Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架Spider类参数设置
python爬虫:scrapy框架Scrapy类与子类CrawlSpider
Scrapy类name 字符串,爬虫名称,必须唯一,代码会通过它来定位spiderallowed_domains 列表,允许域名没定义 或 空: 不过滤,url不在其中: url不会被处理,域名过滤功能: settings中OffsiteMiddlewarestart_urls:列表或者元组,任务的...

Python爬虫:scrapy框架Spider类参数设置
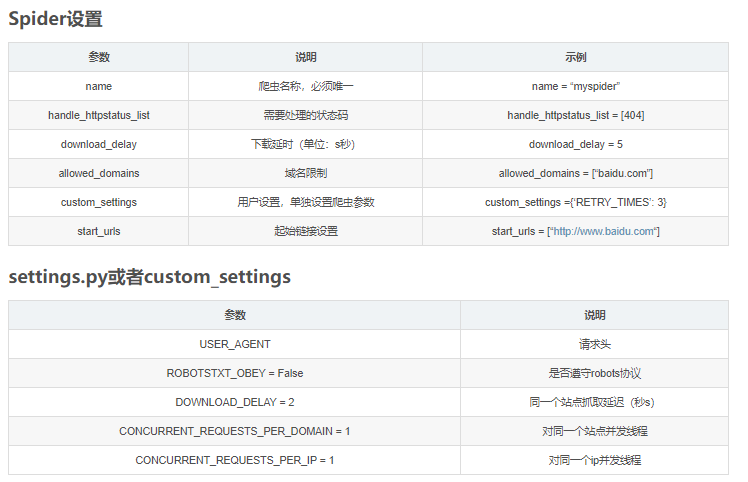
Spider设置参数说明示例name爬虫名称,必须唯一name = “myspider”handle_httpstatus_list需要处理的状态码handle_httpstatus_list = [404]download_delay下载延时(单位:s秒)download_delay = 5all...
python爬虫类项目,requests无法正常get网页
我的系统是centos7,想在服务器上测试一个python脚本,通过requests模块发送get请求,访问https://www。footlocker。com。程序在自己的电脑上win10系统测试是成功的,但是一旦部署到ECS服务器端的时候,就无法访问了,显示read time out,port=...
Python爬虫之多线程下载程序类电子书
近段时间,笔者发现一个神奇的网站:http://www.allitebooks.com/ ,该网站提供了大量免费的编程方面的电子书,是技术爱好者们的福音。其页面如下: 那么我们是否可以通过Python来制作爬虫来帮助我们实现自动下载这些电子书呢?答案是yes. 笔者在空闲时间写了一个爬虫...
python 爬虫爬取腾讯新闻科技类的企鹅智酷系列(1)
废话不多说,直接贴代码,主要采用BeautifulSoup写的 #coding:utf8 from bs4 import BeautifulSoup import urllib2 import urllib import os i = 0 j = 0 list_a = [] def gettext(...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python类相关内容
- Python编程类
- Python异常类
- Python继承类
- Python类方法
- Python class类
- Python set类型class类
- Python类型类
- Python格式化类
- Python类实例
- Python类对象实例
- Python类对象
- Python类class
- Python类object
- Python类概念
- Python类区别
- Python类包
- Python导入类
- Python测试类
- Python类属性区别
- Python类实例变量
- Python面向对象编程类实例
- Python类成员方法
- Python类实例属性
- Python类循环
- Python类内置方法
- Python类定义
- 类Python
- Python命名规范类
- Python案例类
- Python装饰器装饰类
- Python类装饰器
- Python面向对象类属性
- Python面向对象类定义
- Python类拓展
- Python gui类
- Python类遍历
- Python类旁通单链表
- Python类运算符
- Python类初始化
- Python类封装
- Python上天pygame类
- Python http协议类
- Python旧式类
- Python类属性静态方法
- Python process类
- Python接口自动化封装流程类
- Python类init
- 软件类蓝桥杯Python a-e
- Python自定义迭代器类异常生成器
Python更多类相关
- Python类继承
- Python类特殊成员方法
- Python面试类
- Python pool类方法
- Python flask类
- Python访问类
- Python类语法
- Python面向对象类静态方法
- Python pool类参数
- Python process类参数
- Python数学类
- 类均值聚类Python
- Python新式类旧式
- Python自定义异常类
- Python面向对象编程类对象
- Python类基础
- Python编程类定义
- Python scrapy类
- Python类子类
- Python类str
- Python pool类func
- 进阶Python类特殊方法
- 数据结构与算法Python描述类
- Python自定义类
- Python类对象区别
- Python类单例模式
- Python数学类类型
- Python set类型类
- Python类使用
- Python面向对象编程静态方法类
- Python访问类属性
- Python类组合
- Python类metaclass
- 类属性Python
- Python类静态属性
- Python开头类
- Python类args
- 数据结构与算法Python类
- Python类实例属性访问