讲解机器学习中的 K-均值聚类算法及其优缺点。
K-均值聚类算法是一种无监督学习算法,常用于对数据进行聚类分析。其主要步骤如下: 首先随机选择K个中心点(质心)作为初始聚类中心。 对于每一个样本,计算其与每一个中心点的距离,将其归到距离最近的中心点所在的聚类。 对于每一个聚类,重新计算其中所有样本的中心点位置。 重复以上步骤,直到聚类中心不再改变...
讲解机器学习中的 K-均值聚类算法及其优缺点。
K-均值聚类的步骤如下:随机选择 K 个点作为初始化质心。分别计算每个样本与所有质心之间的距离,将每个样本分配到与其距离最近的质心所在的簇中。更新质心,即将每个簇的质心移动到该簇中所有样本的平均位置。重复步骤 2 和 3,直到质心不发生变化或达到最大迭代次数。K-均值聚类算法的优点包括:简单而直观:...
机器学习中的 K-均值聚类算法及其优缺点
K-均值聚类算法是一种无监督学习算法,用于将数据分成K个不同的类别。该算法将每个数据点都视为一个向量,并通过计算各数据点之间的距离来确定它们所属的类别。具体地说,该算法的流程如下:选择K个随机的点作为初始聚类中心;对每个数据点,计算其与K个聚类中心之间的距离,并将其分配到距离最近的聚类中心所代表的类...
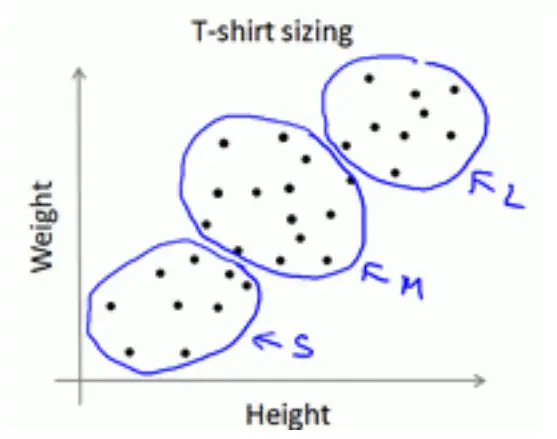
机器学习面试笔试知识点之非监督学习-K 均值聚类、高斯混合模型(GMM)、自组织映射神经网络(SOM)
1. 聚类算法都是无监督学习吗?什么是聚类算法?聚类是一种机器学习技术,它涉及到数据点的分组。给定一组数据点,我们可以使用聚类算法将每个数据点划分为一个特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督学习的方法,是许...
机器学习PAI中Pipeline的二分均值聚类模型获取能聚类后的质心坐标吗
机器学习PAI中Pipeline的二分均值聚类模型(BisectingKMeansModel)能获取聚类后的质心坐标吗

【机器学习实战】10分钟学会Python怎么用K均值K-means进行聚类(九)
[toc]1 前言1.1 K-means的介绍K均值(K-means)是一种基于距离度量的聚类算法,其主要思想是将数据集划分为k个不同的簇,每个簇代表一个相似度较高的数据组。该算法通过迭代优化来最小化所有数据点与其所属簇的欧氏距离之和,从而找到最佳的簇划分。需要区分一下,K-means和KNN是两种...
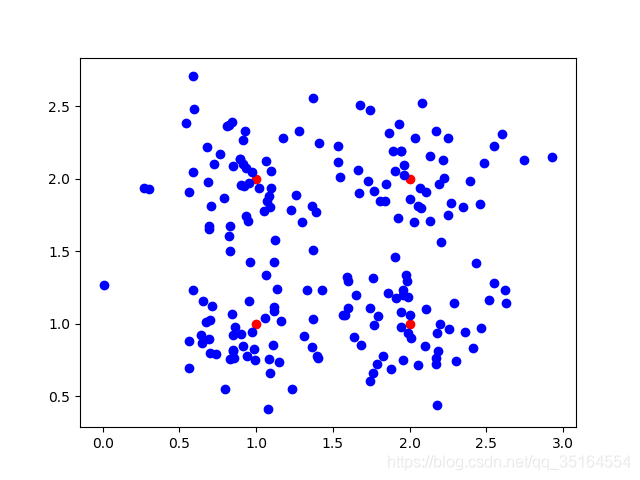
瞎聊机器学习——K-均值聚类(K-means)算法
本文中我们将会聊到一种常用的无监督学习算法——K-means。1、K-means算法的原理K-means算法是一种迭代型的聚类算法,在算法中我们首先要随机确定K个初始点作为质心,然后去计算其他样本距离每一个质心的距离,将该样本归类为距离最近的一个质心所属类别中(一个簇中)。举个例子来表述一下:如图所...
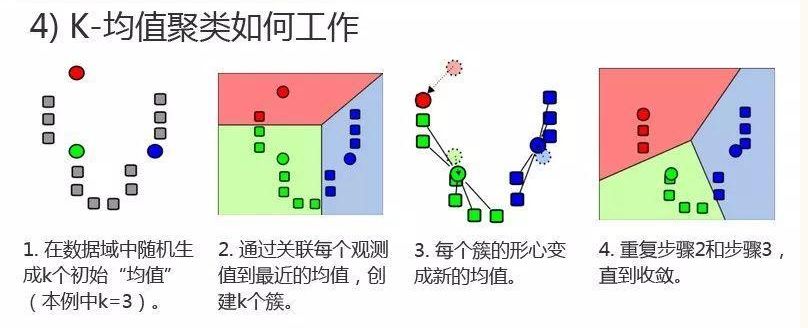
100天搞定机器学习|day43 几张GIF理解K-均值聚类原理
前文推荐如何正确使用「K均值聚类」?无监督学习是指从无标注数据中学习模型的机器学习问题。无标注数据是自然得到的数据,模型表示数据的类别、转换或概率无监督学习的本质是学习数据中的统计规律或潜在结构,主要包括聚类、降维、概率估计。KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,...
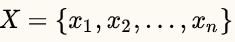
100天搞定机器学习|day44 k均值聚类数学推导与python实现
前文推荐如何正确使用「K均值聚类」?1、k均值聚类模型a给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类。用C表示划分,他是一个多对一的函数,k均值聚类就是一个从样本到类的函数。2、k均值聚类策略k均值聚类的策...
机器学习的K均值聚类算法使用的过程是什么呢?
机器学习的K均值聚类算法使用的过程是什么呢?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。


机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI代码
- 机器学习平台 PAI论文
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI模型
- 机器学习平台 PAI构建
- 机器学习平台 PAI升级
- 机器学习平台 PAIpai
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI分类
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI平台
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践