数据挖掘实战:基于KMeans算法对超市客户进行聚类分群
一、研究背景 超市作为零售业的主要形式之一,在现代都市生活中扮演着重要角色。随着社会经济的发展和消费者需求的变化,超市经营者越来越意识到了客户细分的重要性。不同的客户群体有着不同的购物习惯、消费行为和偏好,了解并满足不同客户群体的需求,可以帮助超...

基于TF-IDF+KMeans聚类算法构建中文文本分类模型(附案例实战)
1.TF-IDF算法介绍 TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或...


用户画像之KMeans 算法解释及项目中用到的算法
4个挖掘类型标签,涉及到2个算法:K-Means是一种非常常见的聚类算法。在处理聚类任务中经常使用,K-Means算法是一种 原型 聚类算法。何为原型聚类呢?算法 首先对原型进行初始化,然后对原型进行迭代更新求解,采用不同的原型表示、不同的求解方式,将产生不同的求解方式。基于Kmeans+Canop...
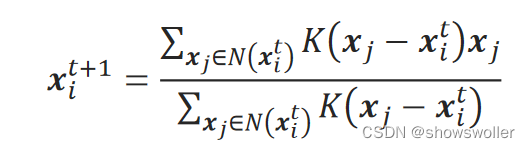
【Python机器学习】Mean Shift、Kmeans聚类算法在图像分割中实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~Mean Shift算法是根据样本点分布密度进行迭代的聚类算法,它可以发现在空间中聚集的样本簇。簇中心是样本点密度最大的地方。Mean Shift算法寻找一个簇的过程是先随机选择一个点作为初始簇中心,然后从该点开始,始终向密度大的方向持续迭代前进,...

C# | KMeans聚类算法的实现,轻松将数据点分组成具有相似特征的簇
C# KMeans聚类算法的实现 @[toc] 前言 本章分享一下如何使用C#实现KMeans算法。在讲解代码前先清晰两个小问题: 什么是聚类?聚类是将数据点根据其相似性分组的过程,它有很多的应用场景,比如:图像分割、文本分类、推荐系统等等。在这些应用场景里面我们需要将数据点分成多个簇,每个簇内的数...
09 机器学习 - Kmeans聚类算法案例
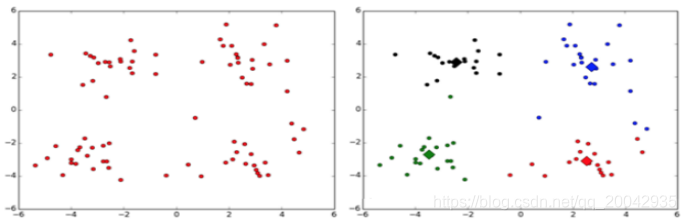
1. 需求对给定的数据集进行聚类本案例采用二维数据集,共80个样本,有4个类。样例如下(testSet.txt):1.658985 4.285136 -3.453687 3.424321 4.838138 -1.151539 -5.379713 -3.362104 0.972564 2...

08 机器学习 - Kmeans聚类算法原理
1.概述K-means算法是集简单和经典于一身的基于距离的聚类算法采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为类簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。2 算法图示假设我们的n个样本点分布在图中所示的二维空间。从数据点的大致形状可以看出...

KMeans算法全面解析与应用案例
本文深入探讨了KMeans聚类算法的核心原理、实际应用、优缺点以及在文本聚类中的特殊用途,为您在聚类分析和自然语言处理方面提供有价值的见解和指导。关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认...

Kmeans聚类算法效果评价方式
Kmeans评价:a)原始数据有标签: b)原始数据无标签:轮廓系数: 轮廓系数越大,聚类效果越好 b:类间距离 a:类内距离kaggle竞赛之路P86手肘法:(所属类簇的平均距离)计算方式一:计算方式二:模型自带参数:特点:K值的选取:轮廓系数,手肘画图,谱系聚类画图

kmeans算法入门案例以聚类中心数的确定
kmeans案例分析kmeans具体流程第一步:指定聚类类数k(文章后面会讲解k的选择方法)第二步:选定初始化聚类中心。随机或指定k个对象,作为初始化聚类中心第三步:得到初始化聚类结果。计算每个对象到k个聚类中心的距离,把每个对象分配给离它最近的聚类中心所代表的类别中,全部分配完毕即得...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









