[帮助文档] 创建工作空间
工作空间是Serverless Spark的基本单元,用于管理任务、成员、角色和权限。所有的任务开发都需要在具体的工作空间内进行。因此,在开始任务开发之前,您需要先创建工作空间。本文将为您介绍如何在EMR Serverless Spark页面快速创建工作空间。
[帮助文档] Spark SQL任务快速入门
EMR Serverless Spark支持通过SQL代码编辑和运行任务。本文带您快速体验Spark SQL任务的创建、启动和运维等操作。

[帮助文档] RAM用户授权
当RAM用户(子账号)进行EMR Serverless Spark操作,例如创建、查看或删除工作空间等操作时,必须具有相应的权限。本文为您介绍如何进行RAM授权。
[帮助文档] PySpark任务开发入门
您可以自行编写并构建包含业务逻辑的Python脚本,上传该脚本后,即可便捷地创建和执行PySpark任务。本文通过一个示例,为您演示如何进行PySpark任务的开发与部署。
[帮助文档] 阿里云账号角色授权
使用EMR Serverless Spark前,需要授予您的阿里云账号AliyunServiceRoleForEMRServerlessSpark和AliyunEMRSparkJobRunDefaultRole系统默认角色。本文为您介绍角色授权的基本操作。

CommunityOverCode Asia 精彩回顾|阿里云开源大数据 EMR 技术实践分享
2023 年 8 月 18 日,Apache 软件基金会的官方全球系列大会 CommunityOverCode Asia(原 ApacheCon Asia)首次中国线下峰会在北京丽亭华苑酒店开幕。作为久负盛名的开源盛宴和开源界最具期待的大会之一,CommunityOverCode Asia 2023...
maxCompute可以直接对emr集群中的表数据进行处理么?
问题一:maxCompute可以直接对emr集群中的表数据进行处理么? 问题二:dataworks 与emapreduce地域都是成都是不支持的么?如下图 问题三:如果因为地域限制不能集成湖仓一体,就不能通过maxCompute对emapreduce进行处理么?
