scikit-learn的cluster模块中提供KMeans类实现K-均值聚类会使用什么参数?
scikit-learn的cluster模块中提供KMeans类实现K-均值聚类会使用什么参数?
scikit-learn的cluster模块中提供KMeans类实现K-均值聚类时的init
使用scikit-learn的cluster模块中提供KMeans类实现K-均值聚类时里面的init属性有哪些可选值呀?

怎么使用scikit-learn的cluster模块中提供KMeans类实现K-均值聚类呢?
怎么使用scikit-learn的cluster模块中提供KMeans类实现K-均值聚类呢?
全面解析Kmeans聚类(Python)
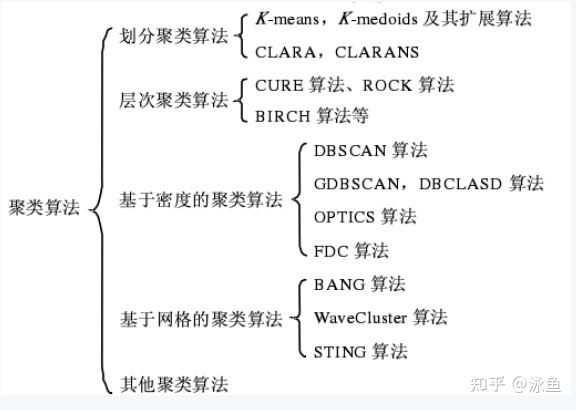
一、聚类简介Clustering (聚类)是常见的unsupervised learning (无监督学习)方法,简单地说就是把相似的数据样本分到一组(簇),聚类的过程,我们并不清楚某一类是什么(通常无标签信息),需要实现的目标只是把相似的样本聚到一起,即只是利用样本数据...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







