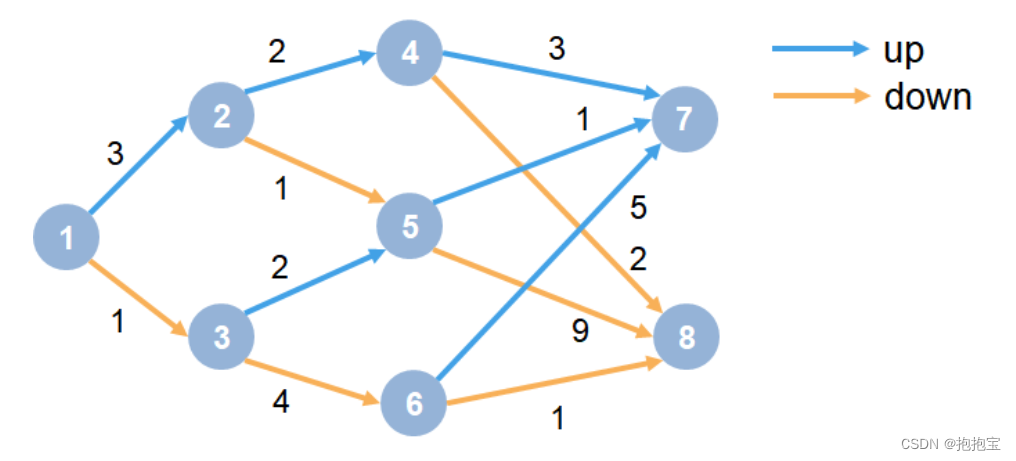
在MDP环境下训练强化学习智能体
本文示例展示了如何训练Q-learning智能体来解决一般的马尔可夫决策过程(MDP)环境。有关这些智能体的更多信息,请参阅Q-Learning智能体。MDP环境如下图:其中:每一个圆圈代表一个状态。每个状态可以决定上升或下降。智能体从状态1开始...

语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路
在智能体的开发中,强化学习与大语言模型、视觉语言模型等基础模型的进一步融合究竟能擦出怎样的火花?谷歌 DeepMind 给了我们新的答案。一直以来,DeepMind 引领了强化学习(RL)智能体的发展,从最早的 AlphaGo、AlphaZero 到后来的多模态、多任务、多具身 AI 智能体 Gat...

基于模型的多智能体强化学习中的模型学习理解
环境模型需要学习两个函数:状态转移函数,和奖励函数。多个智能体整体联合学习此时环境模型的学习与单智能体的学习并无太大差别,无非是观测空间维度扩大,动作空间维度扩大。此类建模方式优点:原理简单,较好实现。此类建模方式缺点:在此类模型中也可以做多尺度,此时的多尺度是整体上的多尺度ÿ...

多智能体强化学习(二) MAPPO算法详解
MAPPO论文全称为:The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games 这篇文章属于典型的,我看完我也不知道具体是在哪里创新的,是不是我漏读了什么,是不是我没有把握住,论文看一半直接看代码去了,因此后...

多智能体强化学习(一) IQL、VDN、QMIX、QTRAN算法详解
一个完全合作式的多智能体任务(我们有n个智能体,这n个智能体需要相互配合以获取最大奖励)可以描述为去中心化的部分可观测马尔可夫决策模型(Dec-POMDP),通常用一个元组G GG来表示:IQLIQL论文全称为:MultiAgent Cooperation and Competitio...

