
手把手教你大数据离线综合实战 ETL+Hive+Mysql+Spark
引言大家好,我是ChinaManor,直译过来就是中国码农的意思,俺希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,一个平凡而不平庸的人。1.第一章 综合实战概述数据管理平台(Data ManagementPlatform,简称DMP),能够为广告投放提供人群标签进行受众精准定向,并通过投放...
老哥 我们想在客户的内网部署我们的产品后,在maxcompute上提交spark离线任务,但是这个?
问题1:老哥 我们想在客户的内网部署我们的产品后,在maxcompute上提交spark离线任务,但是这个离线任务的数据来自客户他们的mysql 或者其他数据源 你知道怎么访问吗? 我在官网上找到maxcompute spark访问vpc, 但是客户他们自己的产品可能不是部署在阿里云上的 问题2:客...


Apache Spark + 海豚调度:PB 级数据调度挑战,教你如何构建高效离线工作流
点击预约直播2010 年,我国进入移动互联网,数据规模成几何式增长。在大数据开源技术领域,以 Hadoop 为核心的大数据生态系统面对海量数据也不断发展与迭代,大数据处理流程中的各个开源组件,也一起开启了狂飙突进的大数据时代,推动了整个行业开启了数字化变革之路。近年来,大数据行业的开发者都在感慨&a...
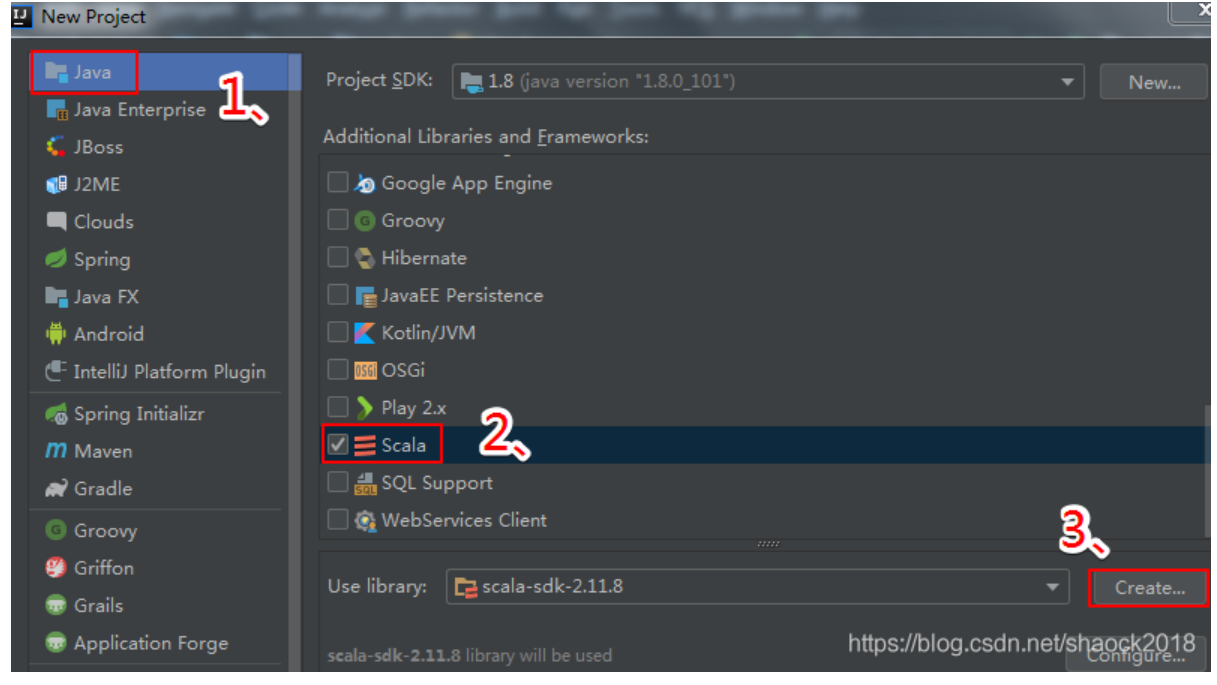
IntelliJ IDEA开发Spark案例之WordCount(非Maven、离线版)
0x00 教程内容新建Scala项目编写Scala代码打包到服务器执行实验前提:a. 安装好了windows本地的scalab. 安装好了IDEA的scala插件c. 安装好了JDK0x01 新建Scala项目1. 新建Scala项目a. 新建一个Scala项目,先选择Java,然后在右边选择Sca...
大数据分析处理框架——离线分析(hive,pig,spark)、近似实时分析(Impala)和实时分析(storm、spark streaming)
大数据分析处理架构图 数据源: 除该种方法之外,还可以分为离线数据、近似实时数据和实时数据。按照图中的分类其实就是说明了数据存储的结构,而特别要说的是流数据,它的核心就是数据的连续性和快速分析性; 计算层: 内存计算中的Spark是UC Berkeley的最新作品,思路是利用集群...
Spark-ML-01-小试spark分析离线商品信息
任务 一个在线商品购买记录数据集,约40M,格式如下: Jack,iphone cover,9,99 Jack,iphone cover,9,99 Jack,iphone cover,9,99 Jack,iphone cover,9,99 完成统计: 1.购买总次数 2.客户总个数 3.总收入 4....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作