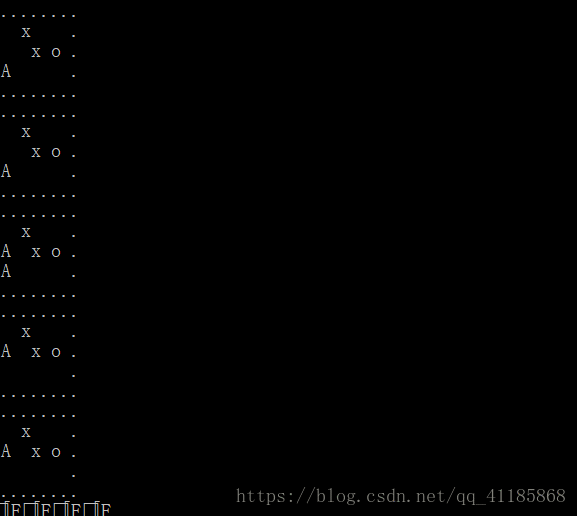
RL之Q Learning:利用强化学习之Q Learning实现走迷宫—训练智能体走到迷宫(复杂迷宫)的宝藏位置
输出结果设计思路实现代码from __future__ import print_functionimport numpy as npimport timefrom env import Envfrom reprint import outputEPSILON = 0.1ALPHA = 0.1GAM...
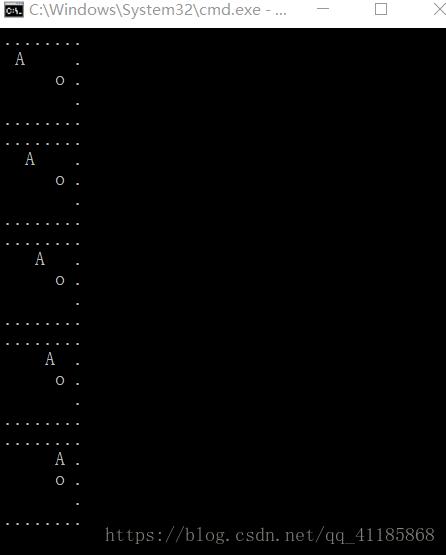
RL之Q Learning:利用强化学习之Q Learning实现走迷宫—训练智能体走到迷宫(简单迷宫)的宝藏位置
输出结果设计思路实现代码from __future__ import print_functionimport numpy as npimport timefrom env import EnvEPSILON = 0.1ALPHA = 0.1GAMMA = 0.9MAX_STEP = 30np.ra...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



