[帮助文档] 使用DeepGPU-LLM实现大语言模型在GPU上的推理优化_GPU云服务器(EGS)
在处理大语言模型任务中,您可以根据实际业务部署情况,选择在不同环境(例如GPU云服务器环境或Docker环境)下安装推理引擎DeepGPU-LLM,然后通过使用DeepGPU-LLM工具实现大语言模型(例如Llama模型、ChatGLM模型、百川Baichuan模型或通义千问Qwen模型)在GPU上...

Bert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)
对于深度学习初学者来说,JupyterNoteBook的脚本运行形式显然更加友好,依托Python语言的跨平台特性,JupyterNoteBook既可以在本地线下环境运行,也可以在线上服务器上运行。GoogleColab作为免费GPU算力平台的执牛耳者,更是让JupyterNoteBook的脚本运行...
[帮助文档] 大语言模型( LLM)推理引擎DeepGPU-LLM_GPU云服务器(EGS)
DeepGPU-LLM是阿里云研发的基于GPU云服务器的大语言模型(Large Language Model,LLM)推理引擎,在处理大语言模型任务中,该推理引擎可以为您提供高性能的大模型推理服务。

小羊驼背后的英雄,伯克利开源LLM推理与服务库:GPU减半、吞吐数十倍猛增
大模型时代,各种优化方案被提出,这次吞吐量、内存占用大等问题被拿下了。随着大语言模型(LLM)的不断发展,这些模型在很大程度上改变了人类使用 AI 的方式。然而,实际上为这些模型提供服务仍然存在挑战,即使在昂贵的硬件上也可能慢得惊人。现在这种限制正在被打破。最近,来自加州大学伯克利分校...

推理速度数倍提升,大幅简化多GPU后端部署:Meta发布全新推理引擎AITemplate
t刚刚,Meta 发布了革命性的推理引擎 AITemplate。测试结果显示,相比 PyTorch Eager,AITemplate 在 NVIDIA GPU 上实现了最高 12 倍的性能提升,在 AMD GPU 上实现了高达 4 倍的性能提升。众所周知,GPU 在各种视觉、自然语言和多模态模型推理...
用pipeline做推理的时候,怎么让其使用GPU?
我按照官网给的案例,利用pipeline获取UniASR语音识别-中文-通用-16k-实时这个模型做推理,但是程序跑出来并没有利用GPU还依然是用的CPU,所以想问各位大佬怎么选择用GPU做pipeline的推理呢?
请问ModelScope为什么每推理一次,都要重新加载一次gpu呢?
请问ModelScope为什么每推理一次,都要重新加载一次gpu呢?scanmt中译英或者英译中模型,直接使用modelscape(0.4.7)按照模型介绍的代码规范在rtx2080上跑,每翻译一个句子,都重新加载gpu是为什么呢?

MNN推理引擎最新实测,CPU、GPU性能全面领先!
每当有深度学习框架开源时,我们也和广大的吃瓜群众一样,期冀着是不是能有一波新的浪潮,把端侧AI托上一个新的高度。但同时,出于同行们对MNN的认可,我们几乎每一次都会在对比的榜单上出镜,有时甚至是唯一竞对。高处不胜寒哪。 在正文之前,要先赞扬一下腾讯的开源精神。2017年,NCNN吹响了国内引擎开源的...
