【大数据技术Spark】Spark SQL操作Dataframe、读写MySQL、Hive数据库实战(附源码)
需要源码和依赖请点赞关注收藏后评论区留言私信~~~一、Dataframe操作步骤如下1)利用IntelliJ IDEA新建一个maven工程,界面如下2)修改pom.XML添加相关依赖包3)在工程名处点右键,选择Open Module Settings4)配置Scala Sdk,界面如下5)新建文件...
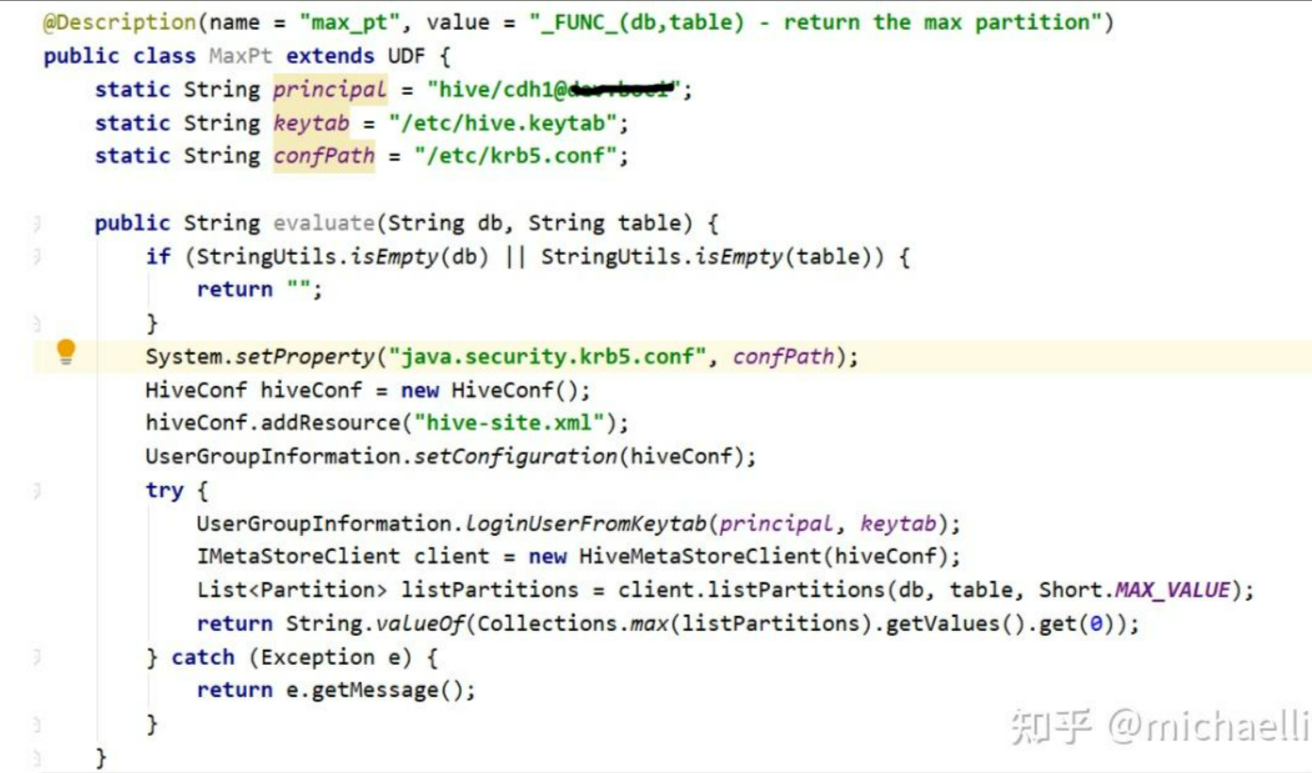
浅析 hive udaf 的正确编写方式- 论姿势的重要性-系列四-如何直接访问metastore service(附源码)
前言大家好,我是明哥。HIVE 作为大数据生态的数仓解决方案,因为历史的原因在很多行业很多公司都有着广泛的应用。对于比较复杂的业务逻辑,HIVE SQL 往往比较难以表达,此时大家在开发中往往会辅以 HIVE UDF。所以充分理解和掌握 HIVE UDF正确的表写和使用方式,是大数据从业人员必不可少...

Hive简介及源码编译
Hive简介:Hive是一个基于Hadoop的数据仓库,可以将结构化数据映射成一张表,并提供类SQL的功能,最初由Facebook提供,使用HQL作为查询接口、HDFS作为存储底层、MapReduce作为执行层,设计目的是让SQL技能良好,但Java技能较弱的分析师可以查询海量数据,2...
hive变量传递的源码实现
用过hive的人都知道,可以通过在cli向hive传递参数,变量等,这里其实是通过下面两个类实现的。 1 2 org.apache.hadoop.hive.ql.processors.SetProcessor类 org.apache.hadoop.hive.ql.parse.Varia...
Hive metastore源码阅读(三)
上次写了hive metastore的partition的生命周期,但是简略概括了下alter_partition的操作,这里补一下alter_partition,因为随着项目的深入,发现它涉及的地方较多,比如insert into 时如果路径存在情况下会调用alter_partition,调用...
Hive metastore源码阅读(二)
最近随着项目的深入,发现hive meta有些弊端,就是你会发现它的元数据操作与操作物理集群的代码耦合在一起,非常不利于扩展。比如:在create_table的时候同时进行路径校验及创建,如下代码: 1 if (!TableType.VIRTUAL_VIEW.toString().equals(...
Hive metastore源码阅读(一)
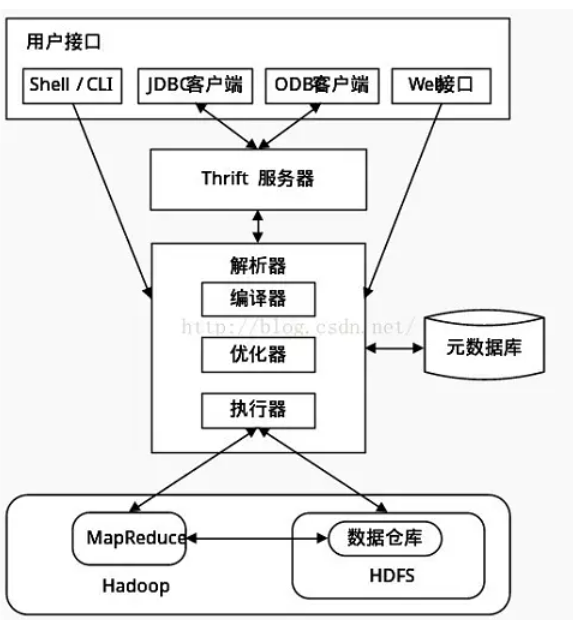
不要问我为什么,因为爱,哈哈哈哈。。。进入正题,最近做项目顺带学习了下hive metastore的源码,进行下知识总结。 hive metastore的整体架构如图: 一、组成结构: 如图我们可以看到,hive metastore的组成结构分为 客户端 服务端 ,那么下来我们...
Hive源码编译及阅读修改调试
下载编译 在git上下载合适的master分支,使用maven编译。执行编译的目的在于,确保过程中生成的代码(Thrift)已经生成,这样导入IDEA就不会出现有些类找不到的情况。 执行源码编译分发命令,进入源码根目录执行: mvn clean package -Pha...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。