[帮助文档] RoutineLoad功能的实现原理,使用方式以及最佳实践
例行导入(Routine Load)功能,支持用户提交一个常驻的导入任务,通过不断的从指定的数据源读取数据,将数据导入到Doris中。本文主要介绍Routine Load功能的实现原理、使用方式以及最佳实践。
[帮助文档] StarRocksDataXWriter原理
DataX Writer插件实现了写入数据到StarRocks目的表的功能。在底层实现上,DataX Writer通过Stream Load以CSV或JSON格式导入数据至StarRocks。内部将Reader读取的数据进行缓存后批量导入至StarRocks,以提高写入性能。阿里云DataWorks...

[帮助文档] 什么是RoutineLoad,基本原理是什么,有哪些常见问题
Routine Load是一种例行导入方式,StarRocks通过该方式支持从Kafka持续不断的导入数据,并且支持通过SQL控制导入任务的暂停、重启和停止。本文为您介绍Routine Load导入的基本原理、导入示例以及常见问题。
[帮助文档] 如何使用FlinkConnector,内部实现原理是什么
Flink Connector内部实现是通过缓存并批量由Stream Load导入。本文为您介绍Flink Connector的使用方式及示例。
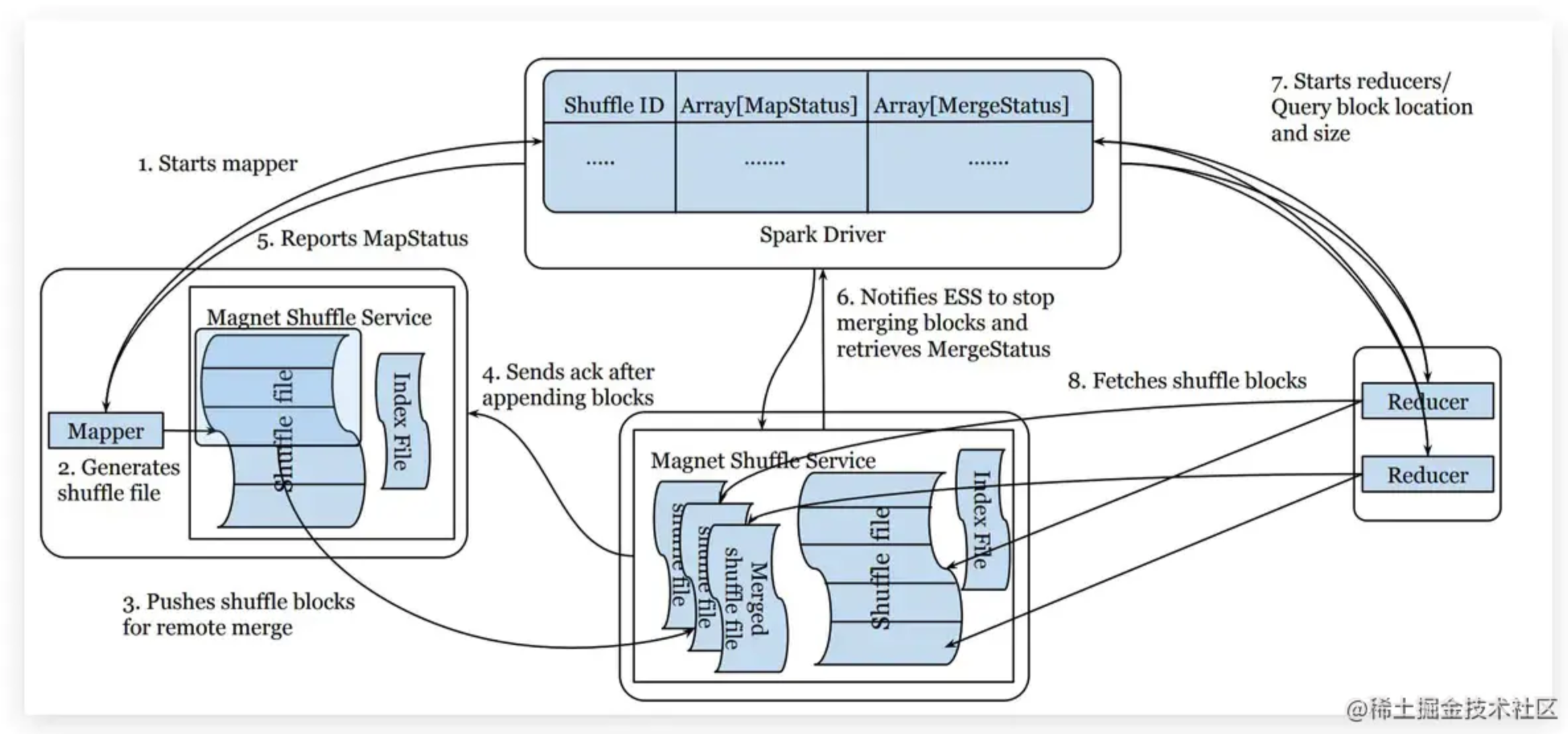
六、【计算】大数据Shuffle原理与实践(下) | 青训营笔记
👉引言💎学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。 热爱写作,愿意让自己成为更好的人............铭记于心🎉✨🎉我唯一知道的,便是我一无所知🎉✨🎉四、Push Shuffle0 概述为什么需要Pus...
大数据 Shuffle 原理与实践|青训营笔记
课程资料课程视频:https://live.juejin.cn/4354/yc_Shuffle课程PPT:https://bytedance.feishu.cn/file/boxcnQaV9uaxTp4xF0d1vEK5W3c学员手册:https://juejin.cn/post/712390820...
[帮助文档] 如何配置拦截器Interceptor、Channel选择器ChannelSelector和Sink组逻辑处理器SinkProcessor
本文通过示例为您介绍E-MapReduce中的Flume组件,如何配置拦截器(Interceptor)、Channel选择器(Channel Selector)和Sink组逻辑处理器(Sink Processor)。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute storm
- 云原生大数据计算服务 MaxCompute简介
- 云原生大数据计算服务 MaxCompute组件
- 云原生大数据计算服务 MaxCompute集合
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute java
- 云原生大数据计算服务 MaxCompute mapreduce
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute批量插入
- 云原生大数据计算服务 MaxCompute mysql
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute产品