Hadoop生态系统中的流式数据处理技术:Apache Flink和Apache Spark的比较
Hadoop生态系统中的流式数据处理技术:Apache Flink和Apache Spark的比较 引言:在大数据时代,处理海量的实时数据变得愈发重要。Hadoop生态系统中的两个主要的流式数据处理框架,Apache Flink和Apache Spark,都提供了强大的功能来应对这一挑战。本文将对这...
流式读取热搜词汇并解析,urllib+Kafka+Spark
环境必备上文有部分配置信息,此处不再赘述。使用python+spark爬取百度热搜写入mysql首先肯定是jdk,这里选用的1.8,因为高版本的时候,kafka会报一个高版本的错误,同时安装spark,kafka,zookeeper,安装mysql以及下载jdbc的包ÿ...


图解大数据 | Spark Streaming @流式数据处理
作者:韩信子@ShowMeAI教程地址:http://www.showmeai.tech/tutorials/84本文地址:http://www.showmeai.tech/article-detail/179声明:版权所有,转载请联系平台与作者并注明出处收藏ShowMeAI查看更多精彩内容1.Sp...
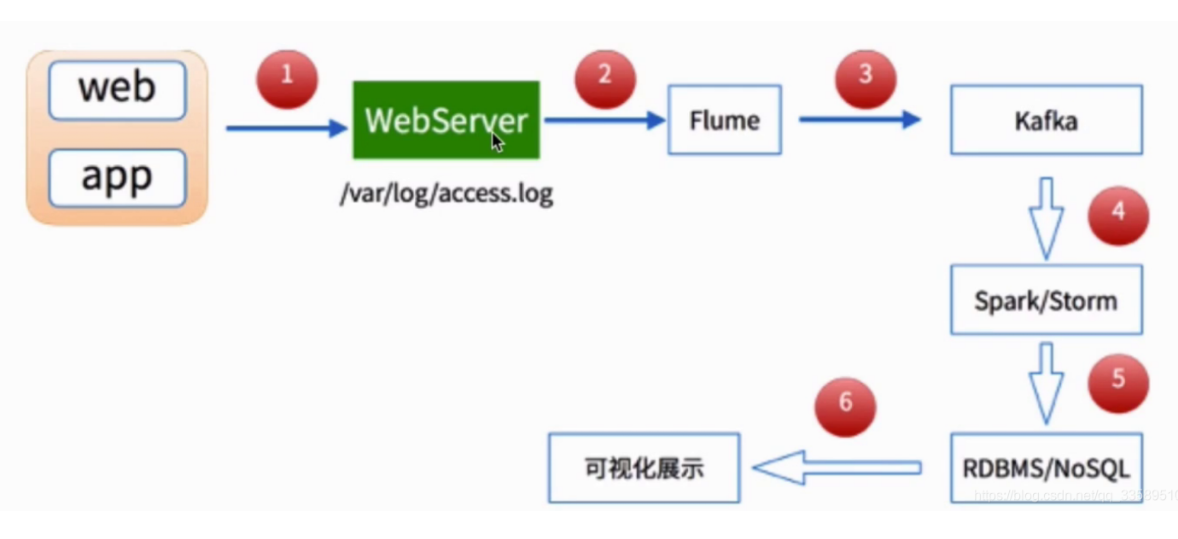
Spark Sreaming实战(二)-小试流式处理
1 业务分析1.1 需求统计主站每个(指定)教程访问的客户端、地域信息分布地域: ip转换 Spark SQL项目实战客户端:useragent获取 Hadoop基础教程=》如上两个操作:采用离线(Spark/MapReduce )的方式进行统计1.2 实现步骤课程编号、ip信息、useragent...
spark odps流式读取datahub数据,写到odps有没有参考文档或者代码?
spark odps流式读取datahub数据,写到odps有没有参考文档或者代码?
【观察】常用的流式框架(二)-- Spark与Flink
Spark由加州大学伯克利分校于2009年开发,第二年开源,2014年成为Apache顶级项目。作为MapReduce的继任者,Spark可以提供高水准API(如RDD--可恢复分布式数据集;Dstream--离散无序的RDD),其社区在2015年就有超过1000名贡献者,知名的用户包括亚马逊、eB...
