一种基于Spark深度随机森林的网络入侵检测模型
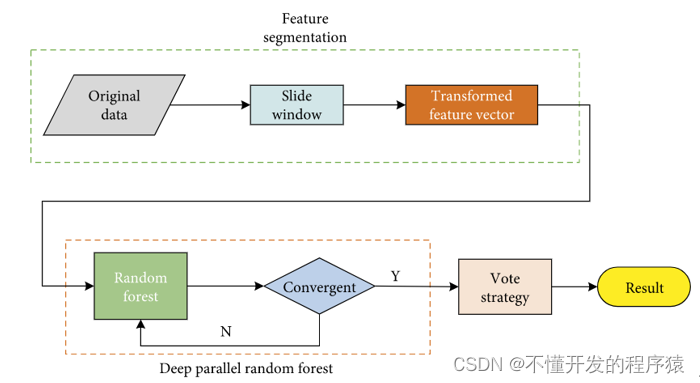
学习目标一种基于Spark深度随机森林的网络入侵检测模型学习内容(1)提出了一种随机森林的深度级联结构,将每一层并行化以提高准确性和可扩展性,以适应检测任务中的海量数据。可以对各种类型的攻击进行分类。(2)引入滑动窗口将高维特征分割成小尺寸特征向量进行训练,可以减少每次计算的计算量,保持原始信息的完...
python spark 随机森林入门demo
class pyspark.mllib.tree.RandomForest[source] Learning algorithm for a random forest model for classification or regression. New in version 1.2.0...

随机森林算法demo python spark
关键参数 最重要的,常常需要调试以提高算法效果的有两个参数:numTrees,maxDepth。 numTrees(决策树的个数):增加决策树的个数会降低预测结果的方差,这样在测试时会有更高的accuracy。训练时间大致与numTrees呈线性增长关系。 maxDepth:是指森林中每一棵决策树最...
spark 随机森林算法案例实战
随机森林算法 由多个决策树构成的森林,算法分类结果由这些决策树投票得到,决策树在生成的过程当中分别在行方向和列方向上添加随机过程,行方向上构建决策树时采用放回抽样(bootstraping)得到训练数据,列方向上采用无放回随机抽样得到特征子集,并据此得到其最优切分点,这便是随机森林算法的基本原理。图...
Spark随机森林实现学习
前言 最近阅读了spark mllib(版本:spark 1.3)中Random Forest的实现,发现在分布式的数据结构上实现迭代算法时,有些地方与单机环境不一样。单机上一些直观的操作(递归),在分布式数据上,必须进行优化,否则I/O(网络,磁盘)会消耗大量时间。本文整理spark随机森林实现中...
【Spark Summit East 2017】使用“宽”随机森林在基因组的大草堆中寻针
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。 本讲义出自Piotr Szul在Spark Summ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作