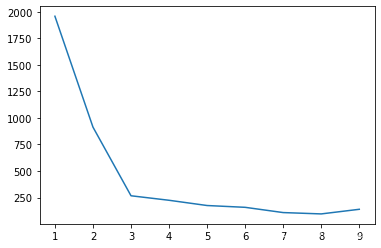
【Python机器学习】实验08 K-means无监督聚类 2
8 使用“肘部法则”选取k值def selecte_K(X,iter_num): dist_arry=[] for k in range(1,10): centroids,idx=k_means(data.values,k,iter_num) dist_arry.append((k,metric_s...
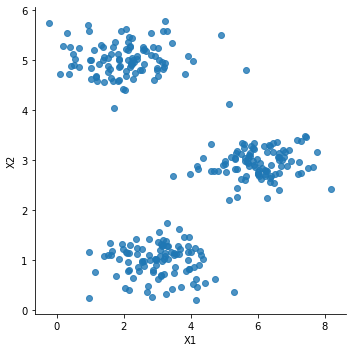
【Python机器学习】实验08 K-means无监督聚类 1
聚类在本练习中,我们将实现K-means聚类K-means 聚类我们将实施和应用K-means到一个简单的二维数据集,以获得一些直观的工作原理。 K-means是一个迭代的,无监督的聚类算法,将类似的实例组合成簇。 该算法通过猜测每个簇的初始聚类中心开始,然后重复将实例分配给最近的簇,并重新计算该簇...

【机器学习实战】10分钟学会Python怎么用K均值K-means进行聚类(九)
[toc]1 前言1.1 K-means的介绍K均值(K-means)是一种基于距离度量的聚类算法,其主要思想是将数据集划分为k个不同的簇,每个簇代表一个相似度较高的数据组。该算法通过迭代优化来最小化所有数据点与其所属簇的欧氏距离之和,从而找到最佳的簇划分。需要区分一下,K-means和KNN是两种...
机器学习里的K-Means聚类的好处是什么?
机器学习里的K-Means聚类的好处是什么?
机器学习笔记之K-means聚类
K-means聚类是聚类分析中比较基础的算法,属于典型的非监督学习算法。 其定义为对未知标记的数据集,按照数据内部存在的数据特征将数据集划分为多个不同的类别,使类别内的数据尽可能接近,类别间的数据相似度比较大。用于衡量距离的方法主要有曼哈顿距离、欧氏距离、切比雪夫距离,其中欧氏距离较为常用。 算法原...
DIY图像压缩——机器学习实战之K-means 聚类图像压缩:色彩量化
更多深度文章,请关注:https://yq.aliyun.com/cloud 作者:ML bot2这篇文章是K均值聚类算法(K-means clustering)的一个简单应用:压缩图像。 在彩色图像中,每个像素的大小为3字节(RGB),可以表示的颜色总数为256 * 256 * 256。下图为12...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI论文
- 机器学习平台 PAI代码
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI构建
- 机器学习平台 PAI模型
- 机器学习平台 PAIpai
- 机器学习平台 PAI升级
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI分类
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI平台
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践