
【机器学习】numpy实现Adam优化器
Adam优化原理自适应矩估计(Adam)是计算每个参数的自适应学习率的另一种方法。除了存储过去平方梯度(如Adadelta和RMSprop)的指数衰减平均值外,Adam还保持过去梯度的指数衰减平均值,类似于动量:它们通过计算偏差修正的第一和第二矩估计值来抵消这些偏差:然后,...
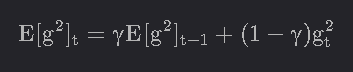
【机器学习】numpy实现Adadelta优化器
Adadelta优化原理Adadelta是Adagrad的一个扩展,旨在降低其攻击性、单调递减的学习率。Adadelta没有累加所有过去的平方梯度,而是将累加过去梯度的窗口限制为某个固定大小:w。不是低效地存储以前的平方梯度,而是将梯度之和递归定义为所有过去平方梯度的衰减平均值。然后,时间步的运行平...
【机器学习】numpy实现Momentum动量优化器
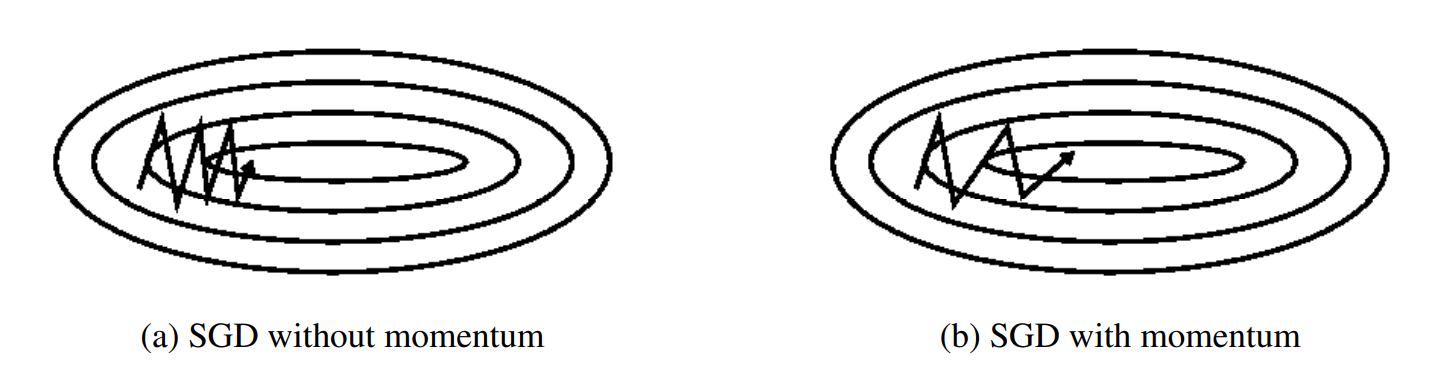
Momentum优化原理SGD难以在沟壑中航行,即曲面在一个维度上的曲线比在另一个维度上的曲线陡峭得多的区域,这在局部最优点附近很常见。在这些情况下,SGD在沟谷的斜坡上振荡,同时沿着底部向局部最优方向缓慢前进,如图所示。动量是一种有助于在相关方向上加速SGD并抑制振荡的方法,如图b所示。它通过将过...
【机器学习】numpy实现Adagrad优化器
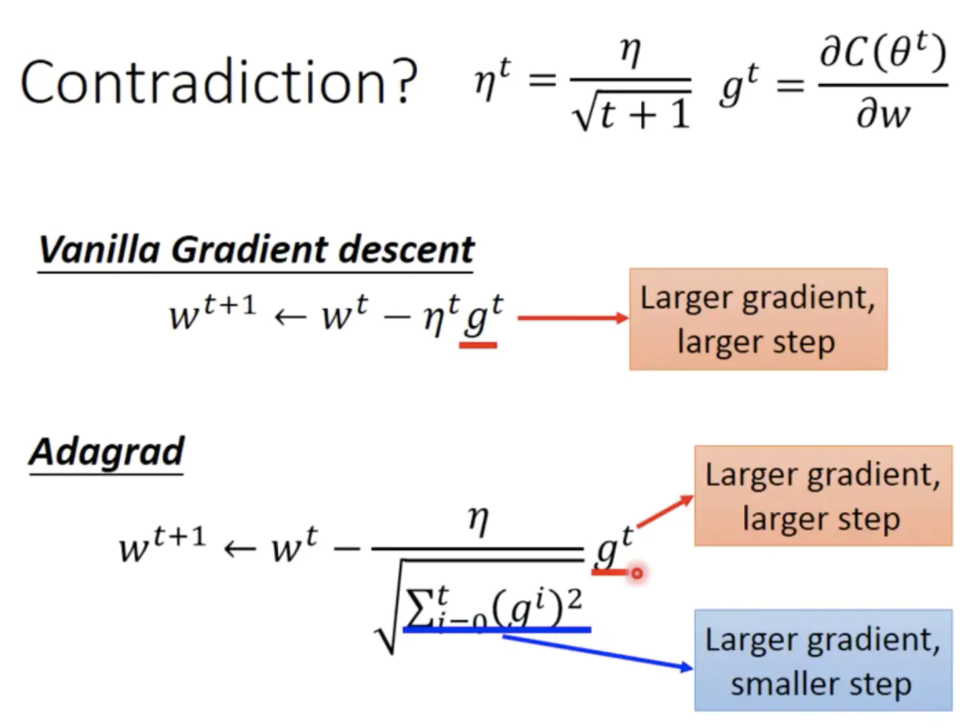
Agagrad优化原理随着我们更新次数的增大,我们是希望我们的学习率越来越小。因为模型求解最初阶段,我们认为距离损失函数最优解是很远的,所以此时学习率可以很大,以缩减寻优过程的求解时间,随着更新的次数的增多,我们认为越来越接近最优解,于是学习速率也随之变小,以防止跳过最优解。迭代过程代...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。


