[帮助文档] 通过实时数据消费将Kafka数据写入AnalyticDB PostgreSQL
当您需要将Kafka数据写入AnalyticDB PostgreSQL版,且不希望使用其他数据集成工具时,可以通过实时数据消费功能直接消费Kafka数据,减少实时处理组件依赖,提升写入吞吐。
[帮助文档] 如何配置Kafka输出组件用于向数据源写入数据
配置Kafka输出组件,可以将外部数据库中读取数据写入到Kafka,或从大数据平台对接的存储系统中将数据复制推送至Kafka,进行数据整合和再加工。本文为您介绍如何配置Kafka输出组件。

flink sql数据写入kafka,会出现key为before、after及op,怎么把这些去掉?
flink sql数据写入kafka,会出现key为before、after及op,怎么把这几个去掉?我写入的数据直接是json格式
FlinkSql在进行窗口聚合的时候,出现无数据情况,kafka消息频率每秒50条
大佬们,求助,使用的版本1.13, 建表如下图中, 但是聚合的时候:SELECT window_start, window_end, COUNT(data) as num FROM TABLE(TUMBLE(TABLE line_kafka_source, DESCRIPTOR(event_time...
Flink CDC里有没有什么方法 oss 实时同步数据到kafka?
Flink CDC里有没有什么方法 oss 实时同步数据到kafka?
[帮助文档] 使用Confluent Replicator复制数据_云消息队列 Confluent 版_云消息队列 Kafka 版(Kafka)
Kafka MirrorMaker是一款用于在两个Apache Kafka集群之间复制数据的独立工具。它将Kafka消费者和生产者连接在一起。从源集群的Topic读取数据,并写入目标集群的同名Topic。相比于Kafka MirrorMaker,Confluent Replicator是一个更完整的...
[帮助文档] 使用Replicator跨集群复制数据_云消息队列 Confluent 版_云消息队列 Kafka 版(Kafka)
本文描述了如何启动两个Apache Kafka集群,然后启动一个Replicator进程在它们之间复制数据。
[帮助文档] 使用Cluster Linking复制Kafka集群数据_云消息队列 Confluent 版_云消息队列 Kafka 版(Kafka)
Cluster Linking是Confluent Platform提供的一种功能,用于将多个Kafka集群连接在一起。该功能允许不同的Kafka集群之间进行数据的镜像和复制。Cluster Linking将在数据目标(Destination)集群启动,并复制数据源(Source)集群的数据到目标集...
Flink CDC里问下增量数据可以不写进kafka,直接写进下游数据库吗?
Flink CDC里问下增量数据可以不写进kafka,直接写进下游数据库吗?
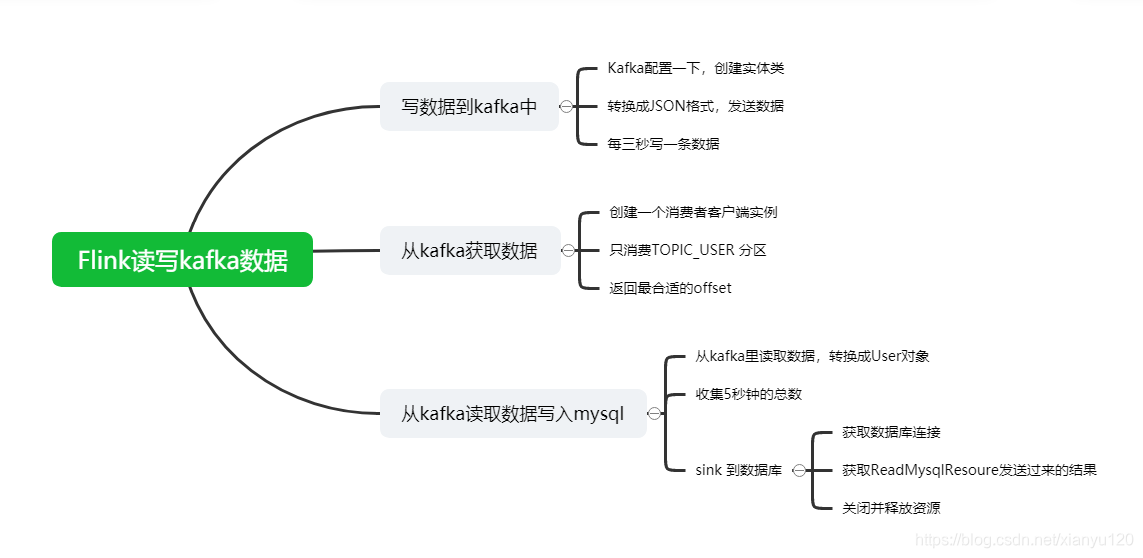
Flink最后一站___Flink数据写入Kafka+从Kafka存入Mysql
前言大家好,我是ChinaManor,直译过来就是中国码农的意思,我希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。今天为大家带来Flink的一个综合应用案例:Flink数据写入Kafka+从Kafka存入Mysql第一部分:写数据到kafka中public stati...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。






云消息队列 Kafka 版数据相关内容
- hologres云消息队列 Kafka 版数据
- 云消息队列 Kafka 版producer生产数据
- 云消息队列 Kafka 版producer数据
- 云消息队列 Kafka 版生产数据
- 云消息队列 Kafka 版数据持久化
- 报错云消息队列 Kafka 版数据
- 数据云消息队列 Kafka 版op
- cdc数据云消息队列 Kafka 版
- 实时同步数据云消息队列 Kafka 版
- 云消息队列 Kafka 版数据doris
- 同步云消息队列 Kafka 版数据
- cdc云消息队列 Kafka 版数据
- 云消息队列 Kafka 版集群数据
- cdc mysql云消息队列 Kafka 版数据
