Java网络爬虫实践:解析微信公众号页面的技巧
在当今数字化时代,信息获取已经成为了一项至关重要的任务。然而,随着信息量的爆炸性增长,人工处理这些信息已经变得不太现实。这时候,网络爬虫就成为了一种强大的工具,能够帮助我们从海量的网页中快速准确地获取所需信息。而在Java领域,网络爬虫的实现更是多种多样,今天我将和大家分享一些在解析微信公众号页面时...
python爬虫示例,获取主页面链接,次级页面链接通过主页面元素获取从而避免js生成变动的值,保存数据分批次避免数据丢失
# -*- coding: utf-8 -*- # import scrapy import pandas as pd from math import ceil import re import requests import re from bs4 import BeautifulSoup fr...

爬虫识别-关键页面最小访问间隔-需求及思路|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-关键页面最小访问间隔-需求及思路】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/lear...
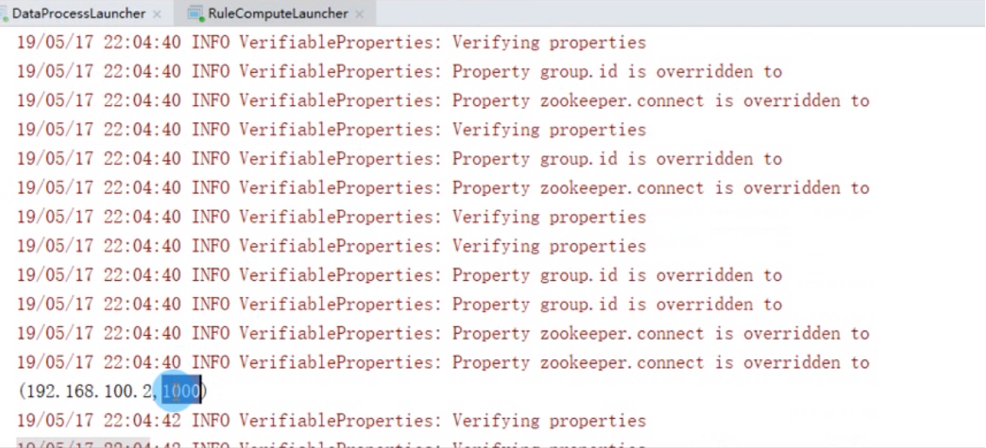
爬虫识别-关键页面最小访问间隔-效果及总结|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-关键页面最小访问间隔-效果及总结】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/lear...
爬虫识别-关键页面最小访问间隔-下|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-关键页面最小访问间隔-下】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning...
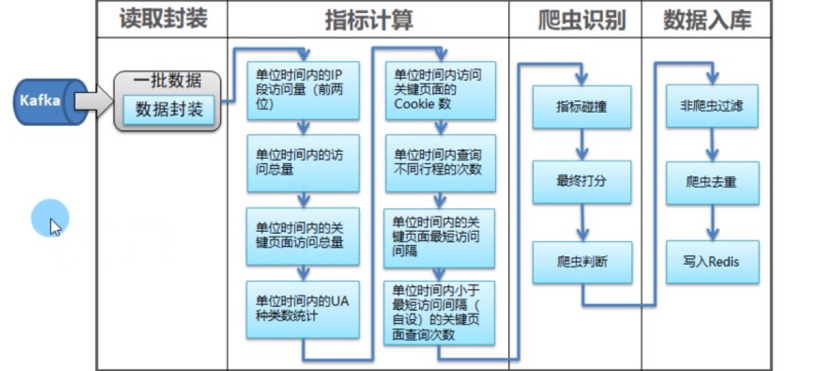
爬虫识别-关键页面数据读取|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-关键页面数据读取】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/cou...

爬虫识别-关键页面访问量-需求及实现思路|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-关键页面访问量-需求及实现思路】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learn...
爬虫识别-关键页面访问量-实现代码及效果|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-关键页面访问量-实现代码及效果】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learn...

爬虫识别-关键页面的 cook 统计-需求及思路|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-关键页面的 cook 统计-需求及思路】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/l...
爬虫识别-关键页面的 cook 统计-代码实现及效果|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-关键页面的 cook 统计-代码实现及效果】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