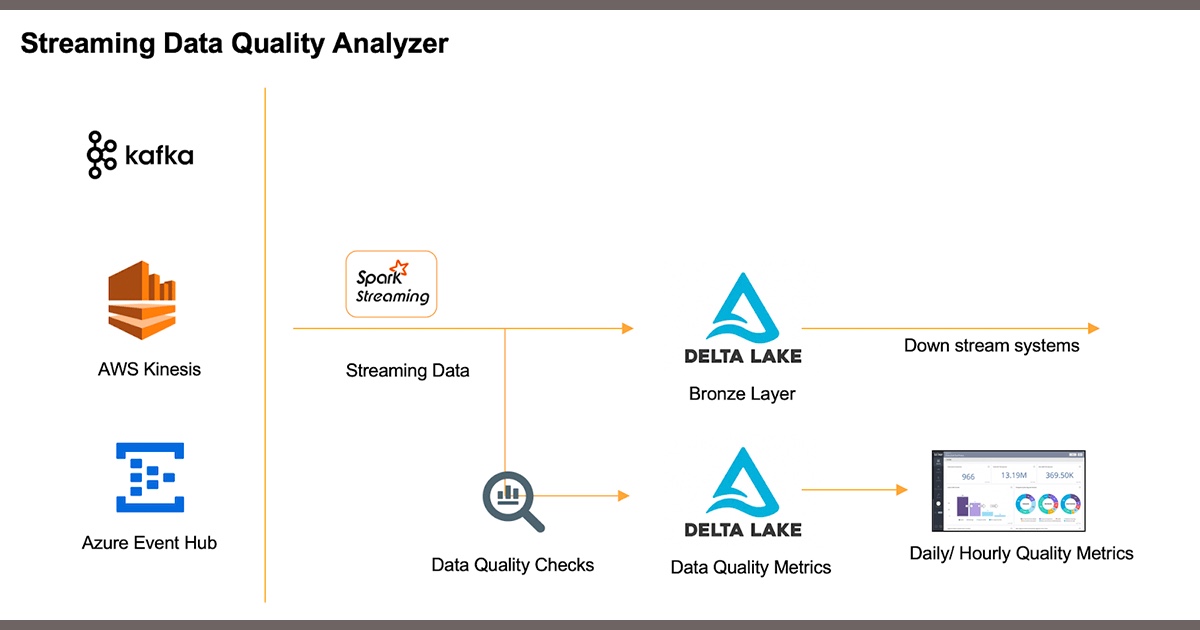
【译】Databricks使用Spark Streaming和Delta Lake对流式数据进行数据质量监控介绍
原文链接:https://databricks.com/blog/2020/03/04/how-to-monitor-data-stream-quality-using-spark-streaming-and-delta-lake.html 在这个一切都需要进行加速的时代,流数据的使用变得越来越普遍...

8月28日社区直播【Spark Streaming SQL流式处理简介】
直播间直达链接:(回看链接) https://developer.aliyun.com/live/1408?spm=5176.8068049.0.0.1ea56d19o3DBMN 或钉钉扫描海报上二维码,进群直接观看。 时间 8月28日19:00 主讲人: 云魄,阿里云E-MapReduce 高级开...
8月28日社区直播【Spark Streaming SQL流式处理简介】
直播间直达链接:(回看链接) https://tianchi.aliyun.com/course/live?liveId=41084 或钉钉扫描海报上二维码,进群直接观看。 时间 8月28日19:00 主讲人: 云魄,阿里云E-MapReduce 高级开发工程师,专注于流式计算,Spark Cont...
使用Spark SQL进行流式机器学习计算(上)
作者:余根茂,阿里巴巴计算平台事业部EMR团队的技术专家,参与了Hadoop,Spark,Kafka等开源项目的研发工作。目前主要专注于EMR流式计算产品的研发工作。 今天来和大家聊一下如何使用Spark SQL进行流式数据的机器学习处理。本文主要分为以下几个章节: 什么是流式机器学习 机器学习模型...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作