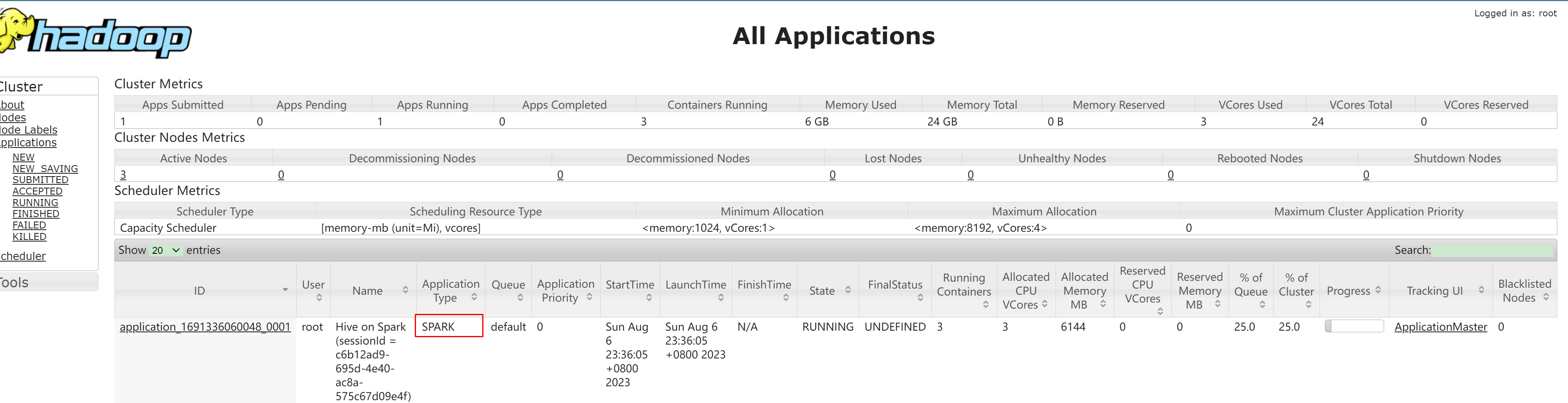
配置Hive使用Spark执行引擎
Hive引擎 概述 在Hive中,可以通过配置来指定使用不同的执行引擎。Hive执行引擎包括:默认MR、tez、spark MapReduce引擎: 早期版本Hive使用MapReduce作为执行引擎。MapReduce是Hadoop的一种计算模型,它通过将数据划分为小块并在集群上并行处理来完成计算...
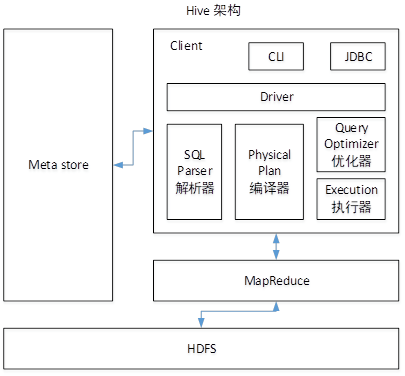
Hive----执行引擎
Hive引擎包括:默认MR、spark、tezHive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。Spark on Hive:Hive只作为存储元数据(提供数据源),Spar...

Hive与传统数据库在执行引擎和数据规模上的区别是什么?
Hive与传统数据库在执行引擎和数据规模上的区别是什么?
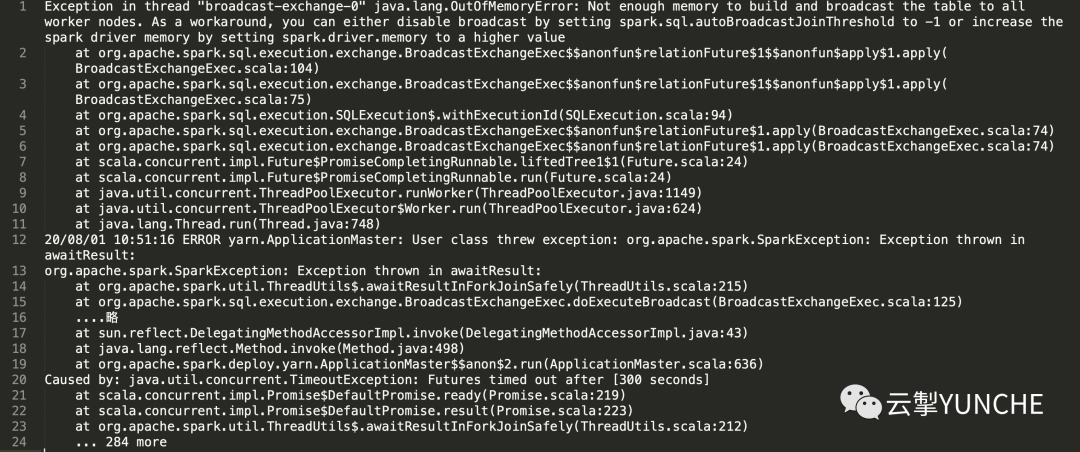
技本功|Hive优化之Spark执行引擎参数调优(二)
Hive是大数据领域常用的组件之一,主要是大数据离线数仓的运算,关于Hive的性能调优在日常工作和面试中是经常涉及的的一个点,因此掌握一些Hive调优是必不可少的一项技能。影响Hive效率的主要有数据倾斜、数据冗余、job的IO以及不同底层引擎配置情况和Hive本身参数和HiveSQL的执行等因素。...
连接hive,hive执行引擎是 MR 还是 Flink ?
转自钉钉群21789141:连接hive,hive执行引擎是 MR 还是 Flink ?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。