[帮助文档] 于DLF数据入湖的MaxCompute湖仓一体实践
由于DLF中数据入湖功能已经停止更新,本文采用DataWorks数据集成的入湖方式,以MySQL数据入湖为例,为您介绍在MaxCompute中如何创建外部项目,并查询DLF中的表数据。
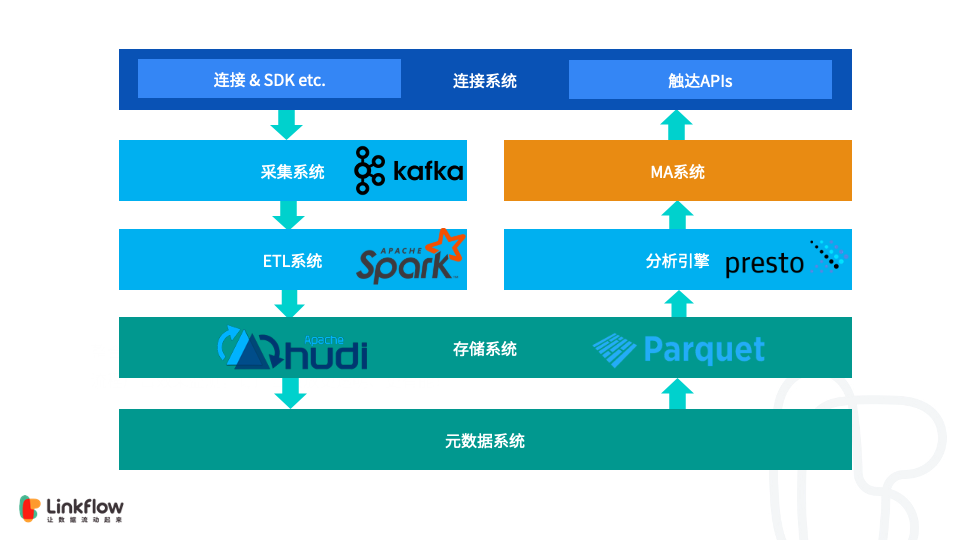
Apache Hudi在Linkflow构建实时数据湖的生产实践
1. 背景 Linkflow 作为客户数据平台(CDP),为企业提供从客户数据采集、分析到执行的运营闭环。每天都会通过一方数据采集端点(SDK)和三方数据源,如微信,微博等,收集大量的数据。这些数据都会经过清洗,计算,整合后写入存储。使用者可以通过灵活的报表或标签对持久化的数据进行分析和计算,结果又...

字节跳动基于Apache Hudi构建实时数据湖平台实践
一篇关于字节跳动基于 Apache Hudi 的实时数据湖平台的分享。 ...
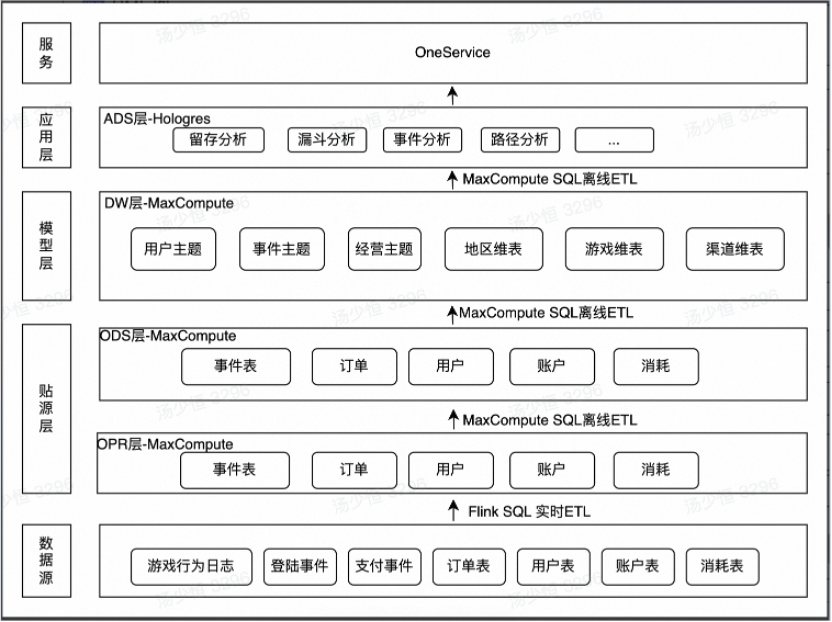
飞书深诺基于Flink+Hudi+Hologres的实时数据湖建设实践
01 背景介绍 飞书深诺集团致力于在出海数字营销领域提供全链路服务产品,满足不同企业的全球化营销需求。在广告效果监控和游戏运营业务场景中,为了及时响应广告投放成效与消耗方面的问题和快速监测运营动作效果,实时或准实时数据处理提供了至关重要的技术支撑。 通过对各个业务线实时需求的调研了解到,当前实时数据...
