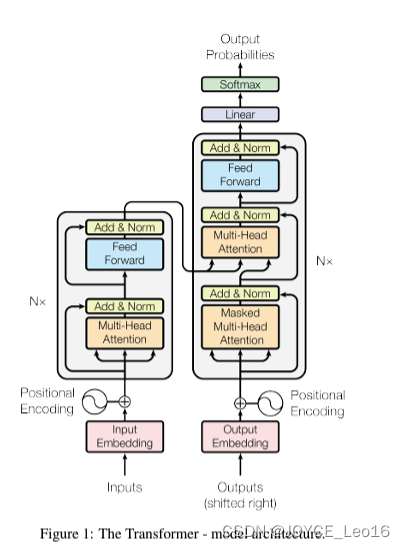
深度学习中的稀疏注意力
一、稀疏注意力的特点 DeepSpeed有很多不错的功能:Training Overview and Features - DeepSpeed 其中有一个功能是注意力稀疏,我们重点展开说明。 需要注意的是:稀疏注意力的实现并不仅限于DeepSpeed。虽然DeepSpeed提供了一种高效的稀疏注意力...
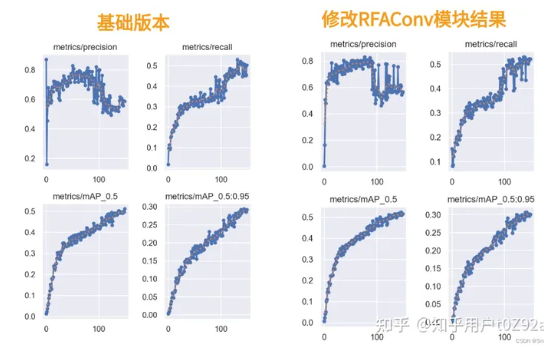
YOLOv5改进 | 卷积篇 | 通过RFAConv重塑空间注意力(深度学习的前沿突破)
一、本文介绍 本文给大家带来的改进机制是RFAConv,全称为Receptive-Field Attention Convolution,是一种全新的空间注意力机制。与传统的空间注意力方法相比,RFAConv能够更有效地处理图像中的细节和复杂模式(适用于所有的检测对象都有一定的提点)。这不仅让YOL...

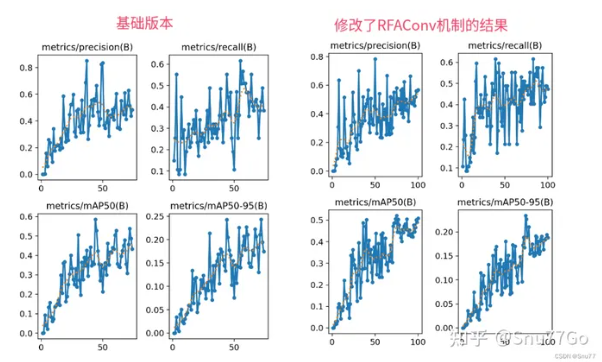
YOLOv8改进 | 2023 | 通过RFAConv重塑空间注意力(深度学习的前沿突破)
一、本文介绍 本文给大家带来的改进机制是RFAConv,全称为Receptive-Field Attention Convolution,是一种全新的空间注意力机制。与传统的空间注意力方法相比,RFAConv能够更有效地处理图像中的细节和复杂模式(适用于所有的检测对象都有一定的提点)。这不仅让YOL...
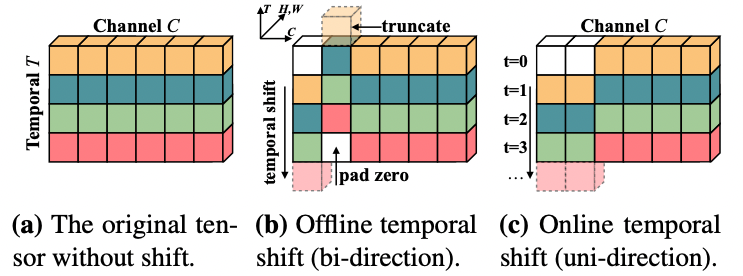
深度学习应用篇-计算机视觉-视频分类8:时间偏移模块(TSM)、TimeSformer无卷积视频分类方法、注意力机制
深度学习应用篇-计算机视觉-视频分类[8]:时间偏移模块(TSM)、TimeSformer无卷积视频分类方法、注意力机制 1.时间偏移模块(TSM) 视频流的爆炸性增长为以高精度和低成本执行视频理解任务带来了挑战。传统的2D CNN计算成本低,但无法捕捉视频特有的时间信息;3D CNN可以得到良好的...
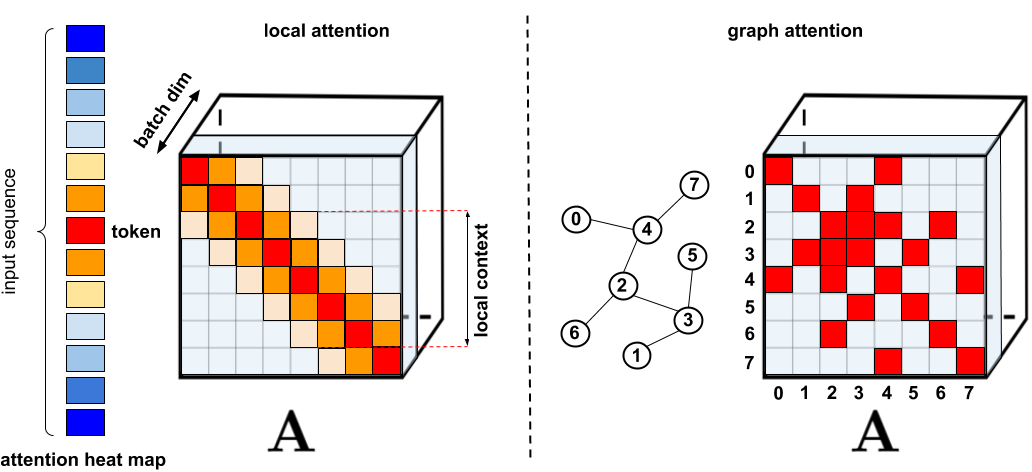
深度学习进阶篇7:Transformer模型长输入序列、广义注意力、FAVOR+快速注意力、蛋白质序列建模实操。
深度学习进阶篇[7]:Transformer模型长输入序列、广义注意力、FAVOR+快速注意力、蛋白质序列建模实操。 基于Transformer模型在众多领域已取得卓越成果,包括自然语言、图像甚至是音乐。然而,Transformer架构一直以来为人所诟病的是其注意力模块的低效,即长度二次依赖限制问题...