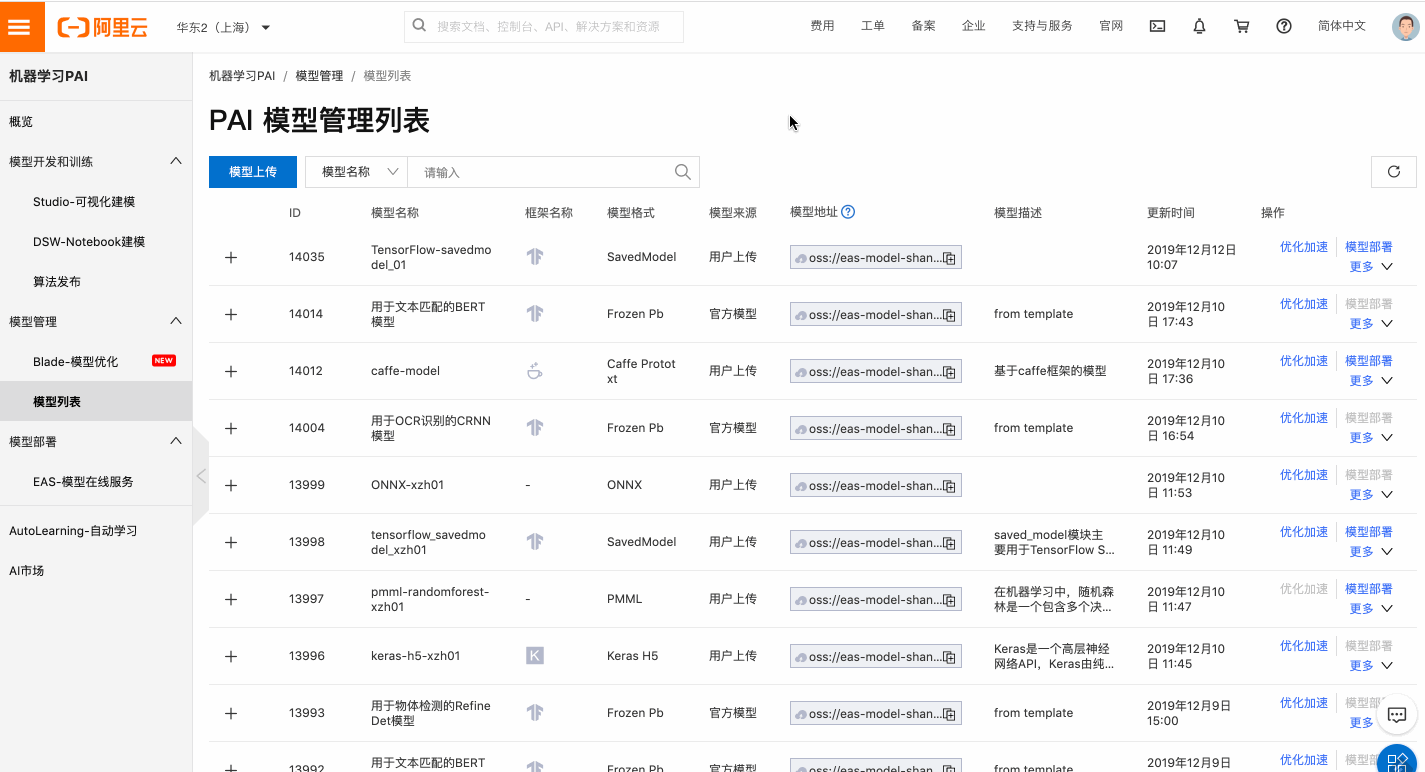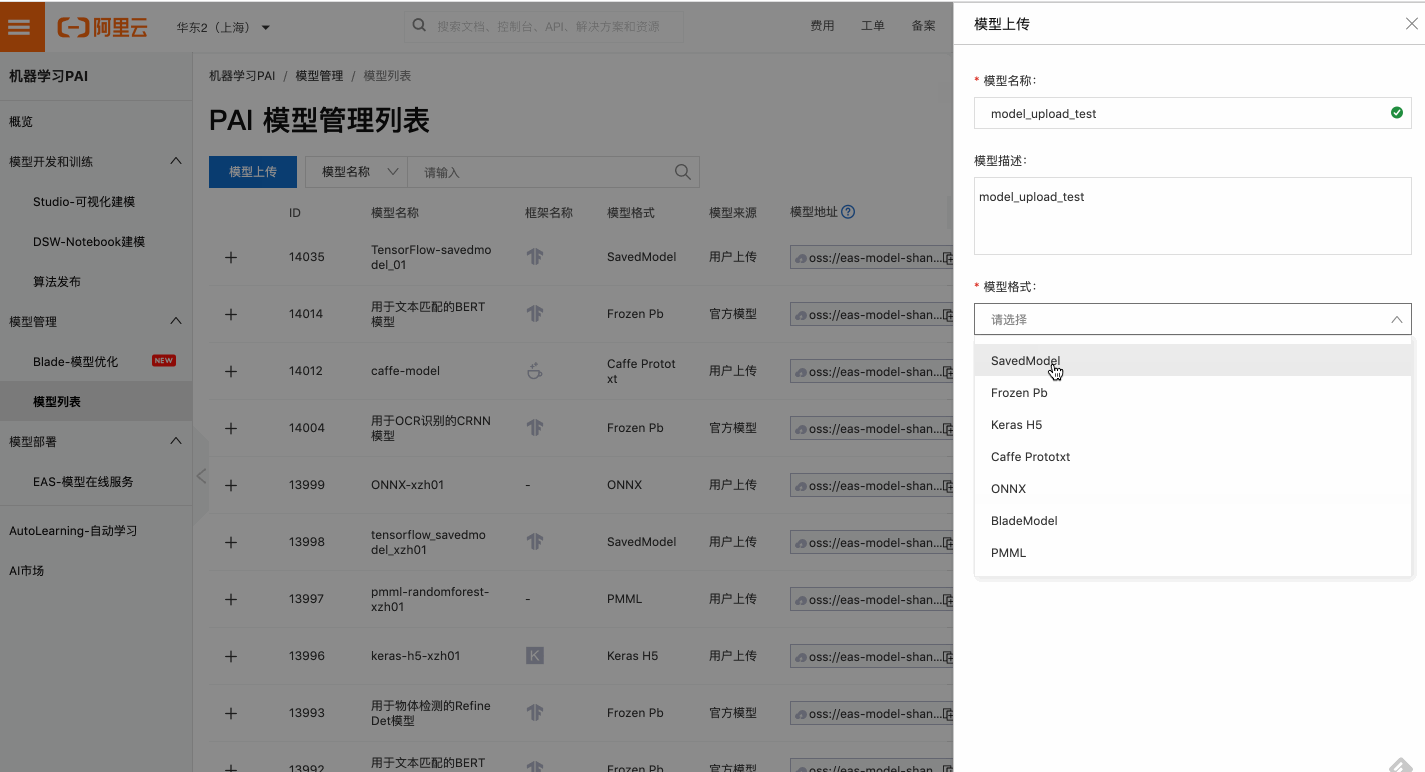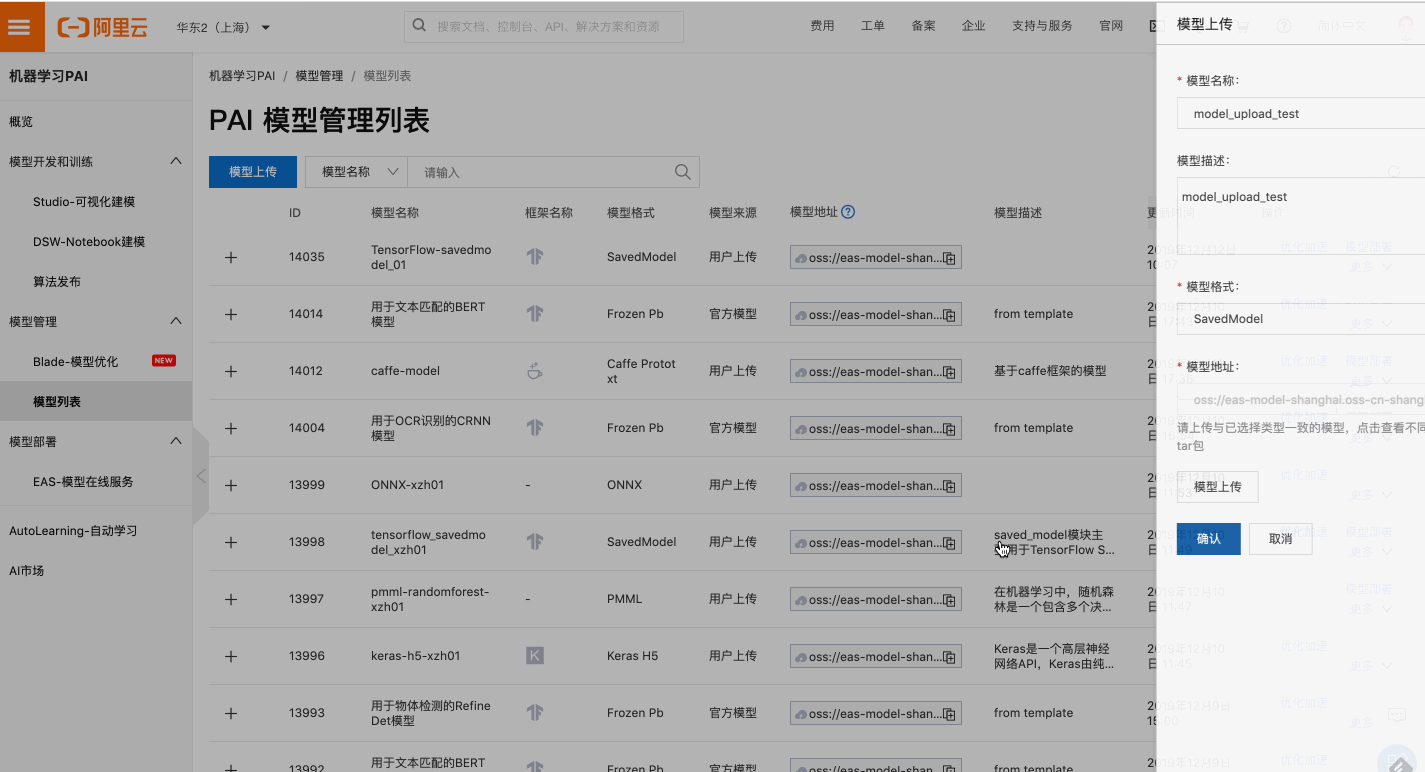