
大数据问题排查系列 - SPARK STANDALONE HA 模式的一个缺陷点与应对方案
前言大家好,我是明哥!作为当今离线批处理模式的扛把子,SPARK 在绝大多数公司的数据处理平台中都是不可或缺的。而在底层使用的具体资源管理器上,SPARK 支持四种模式:standaloneyarnmesoskubernetes四种模式的简单对比如下图:以上四种模式中,mesos 在业界使用的最少&...
大数据 | Hadoop HA高可用搭建保姆级教程(大二学长的万字笔记)(下)
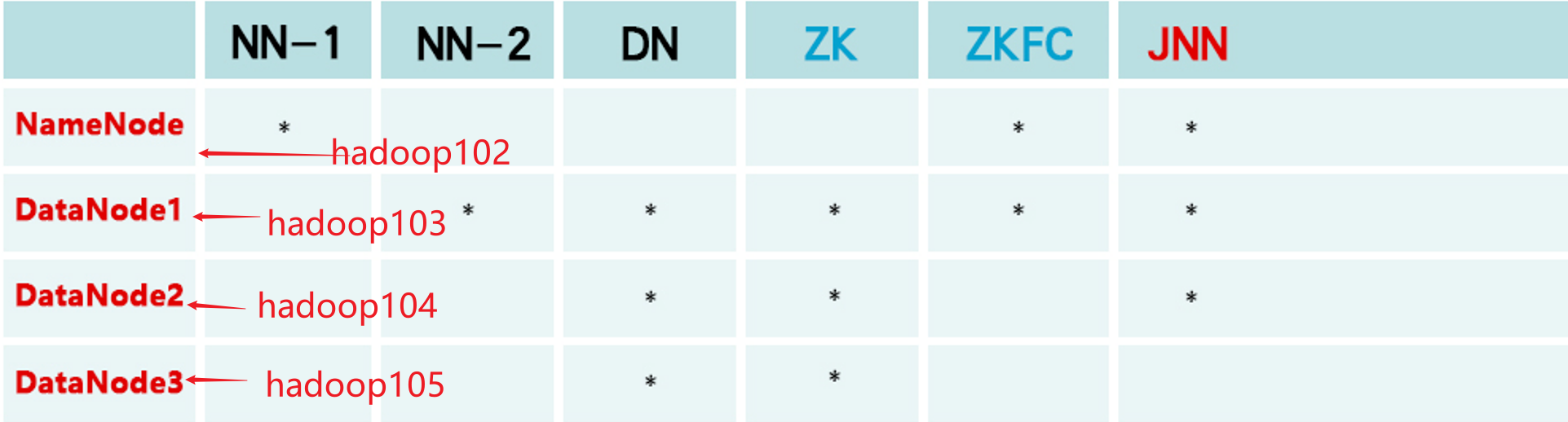
七、检验集群✨7.1 jps检查使用jpsall脚本分别查看四个节点上的jps进程信息,是否和集群规划相符,集群规划图再放一遍:jpsall和集群规划完全一致!7.2 网页检查分别访问NameNode1和NameNode2的两个Web页面,网址是http://hadoop102:9870,http:...


大数据 | Hadoop HA高可用搭建保姆级教程(大二学长的万字笔记)(上)
一、写在前面🎈大家好!我是初心,今天给大家带来的是Hadoop HA搭建保姆级教程,来自大二学长的万字长文自述和笔记!相信很多人看到这个标题时,可能会产生一种疑问:博主你之前不是出过一期关于Hadoop HA高可用集群搭建的教程了吗,这次怎么还出一篇?是有什么改进的地方...
好程序员大数据教程Hadoop全分布安装(非HA)
机器名称 启动服务 linux11 namenode secondrynamenode datanode linux12 datanode linux13 datanode 第一步:更改主机名,临时修改+永久修改 临时修改:hostname linux11 永久修改: v...

大数据分布式架构单点故障详解(Hdfs+Yarn+HBase+Spark+Storm)构建HA高可用架构
本文来源于公众号【胖滚猪学编程】,转载请注明出处。 本文整合梳理了主流大数据生态圈中的组件:Hdfs+Yarn+HBase+Spark+Storm的单点故障问题的解决方案:构建HA(High Available)高可用架构。阅读本文之前,最好需要了解清楚各组件的架构原理。 单点故障的出现原因 首先一...
大数据||启动HDFS HA的守护进程
请先参看规划HA的分布式集群服务器HDFS HA配置详解 一定要严格按照顺序执行 严格按照顺序执行 说明:如果不安装启动顺序来就会出现,第五步的错误。切记需要把journalnode所有的节点启动完毕。要不就会出现 Active切换出错 启动顺序 Step1 :在各个JournalNode节点上,输...
大数据||HDFS HA配置详解
根据HA架构图,规划HA的分布式集群服务器 HA集群规划 配置参考图 根据官方文档配置HA 部分说明 Architecture 在典型的ha集群中,两台独立的机器被配置为namenode。在任何时间点,一个namenodes处于活动状态,另一个处于备用状态。活动NameNode负责集群中的所有客户端...
大数据||HDFS HA 设计
背景 Hadoop 2.0 之前,在HDFS 集群中 NameNode 存在单点故障(SPOF )。对于只有一个NameNode 的集群,若NameNode 机器出现故障,则整个集群将无法使用,直到NameNode 重新启动。 NameNode 主要在以下两个方面影响HDFS 集群 NameNode...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute实例id
- 云原生大数据计算服务 MaxCompute日期格式
- 云原生大数据计算服务 MaxCompute在建
- 云原生大数据计算服务 MaxCompute client
- 云原生大数据计算服务 MaxCompute openapi
- 云原生大数据计算服务 MaxCompute quickbi
- 云原生大数据计算服务 MaxCompute区分
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute字符
- 云原生大数据计算服务 MaxCompute工单
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute产品