[帮助文档] 存算分离模式下借助本地缓存提升查询性能
EMR Serverless StarRocks 3.1.0版本正式支持存算分离模式。在该模式下计算和存储资源被解耦,极大地优化了资源利用效率和成本。为了进一步提升查询性能,该模式充分利用本地缓存技术,将热数据存储于计算节点的本地磁盘中。当查询请求命中本地缓存时,存算分离集群的查询性能与存算一体集群...
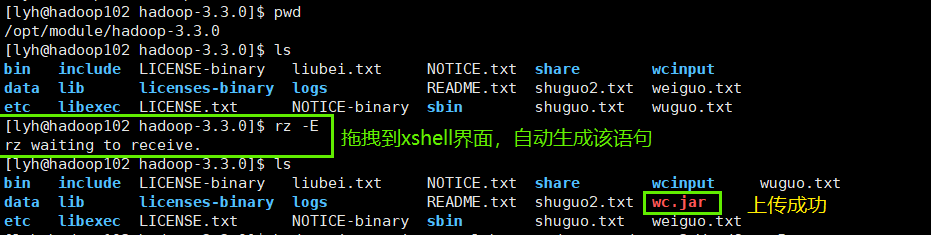
【集群模式】执行MapReduce程序-wordcount
因为是在hadoop集群下通过jar包的方式运行我们自己写的wordcount案例,所以需要传递的是 HDFS中的文件路径,所以我们需要修改上一节【本地模式】中 WordCountRunner类 的代码://5.设置统计文件输入的路径,将命令行的第一个参数作为输入文件的路径 FileInputFor...

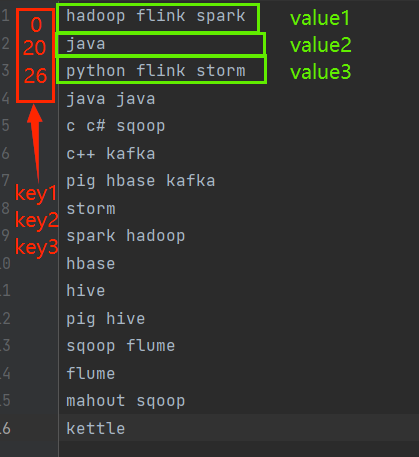
【本地模式】第一个Mapreduce程序-wordcount
【本地模式】:也就是在windows环境下通过hadoop-client相关jar包进行开发的,我们只需要通过本地自己写好MapReduce程序即可在本地运行。一个Maprduce程序主要包括三部分:Mapper类、Reducer类、执行类。map阶段:将每一行单词提取出来转为map(key,1)的...
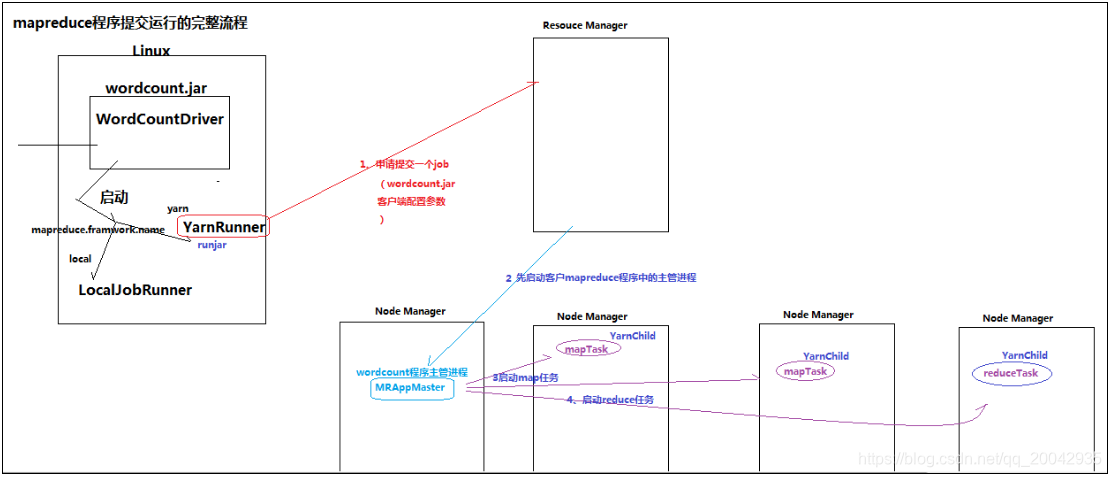
23 MAPREDUCE程序运行模式
本地运行模式1)mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行2)而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上3)怎样实现本地运行?写一个程序,不要带集群的配置文件(本质是你的mr程序的conf中是否有mapreduce.framework.na...
