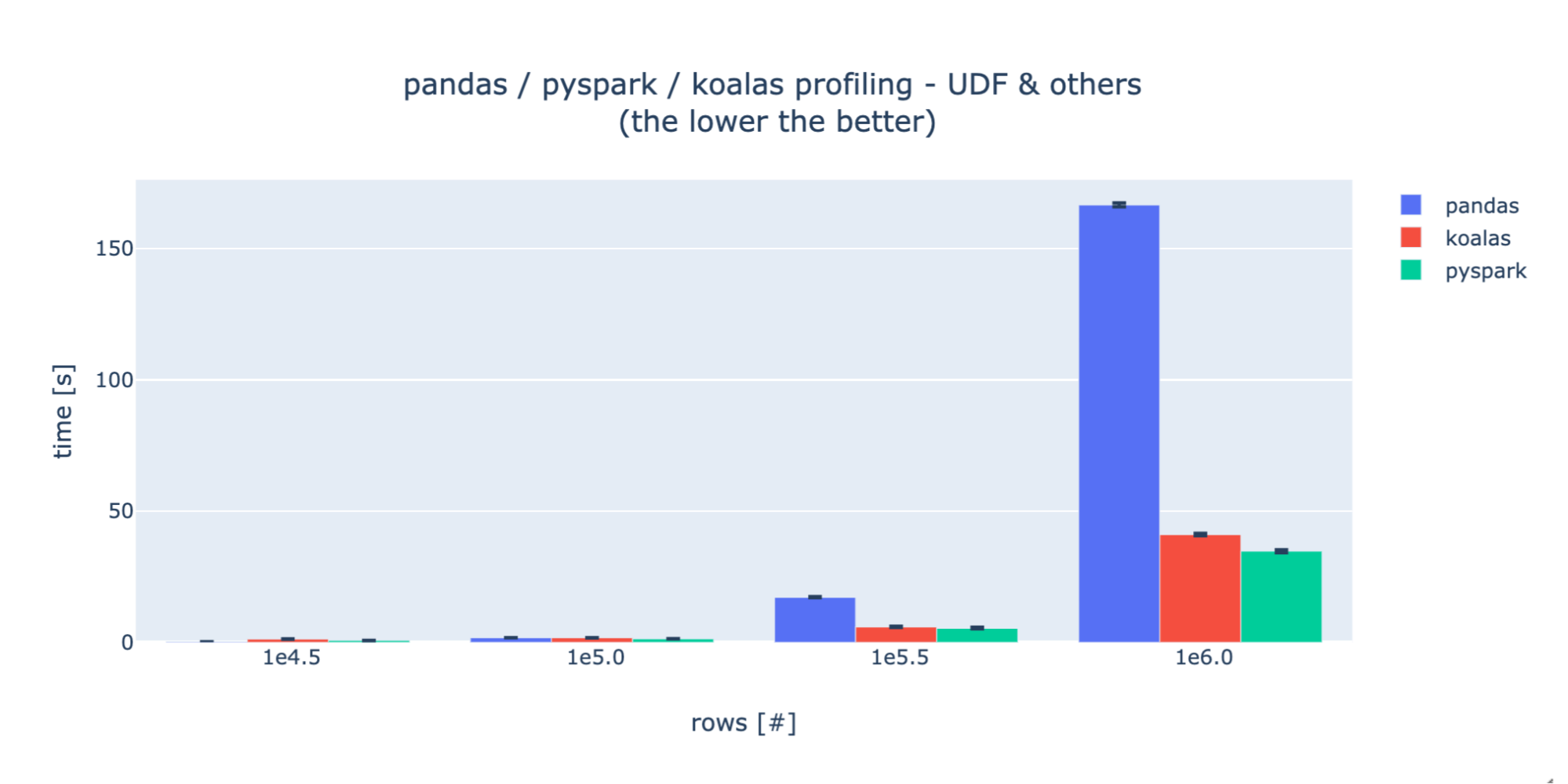
Virgin Hyperloop One如何使用Koalas将处理时间从几小时降到几分钟--无缝的将pandas切换成Apache Spark指南
编译:杨强,花名元战,阿里巴巴高级技术专家。 Virgin Hyperloop One(超级高铁公司)是一家从事超级高铁研究的公司,致力于能让高铁达到飞机的速度并且拥有更低的成本。为了能够制造一个商业的系统,我们需要收集并且分析非常大量的各种不同的数据,包括各种运行测试数据,多种模拟数据,技术设施数...
Virgin Hyperloop One如何使用Koalas将处理时间从几小时降到几分钟--无缝的将pandas切换成Apache Spark指南
Virgin Hyperloop One(超级高铁公司)是一家从事超级高铁研究的公司,致力于能让高铁达到飞机的速度并且拥有更低的成本。为了能够制造一个商业的系统,我们需要收集并且分析非常大量的各种不同的数据,包括各种运行测试数据,多种模拟数据,技术设施数据,甚至社会经济数据等等。我们之前绝大部分处理...
Koalas:让 pandas 轻松切换 Apache Spark
4 月 24 日,Databricks 在 Spark + AI 峰会上开源了一个新产品 Koalas,它增强了 PySpark 的 DataFrame API,使其与 pandas 兼容。 Python 数据科学在过去几年中爆炸式增长, pandas 已成为生态系统的关键。当数据科学家得到一个数据...
有没有办法优化使用pandas读取TSV文件,转换并使用spark写入表的代码?
df_pandas = pd.read_csv('filepath/filename' , delimiter='t' , encoding = 'utf-8', error_bad_lines=False ) #defining the schema for the spark dataframe...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。