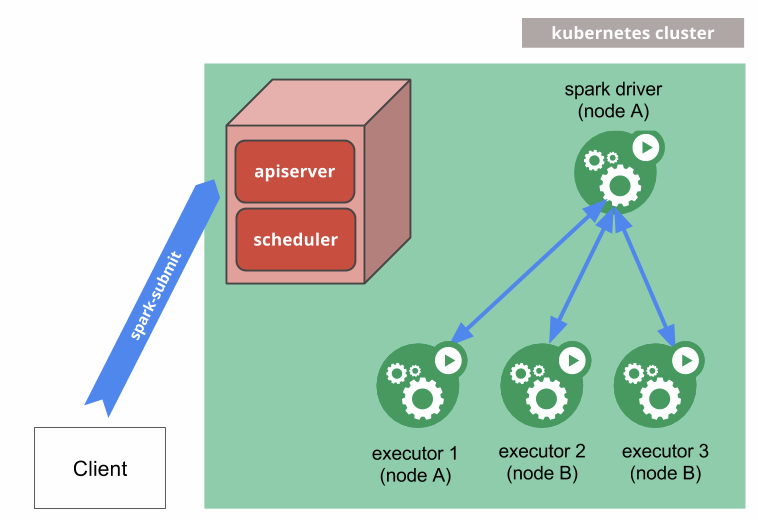
基于 Kubernetes 的企业级大数据平台,EMR on ACK 技术初探
作者:容器服务团队云上大数据的 Kubernetes 技术路线当前,大数据与机器学习领域颇为关注存储与计算分离架构,逐渐向云原生演进。以Spark 为例,云下或自有服务器可以选择 Hadoop 调度支持 Spark,云上的 Spark 则会考虑如何充分享有公共云的弹性资源、运维管控和存储服务等,并且...
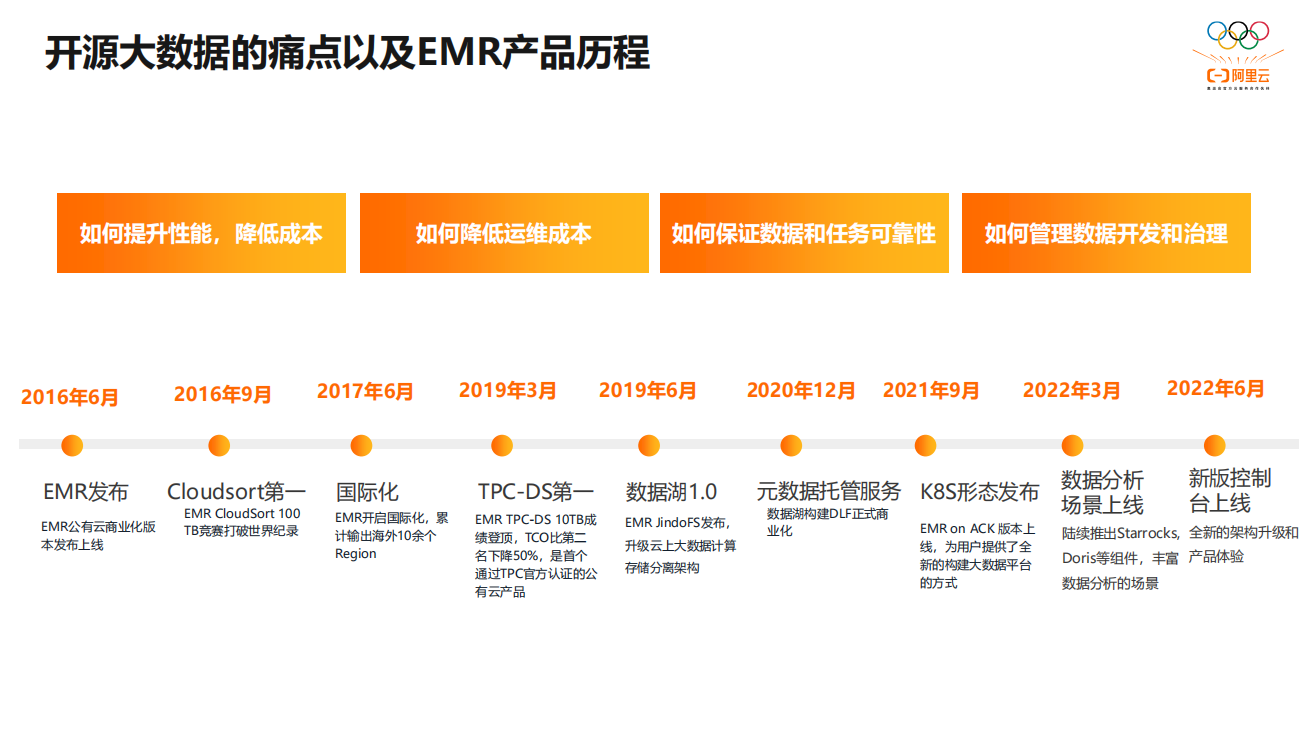
阿里云EMR 2.0:重新定义新一代开源大数据平台
摘要:本文整理自阿里云高级产品专家何源(荆杭)在 阿里云EMR2.0线上发布会 的分享。本篇内容主要分为三个部分:开源大数据的痛点及EMR产品历程EMR2.0 新特征总结点击查看直播回放一、开源大数据的痛点及EMR产品历程 开源大数据的痛点 如何提升性能,降低资源成本 全面的...
RDS大数据相关产品组件好多,EMR和MaxComputer的主要区别是什么?
RDS大数据相关产品组件好多,感觉EMR和MaxComputer系列有好多类似的功能,EMR和MaxComputer的主要区别是什么?选型时有什么建议和注意事项?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









云原生大数据计算服务 MaxComputeemr相关内容
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute数据同步
- 云原生大数据计算服务 MaxCompute配置
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute表数据
- 云原生大数据计算服务 MaxCompute实时同步
- 云原生大数据计算服务 MaxCompute单表
- 云原生大数据计算服务 MaxCompute方案
- 云原生大数据计算服务 MaxCompute订阅
- 云原生大数据计算服务 MaxCompute mysql
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目