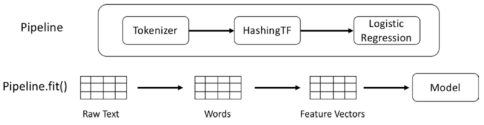
Spark机器学习管道 - Pipeline
一、实验目的掌握使用Spark机器学习管道创建小型机器学习工作流。二、实验内容1、构建一个机器学习管道,应用LogisticRegression算法,预测一行文本中是否出现了”spark”这个单词。三、实验原理Spark ML有一个名为Pipeline的类,它被设计用来管理一系列的阶段,每一个阶段都...

Spark机器学习管道 - Estimator
一、实验目的掌握Spark机器学习管道中常用Estimator的使用。二、实验内容1、使用IDF estimator,计算每个单词的重要性。 2、使用StringIndexer estimator来对电影类型进行编码。 3、使用OneHotEncoderEstimator e...


Spark机器学习管道 - Transformer
一、实验目的掌握Spark机器学习管道中常用Transformer的使用。二、实验内容1、应用Binarizer transformer,将连续值变量转换为两个离散的值。 2、使用Bucketizer transformer将温度列放入三个桶中,输出按温度列排序。 3、使用O...
将spark feature转换管道导出到文件
PMML,Mleap,PFA目前仅支持基于行的转换。它们都不支持基于帧的转换,如聚合或groupby或join。导出由这些操作组成的spark管道的推荐方法是什么?
【Spark Summit East 2017】在AdTech使用Spark对于产品管道进行研发
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。 本讲义出自Maximo Gurmendez , Sa...
【Spark Summit East 2017】基于Spark ML和GraphFrames的大规模文本分析管道
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。 本讲义出自Alexey Svyatkovskiy在S...
【Spark Summit East 2017】管道泄漏问题:像女士一样在大数据中做个的标记
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。 本讲义出自Kavitha Mariappan在Spa...
【Spark Summit East 2017】 使用Kafka Connect和Spark Streaming构建实时数据管道
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。 本讲义出自Ewen Cheslack Postava...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark分析
- apache spark数据
- apache spark数据库
- apache spark可视化分析
- apache spark决策
- apache spark可视化
- apache spark Mapreduce
- apache spark SQL
- apache spark Python
- apache spark决策树
- apache spark streaming
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark任务
- apache spark程序