「深度学习注意力机制 」TKDE 2022研究综述
【新智元导读】注意力机制(Attention Mechanism)是深度学习中常用的模块,作为一种资源分配方案,将有限的计算资源用来处理更重要的信息,是解决信息超载问题的主要手段。下面这篇是来自Erasmus University的Gianni Brauwers和Flavius Frasincar在...
深度学习基础入门篇[六(1)]:模型调优:注意力机制[多头注意力、自注意力],正则化【L1、L2,Dropout,Drop Connect】等
深度学习基础入门篇[六(1)]:模型调优:注意力机制[多头注意力、自注意力],正则化【L1、L2,Dropout,Drop Connect】等1.注意力机制在深度学习领域,模型往往需要接收和处理大量的数据,然而在特定的某个时刻,往往只有少部分的某些数据是重要的,这种情况就非常适合Attention机...
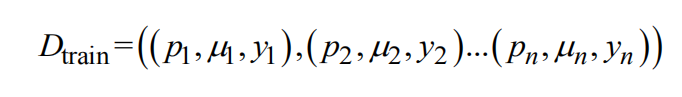
深度学习简化总结合注意力与循环神经网络推荐的算法
1、简介互联网将全球信息互连形成了信息时代不可或缺的基础信息平台,其中知识分享服务已经成为人们获取信息的主要工具。为了加快互联网知识共享,出现了大量以知乎为代表的问答社区[1] 。用户注册社区后可交互式提出与回答问题达到知识共享和交换。然而,伴随用户急剧增多,平台短时间内积攒了数目巨大、类型多样的问...

动手学深度学习(十四) NLP注意力机制和Seq2seq模型(下)
引入注意力机制的Seq2seq模型本节中将注意机制添加到sequence to sequence 模型中,以显式地使用权重聚合states。下图展示encoding 和decoding的模型结构,在时间步为t的时候。此刻attention layer保存着encodering看到的所有信息——即en...
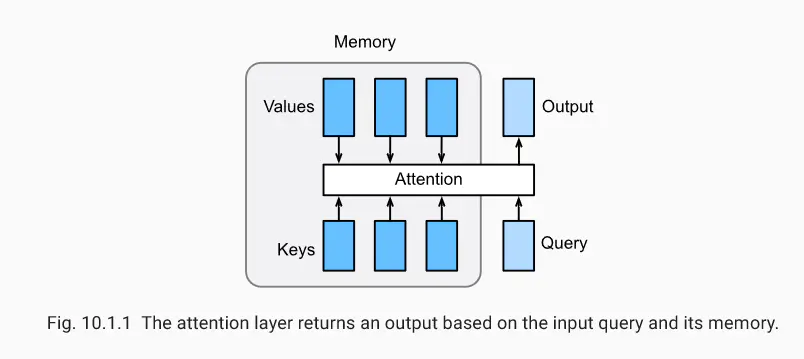
动手学深度学习(十四) NLP注意力机制和Seq2seq模型(上)
注意力机制在“编码器—解码器(seq2seq)”⼀节⾥,解码器在各个时间步依赖相同的背景变量(context vector)来获取输⼊序列信息。当编码器为循环神经⽹络时,背景变量来⾃它最终时间步的隐藏状态。将源序列输入信息以循环单位状态编码,然后将其传递给解码器以生成目标序列。然而这种结构存在着问题...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子



最佳实践