- mysql云消息队列 Kafka 版数据
- cdc同步云消息队列 Kafka 版数据
- mysql-cdc云消息队列 Kafka 版数据
- 云消息队列 Kafka 版connector数据
- 云消息队列 Kafka 版聚合数据
- pai云消息队列 Kafka 版数据
- 云消息队列 Kafka 版consumer数据
- 连接云消息队列 Kafka 版数据
- 云消息队列 Kafka 版消费者数据
- flink云消息队列 Kafka 版数据
- 云消息队列 Kafka 版connect数据
- 云消息队列 Kafka 版数据hive
- flume云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据mysql
- 云消息队列 Kafka 版canal数据
- 代码云消息队列 Kafka 版数据
- 连接云消息队列 Kafka 版接收数据
- flink1.7云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据参数
- pyflink云消息队列 Kafka 版数据
- cdc数据云消息队列 Kafka 版分区
- 数据云消息队列 Kafka 版分区
- 捕获数据云消息队列 Kafka 版
- 数据云消息队列 Kafka 版接收
- 云消息队列 Kafka 版数据计算
- 云消息队列 Kafka 版数据es
- 云消息队列 Kafka 版数据hologres
- 云消息队列 Kafka 版数据清理
- 云消息队列 Kafka 版topic数据
- 云消息队列 Kafka 版类型数据
- 云消息队列 Kafka 版数据checkpoint
- 云消息队列 Kafka 版数据重启
- flume数据云消息队列 Kafka 版
- 云消息队列 Kafka 版数据类
云消息队列 Kafka 版更多数据相关
- 云消息队列 Kafka 版消费数据
- 云消息队列 Kafka 版数据信息
- canal数据云消息队列 Kafka 版
- 云消息队列 Kafka 版数据报错
- binlog云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据open方法
- 作业处理云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据保存
- storm云消息队列 Kafka 版数据
- spark云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据日志
- 云消息队列 Kafka 版数据算子
- 想用数据云消息队列 Kafka 版
- flume数据hdfs云消息队列 Kafka 版区别缓存
- canal云消息队列 Kafka 版数据
- 云消息队列 Kafka 版连接器数据
- 实时计算flink数据云消息队列 Kafka 版表
- 全量云消息队列 Kafka 版数据
- 云消息队列 Kafka 版数据task
- 同步数据云消息队列 Kafka 版
- upsert云消息队列 Kafka 版数据
- canal云消息队列 Kafka 版数据信息
- 云消息队列 Kafka 版数据性能
- 云消息队列 Kafka 版数据延迟
- 云消息队列 Kafka 版同步数据数据
云消息队列 Kafka 版您可能感兴趣
- 云消息队列 Kafka 版python
- 云消息队列 Kafka 版hologres
- 云消息队列 Kafka 版java
- 云消息队列 Kafka 版字段
- 云消息队列 Kafka 版flink
- 云消息队列 Kafka 版mysql
- 云消息队列 Kafka 版功能
- 云消息队列 Kafka 版阿里云
- 云消息队列 Kafka 版组件
- 云消息队列 Kafka 版cdc
- 云消息队列 Kafka 版消费
- 云消息队列 Kafka 版分区
- 云消息队列 Kafka 版集群
- 云消息队列 Kafka 版配置
- 云消息队列 Kafka 版报错
- 云消息队列 Kafka 版同步
- 云消息队列 Kafka 版apache
- 云消息队列 Kafka 版安装
- 云消息队列 Kafka 版消息队列
- 云消息队列 Kafka 版topic
- 云消息队列 Kafka 版消息
- 云消息队列 Kafka 版sql
- 云消息队列 Kafka 版入门
- 云消息队列 Kafka 版消费者
- 云消息队列 Kafka 版实战
- 云消息队列 Kafka 版原理