![深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解](https://ucc.alicdn.com/fnj5anauszhew_20230526_a8ef174625f448c29fd038a273cbb6e5.png)
深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解
深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解 1.XLNet:Generalized Autoregressive Pretraining for Language Understan...
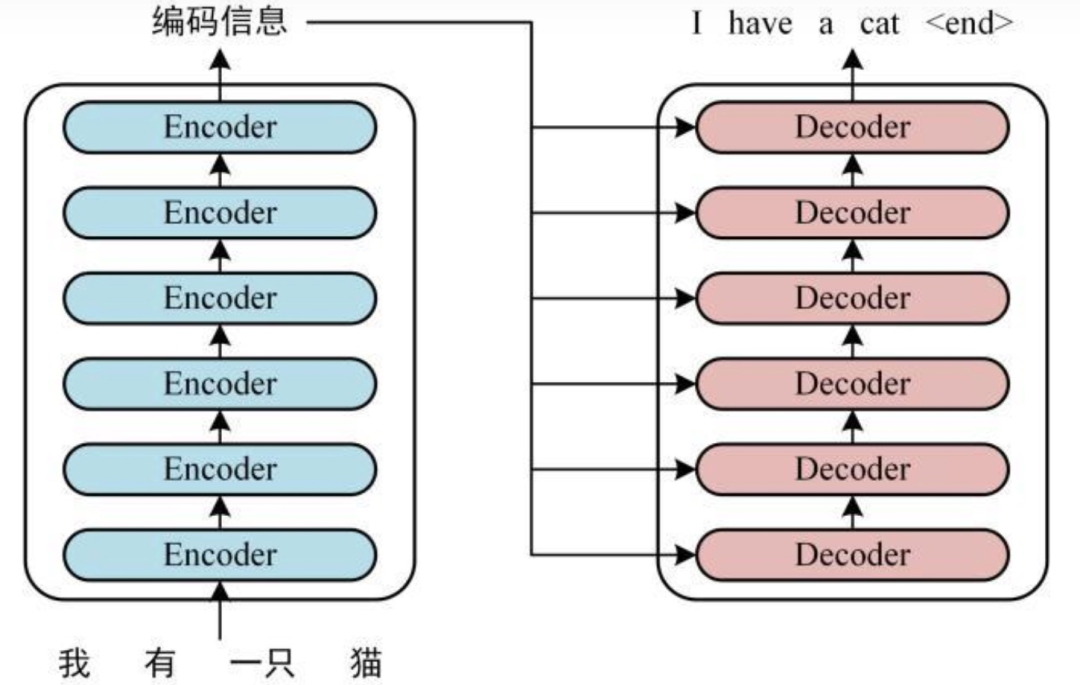
ELMo、GPT、BERT、X-Transformer…你都掌握了吗?一文总结文本分类必备经典模型(五)
二、Transformer基于Transformer的模型可以在不考虑顺序信息的情况下将计算并行化,适用于大规模的数据集,使其在NLP任务中很受欢迎。Transformer由17年一篇著名论文“Attention is All Your Need”提出的。在这篇论文中,作者提出了一种全新的注意力机制...
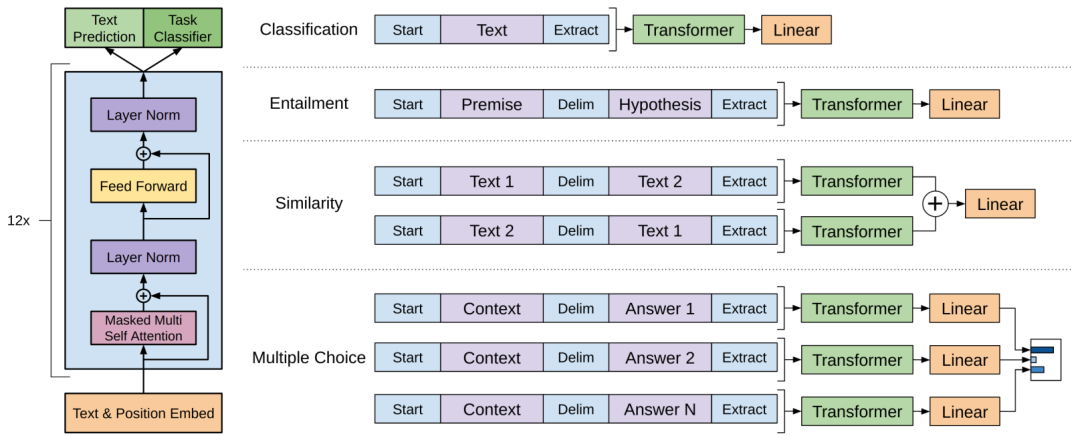
ELMo、GPT、BERT、X-Transformer…你都掌握了吗?一文总结文本分类必备经典模型(四)
1.2 GPTGPT是“Generative Pre-Training”的简称,是指的生成式的预训练。GPT的训练程序包括两个阶段。第一阶段的预训练是在一个大型文本语料库上学习一个高容量的语言模型。接下来是一个微调阶段,在这个阶段,使模型适应带有标记数据的判别性任务。第一阶段的工作具体为:Embed...
ELMo、GPT、BERT、X-Transformer…你都掌握了吗?一文总结文本分类必备经典模型(三)
本文将分 3 期进行连载,共介绍 20 个在文本分类任务上曾取得 SOTA 的经典模型。第 1 期:RAE、DAN、TextRCNN、Multi-task、DeepMoji、RNN-Capsule第 2 期:TextCNN、DCNN、XML-CNN、TextCapsule、、Bao et ...
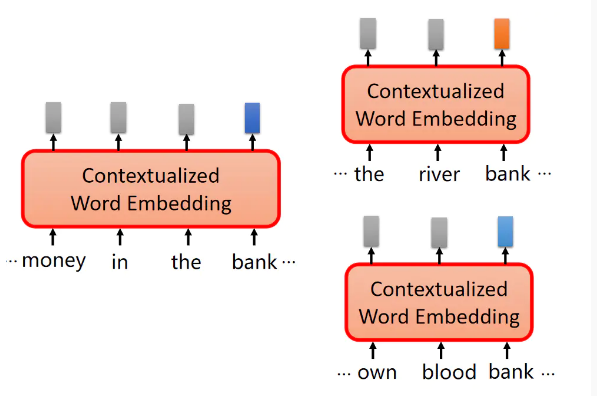
ELMO,BERT,GPT|深度学习(李宏毅)(十)
一、Embeddings from Language Model(ELMO)词嵌入的局限性之前讲过的词嵌入具有一定的局限性。举例来说,现有以下句子:Have you paid that money to the bank yet ?It is safest to deposit your money...
BERT和ELMo两者也什么不同?
BERT和ELMo两者也什么不同?
BERT 和 ELMo两者的不同是什么?
BERT 和 ELMo两者的不同是什么?
迁移学习NLP:BERT、ELMo等直观图解
2018年是自然语言处理的转折点,能捕捉潜在意义和关系的方式表达单词和句子的概念性理解正在迅速发展。此外,NLP社区已经出现了非常强大的组件,你可以在自己的模型和管道中自由下载和使用(它被称为NLP的ImageNet时刻)。 在这个时刻中,最新里程碑是发布的BERT,它被描述NLP一个新时代的开始。...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。