【NIPS 2017】基于深度强化学习的想象力增强智能体
论文题目:Imagination-Augmented Agents for Deep Reinforcement Learning所解决的问题?背景最近也是有很多文章聚焦于基于模型的强化学习算法,一种常见的做法就是学一个model,然后用轨迹优化的方法求解一下,而这种方法并没有考虑与真实环境的差异,...
![强化学习从基础到进阶–案例与实践[11]:AlphaStar论文解读、监督学习、强化学习、模仿学习、多智能体学习、消融实验](https://ucc.alicdn.com/fnj5anauszhew_20230630_23c6ebb7a44c4507999e9d704e5eaee4.png)
强化学习从基础到进阶–案例与实践[11]:AlphaStar论文解读、监督学习、强化学习、模仿学习、多智能体学习、消融实验
强化学习从基础到进阶–案例与实践[11]:AlphaStar论文解读、监督学习、强化学习、模仿学习、多智能体学习、消融实验 AlphaStar及背景简介 相比于之前的深蓝和AlphaGo,对于《星际争霸Ⅱ》等策略对战型游戏,使用AI与人类对战的难度更大。比如在《星际争霸Ⅱ》中,要想在玩家对战玩家的模...

星际争霸II协作对抗基准超越SOTA,新型Transformer架构解决多智能体强化学习问题
多智能体强化学习 (MARL) 是一个具有挑战性的问题,它不仅需要识别每个智能体的策略改进方向,而且还需要将单个智能体的策略更新联合起来,以提高整体性能。最近,这一问题得到初步解决,有研究人员引入了集中训练分散执行 (CTDE) 的方法,使智能体在训练阶段可以访问全局信息。然而,这些方法无法涵盖多智...

7 Papers & Radios | 新型Transformer架构解决多智能体强化学习问题;ICRA 2022最佳论文出炉(2)
论文 5:A Ceramic-Electrolyte Glucose Fuel Cell for Implantable Electronics作者:Philipp Simons、Steven A. Schenk 等论文地址:https://onlinelibrary.wiley.com/doi/f...
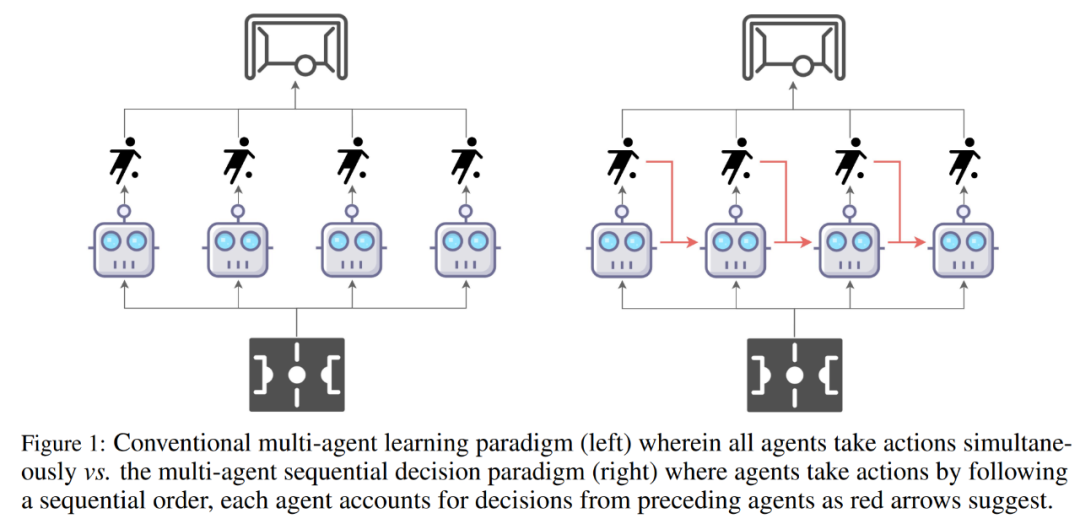
7 Papers & Radios | 新型Transformer架构解决多智能体强化学习问题;ICRA 2022最佳论文出炉(1)
本周主要论文包括:上海交通大学、Digital Brain Lab、牛津大学等的研究者用新型 Transformer 架构解决多智能体强化学习问题;ICRA 2022 最佳论文出炉,美团无人机团队获唯一最佳导航论文奖等研究。目录Multi-Agent Reinforcement Learning i...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



