[帮助文档] 如何通过DataWorks数据集成同步异构数据源间的数据
本教程以MySQL中的用户基本信息(ods_user_info_d)表及OSS中的网站访问日志数据(user_log.txt)文件,通过数据集成离线同步任务分别同步至MaxCompute的ods_user_info_d、ods_raw_log_d表为例,为您介绍如何通过DataWorks数据集成实现...
大数据计算MaxCompute dataworks可以对数据集成任务进行批量修改数据源配置信息吗?
大数据计算MaxCompute dataworks可以对数据集成任务进行批量修改数据源配置信息吗?

大数据计算MaxCompute数据集成 Redis支持写到0以外的库吗?
大数据计算MaxCompute数据集成 Redis支持写到0以外的库吗?
大数据计算MaxCompute独享数据集成资源组访怎么访问经典环境数据源啊?
大数据计算MaxCompute独享数据集成资源组访怎么访问经典环境数据源啊?
大数据计算MaxCompute现在dataworks数据集成出现问题了嘛?
大数据计算MaxCompute现在dataworks数据集成出现问题了嘛?数据集成任务打开,报错,并我去管理中心查看数据源的时候发现一直无法加载我的数据源
大数据Spark Structured Streaming集成 Kafka
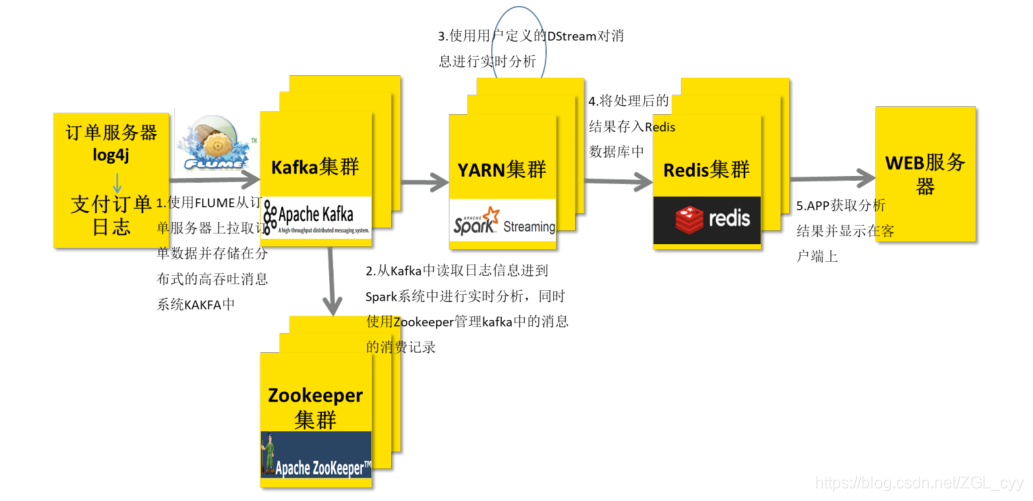
1 Kafka 数据消费Apache Kafka 是目前最流行的一个分布式的实时流消息系统,给下游订阅消费系统提供了并行处理和可靠容错机制,现在大公司在流式数据的处理场景,Kafka基本是标配。StructuredStreaming很好的集成Kafka,可以从Kafka拉取消息,然后就可以把流数据看...
大数据Spark Streaming集成Kafka
1 整合Kafka 0.8.2在实际项目中,无论使用Storm还是SparkStreaming与Flink,主要从Kafka实时消费数据进行处理分析,流式数据实时处理技术架构大致如下:技术栈: Flume/SDK/Kafka Producer API -> KafKa —> SparkS...
大数据计算MaxCompute华东2(上海)的公共集成资源的ip是多少,需要添加一下白名单?
大数据计算MaxCompute华东2(上海)的公共集成资源的ip是多少,需要添加一下白名单?
[帮助文档] 如何通过数据集成实时入湖
本文以Kafka实时入湖写入至OSS场景为例,为您介绍如何通过数据集成实时入湖。
大数据计算MaxCompute数据集成时,如果正常运行直到结束,那么就可以查到数据。但是如果终止那?
问题1:大数据计算MaxCompute数据集成时,如果正常运行直到结束,那么就可以查到数据。但是如果终止那么数据就不现实。这是为什么呢?问题2:那如果这个分区本来就有数据,我重新同步一遍,然后终止,那原来数据也会删除吗
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