阿里云E-MapReduce在初始化 FileSystem 过程中有啥 参数可以设置 开启缓存模式?
阿里云E-MapReduce在初始化 FileSystem 过程中有啥 参数可以设置 开启 缓存模式?
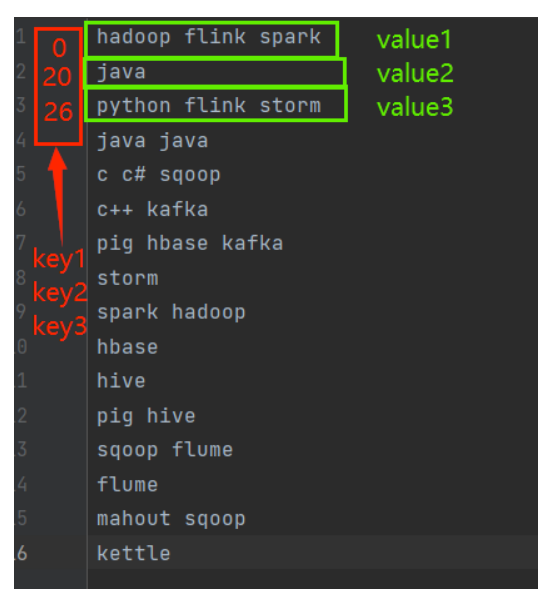
【本地模式】第一个Mapreduce程序-wordcount
【本地模式】:也就是在windows环境下通过hadoop-client相关jar包进行开发的,我们只需要通过本地自己写好MapReduce程序即可在本地运行。一个Maprduce程序主要包括三部分:Mapper类、Reducer类、执行类。map阶段:将每一行单词提取出来转为map(key,1)的...
[帮助文档] 访问ClickHouse集群的方式有哪些
访问E-MapReduce(简称EMR)上的ClickHouse集群支持通过原生JDBC访问和通过负载均衡SLB访问两种方式。本文为您介绍如何通过这两种方式访问ClickHouse集群。
E-MapReduce block模式如何向JindoFS上传写入文件
E-MapReduce block模式如何向JindoFS上传写入文件
[帮助文档] 如何使用JindoFS的缓存模式
缓存模式(Cache)主要兼容原生OSS存储方式,文件以对象的形式存储在OSS上,每个文件根据实际访问情况会在本地进行缓存,提升EMR集群内访问OSS的效率,同时兼容了原有OSS原有文件形式,数据访问上能够与其他OSS客户端完全兼容。本文主要介绍JindoFS的缓存模式及其使用方式。
[帮助文档] JindoFS的namespace的存储模式支持哪些权限
本文介绍JindoFS的namespace的存储模式(Block或Cache)支持的文件系统权限功能。Block模式和Cache模式不支持切换。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
mapreduce您可能感兴趣
- mapreduce hive
- mapreduce oss
- mapreduce访问
- mapreduce配置
- mapreduce sdk
- mapreduce策略
- mapreduce优化
- mapreduce模型
- mapreduce编程
- mapreduce实战
- mapreduce hadoop
- mapreduce集群
- mapreduce hdfs
- mapreduce spark
- mapreduce maxcompute
- mapreduce程序
- mapreduce yarn
- mapreduce数据
- mapreduce运行
- mapreduce任务
- mapreduce wordcount
- mapreduce map
- mapreduce大数据
- mapreduce作业
- mapreduce案例
- mapreduce入门