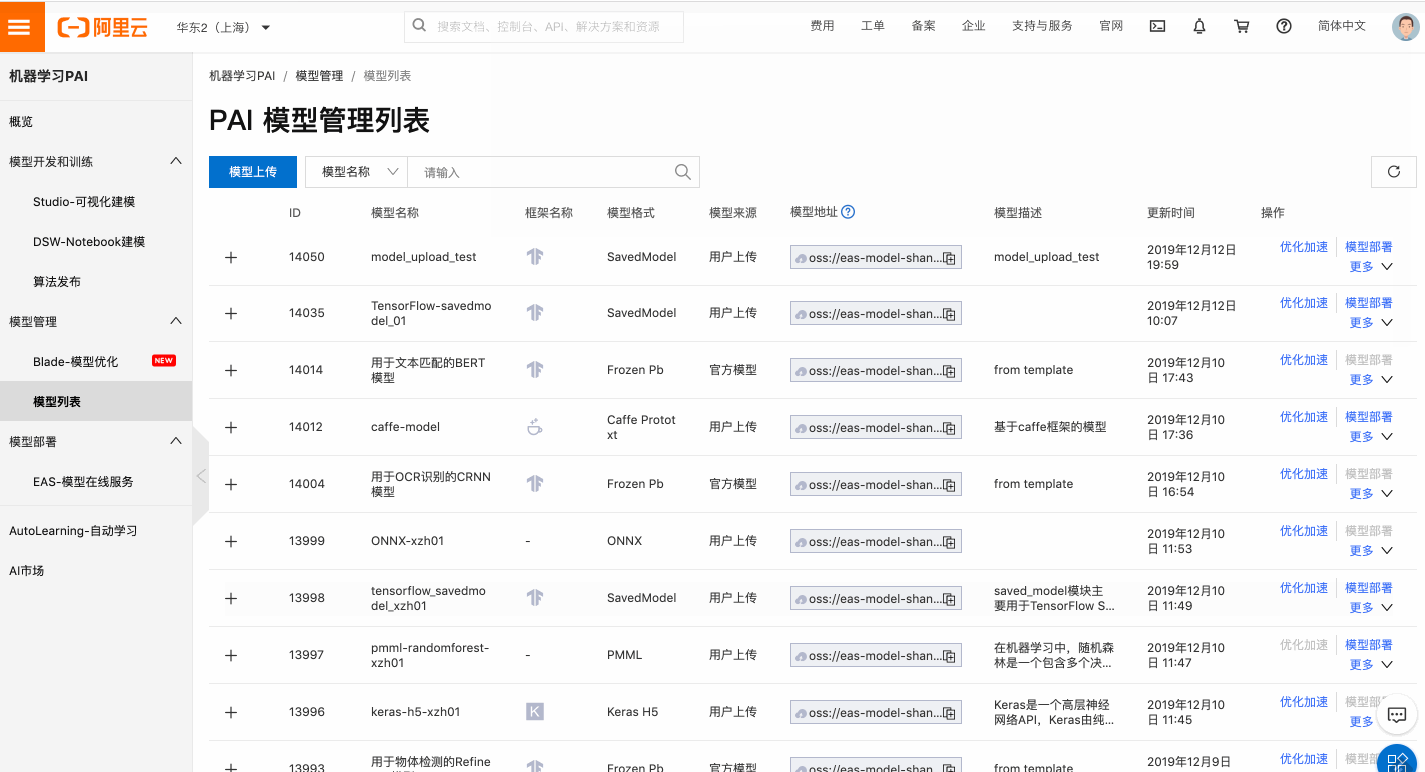
PAI年度巨献:在线推理加速优化,降低推理GPU所需资源
背景 在线推理是抽象的算法模型触达具体的实际业务的最后一公里,PAI已经对外推出了PAI-EAS在线模型服务,帮助大家解决模型服务化的问题,目前已经吸引数百家企业入驻。但是在这个环节中,仍然还有这些已经是大家共识的痛点和诉求: 1.任何线上产品的用户体验都与服务的响应时长成反比,复杂的模型如何极致地...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子



最佳实践
更多



