54 Hive的Join操作
语法结构join_table: table_reference JOIN table_factor [join_condition] | table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition | t...
大数据Hive Join连接查询
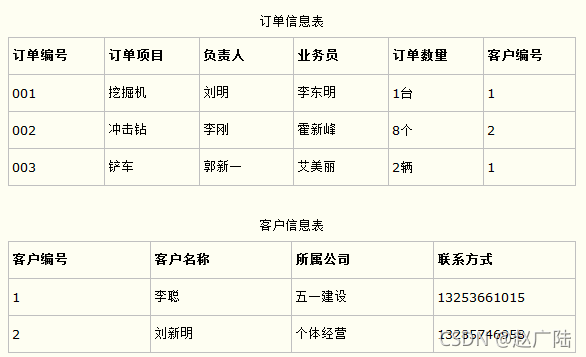
1 join概念回顾根据数据库的三范式设计要求和日常工作习惯来说,我们通常不会设计一张大表把所有类型的数据都放在一起,而是不同类型的数据设计不同的表存储。比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的...

为什么通过spark 写 hudi 同步 hive 设置的主键是 通过join写过来的
为什么通过spark 写 hudi 同步 hive 设置的主键是 通过join写过来的 然后 数据进入hudi后 通过flink 查询 就提示 找不到主键 此时 spark 查询是正常 如果通过 单独生成主键比如 直接定义一个数值 此时 flink是可以查询。做了测试 hudi主键 必须是 int ...
loop up join 支持hive吗?
loop up join 支持hive吗?
Hive中的in、exists和left semi join
在hive sql开发的过程中,对于当前数据在另一个数据集合中,是否存在的判断有三种方式,一种是in ,一种是exists,另一种可以是left semi join,但是由于hive不支持in|not in子查询,所以如果是单纯判断一个值是否在一个集合里面存在的时候,可以用in,但是判断一个集合在另...
有用过flink streaming去lookup join一个一亿条数据的hive维表的经验的吗?
有没有哪位有用过flink streaming 去lookup join一个一亿条数据的hive维表的经验。左边kafka,每分钟500万条,两侧字段球不到30,hive数据同步到kv里再去join,join的时候再加些缓存
Flink每天有很多本地excel文件,每天想放到hive里面各种join,有什么办法?
Flink每天有很多本地excel文件,每天想放到hive里面各种join,有什么办法?
hive:条件查询、join关联查询、分组聚合、子查询
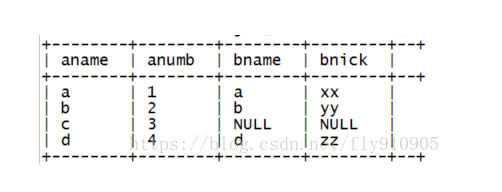
hive查询语法提示:在做小数据量查询测试时,可以让hive将mrjob提交给本地运行器运行,可以在hive会话中设置如下参数:hive> set hive.exec.mode.local.auto=true; 基本查询示例select * f...
hive当中join 连接怎么做?
hive当中join 连接怎么做?
kafka流与hive表join问题
请问一下,如何保证先加载完hive表,然后再与流join,我发现在hive还没有加载完就已经有join的结果出来,这样刚开始出来的结果是不准确的,还有一个问题是hive表加载完之后不会再做checkpoint?我目前使用的是1.7.1版本,看了1.9的维表join,blink文档说(必须加上FOR ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。