[帮助文档] 基于Hadoop集群支持Delta Lake或Hudi存储机制
Delta Lake和Hudi是数据湖方案中常用的存储机制,为数据湖提供流处理、批处理能力。MaxCompute基于开源的Hadoop集群提供了支持Delta或Hudi存储机制的湖仓一体架构。您可以通过MaxCompute查询到实时数据,即时洞察业务数据变化。
![✨[hadoop3.x]新一代的存储格式Apache Arrow(四)](https://ucc.alicdn.com/pic/developer-ecology/zpiaduicf3hfi_7c48bd54d8ff43f18623928997460e39.jpeg)
✨[hadoop3.x]新一代的存储格式Apache Arrow(四)
历史文章[hadoop3.x系列]HDFS REST HTTP API的使用(一)WebHDFS[hadoop3.x系列]HDFS REST HTTP API的使用(二)HttpFS[hadoop3.x系列]Hadoop常用文件存储格式及BigData File Viewer工具的使用(三)✨[ha...

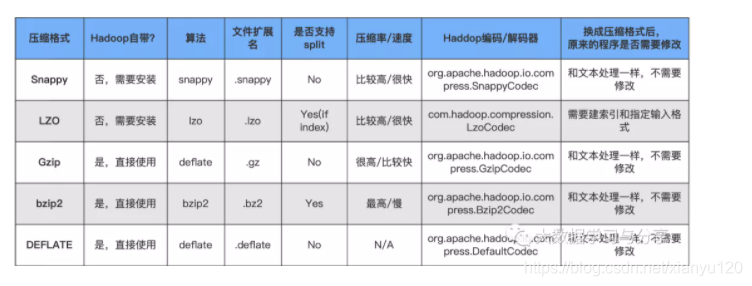
hadoop中压缩及存储常见格式图解
常见的压缩格式:Snappy,LZO,Gzip,bzip2,deflate常见的存储格式:储存格式指的是Hdfs 中存储文件的格式,常用的有SequnceFile、RCFile、Parquet和TextFileSequnceFileRCFile:ORCFile:Parquet :
[帮助文档] 如何使用一个Hadoop集群为所有项目创建计算源从而提供计算与存储资源
概述本文为您介绍Dataphin如何使用一个Hadoop集群为所有项目创建计算源从而提供计算与存储资源。详细信息1.Dataphin一个计算源只可以被一个项目所绑定。2.通过创建不同的Hive DB从而创建不同的计算源来达到一个Hadoop集群创建多个计算源从而为不同的项目提供存储和计算的需求。适用...
Hadoop-No.3之序列化存储格式
序列化存储指的是将数据结构转化为字节流的过程,一般用于数据存储或者网络传输.与之相反, 反序列化是将字节流转化为数据结果的过程.序列化是分布处理系统(比如Hadoop)的核心,原因在于他能对数据进行转化,形成一种格式.使用了这样的格式之后,数据可以有效的存储,也能通过网络连接进行传输.序列化通常与分...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









hadoop您可能感兴趣
- hadoop集群
- hadoop flink
- hadoop secondarynamenode
- hadoop硬件
- hadoop hdfs
- hadoop高可靠
- hadoop sql
- hadoop产品
- hadoop任务
- hadoop ecs
- hadoop大数据
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop spark
- hadoop分布式
- hadoop学习
- hadoop文件
- hadoop yarn
- hadoop hive
- hadoop搭建
- hadoop命令
- hadoop数据
- hadoop hbase
- hadoop系统
- hadoop部署
- hadoop运行
- hadoop启动