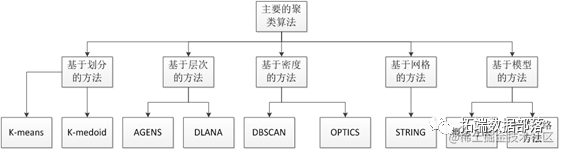
MATLAB、R用改进Fuzzy C-means模糊C均值聚类算法的微博用户特征调研数据聚类研究
全文链接:http://tecdat.cn/?p=30766 本文就将采用改进Fuzzy C-means算法对基于用户特征的微博数据进行聚类分析。去年,我们为一位客户进行了短暂的咨询工作,他正在构建一个主要基于微博用户特征聚类研究的分析应用程序(点击文末“阅读原文”获取完整代码数据)。 首先对聚类分...
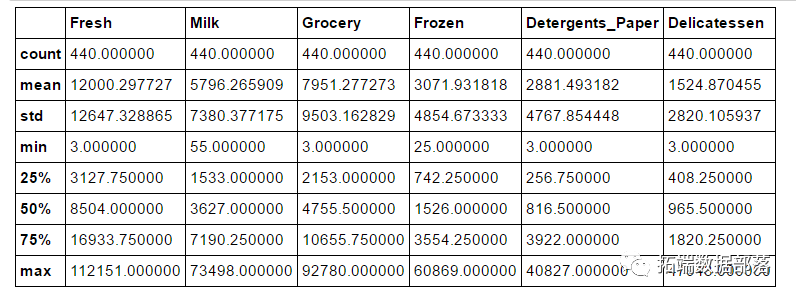
R语言聚类算法的应用实例
一家批发经销商想将发货方式从每周五次减少到每周三次,简称成本,但是造成一些客户的不满意,取消了提货,带来更大亏损,项目要求是通过分析客户类别,选择合适的发货方式,达到技能降低成本又能降低客户不满意度的目的。 什么是聚类 聚类将相似的对象归到同一个簇中,几乎可以应用于所有对象,聚类的对象越相似,聚类效...


使用Python实现DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它可以有效地识别具有任意形状的簇,并且能够自动识别噪声点。在本文中,我们将使用Python来实现一个基本的DBSCAN聚类算法,并介绍其原理...

使用Python实现K均值聚类算法
K均值(K-Means)算法是一种常用的聚类算法,它将数据集分成K个簇,每个簇的中心点代表该簇的质心,使得每个样本点到所属簇的质心的距离最小化。在本文中,我们将使用Python来实现一个基本的K均值聚类算法,并介绍其原理和实现过程。 什么是K均值算法? K均值算法是一种迭代的聚类算法&...

探索Python中的聚类算法:DBSCAN
在机器学习领域中,DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种常用的聚类算法。与传统的聚类算法(如K-means)不同,DBSCAN 能够发现任意形状的簇,并且可以有效地处理噪声数据。本文将详细介绍 DB...
K-means聚类算法是如何实现的?
K-means聚类算法的实现步骤如下: 初始化:选择K个初始质心(centroid),可以随机选择数据集中的K个数据点作为初始质心,或者使用其他方法进行初始化。分配数据点到最近的质心:计算每个数据点到各个质心的距离,将数据点分配到距离最近的质心所在的簇。更新质心:对于每个...
请解释Python中的K-means聚类算法以及如何使用Sklearn库实现它。
K-means聚类是一种无监督学习算法,用于将数据点划分为K个不同的簇(cluster)。每个簇内的数据点彼此相似,而不同簇之间的数据点则具有较大的差异。K-means算法的目标是最小化每个簇内数据点与其质心(centroid)之间的距离之和。 在Python中,可以使用Sklearn库来实现K-m...

探索Python中的聚类算法:K-means
在机器学习领域中,聚类算法被广泛应用于数据分析和模式识别。K-means 是其中一种常用的聚类算法,它能够将数据集分成 K 个不同的组或簇。本文将详细介绍 K-means 算法的原理、实现步骤以及如何使用 Python 进行编程实践。 什么是 K-means? K-means 是一种基于距离的聚类算...
使用phyon实现K-means聚类算法
K-means聚类算法是一种常见的无监督学习算法,用于将数据集分成K个簇。以下是K-means聚类算法的原理: ### K-means聚类算法原理: 1. **初始化**:随机选择K个点作为初始质心(centroid)。 2. **分配数据点**:对于每个数...
从K-means到高斯混合模型:常用聚类算法的优缺点和使用范围?
一、引言 聚类算法是一种无监督学习方法,旨在将相似的数据点分组成为若干个簇,使得同一簇内的数据点相似度高,不同簇之间的相似度低。聚类算法在数据挖掘、模式识别、图像分析等领域具有重要应用。 聚类算法的作用在于发现数据的内在结构和规律,将数据进行分组,从而帮助我们理解数据的特征和相互关系。聚类可以用于数...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









