OpenAI要为GPT-4解决数学问题了:奖励模型指错,解题水平达到新高度
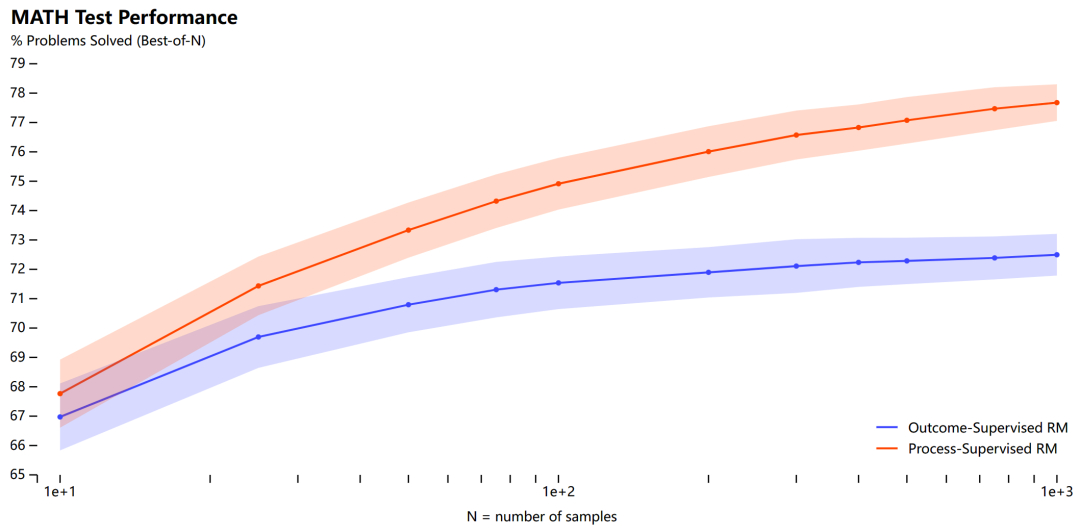
对于具有挑战性的 step-by-step 数学推理问题,是在每一步给予奖励还是在最后给予单个奖励更有效呢?OpenAI 的最新研究给出了他们的答案。现在,大语言模型迎来了「无所不能」的时代,其中在执行复杂多步推理方面的能力也有了很大提高。不过,即使是最先进的大模型也会产生逻辑错误,通常称为幻觉。因...
从一个失败的强化学习训练说起:OpenAI 探讨应该如何设计奖励函数?
在当下,强化学习算法以一种惊奇、不可思议的方式进入到了我们的视野中。雷锋网(公众号:雷锋网)此前也做过不少相关的覆盖和报道,而在 OpenAI 的这篇文章中,Dario Amodei 与 Jack Clark 将会探讨一个失败的强化学习模型。这个模型为何失败?原因就在于你没有指明你的奖励函数。雷锋网...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。