[帮助文档] 如何实现Flink+DLF数据入湖与分析
数据湖构建(DLF)可以结合阿里云实时计算Flink版(Flink VVP),以及Flink CDC相关技术,实现灵活定制化的数据入湖。并利用DLF统一元数据管理、权限管理等能力,实现数据湖多引擎分析、数据湖管理等功能。本文为您介绍Flink+DLF数据湖方案具体步骤。
[帮助文档] 如何借助日志服务将关系型数据库MySQL数据入湖和实践
本实践内容来自实战派,由阿里云专家创作,为您介绍如何借助日志服务将关系型数据库MySQL数据入湖和实践,并介绍数据在入湖之前可以日志服务可以提供哪些开箱即用的功能。

Apache Hudi 在 B 站构建实时数据湖的实践
本文作者喻兆靖,介绍了为什么 B 站选择 Flink + Hudi 的数据湖技术方案,以及针对其做出的优化。主要内容为:传统离线数仓痛点数据湖技术方案Hudi 任务稳定性保障数据入湖实践增量数据湖平台收益社区贡献未来的发展与思考GitHub 地址 https://github.com/apache/...
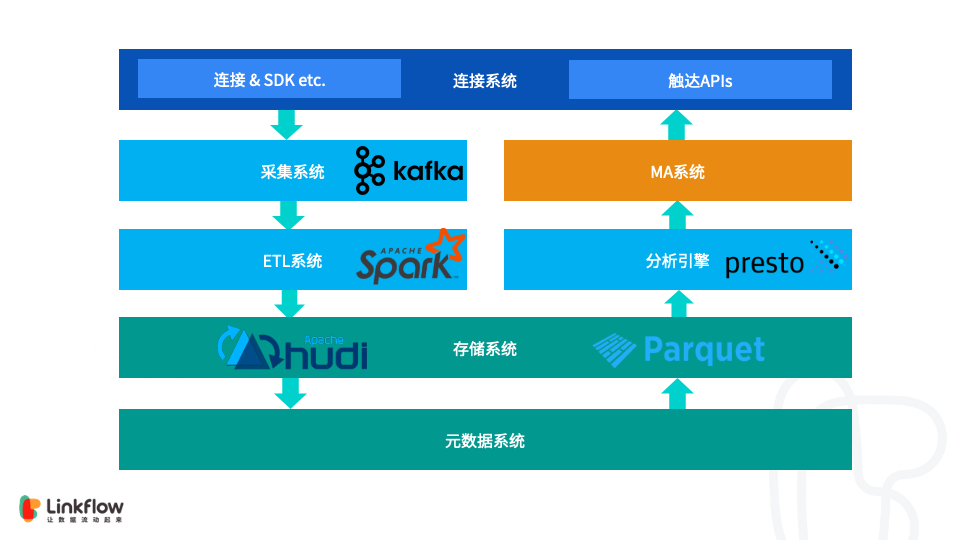
Flink + Hudi 在 Linkflow 构建实时数据湖的生产实践
可变数据的处理一直以来都是大数据系统,尤其是实时系统的一大难点。在调研多种方案后,我们选择了 CDC to Hudi 的数据摄入方案,目前在生产环境可实现分钟级的数据实时性,希望本文所述对大家的生产实践有所启发。内容包括:背景CDC 和数据湖技术挑战效果未来计划总结一、背景Linkflow 作为客户...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








