MapReduce【MapTask和ReduceTask的工作机制】
MapTask工作机制Read阶段MapTask通过InputFormat获得的RecordReader,并调用RecordReader的read方法从输入InputSplit中解析出一个个key/value键值对。Map阶段该节点主要是将解析出的key/value交给用户编写的Mapper类的ma...
Hadoop中的MapReduce框架原理、Job提交流程源码断点在哪断并且介绍相关源码、切片与MapTask并行度决定机制、MapTask并行度决定机制
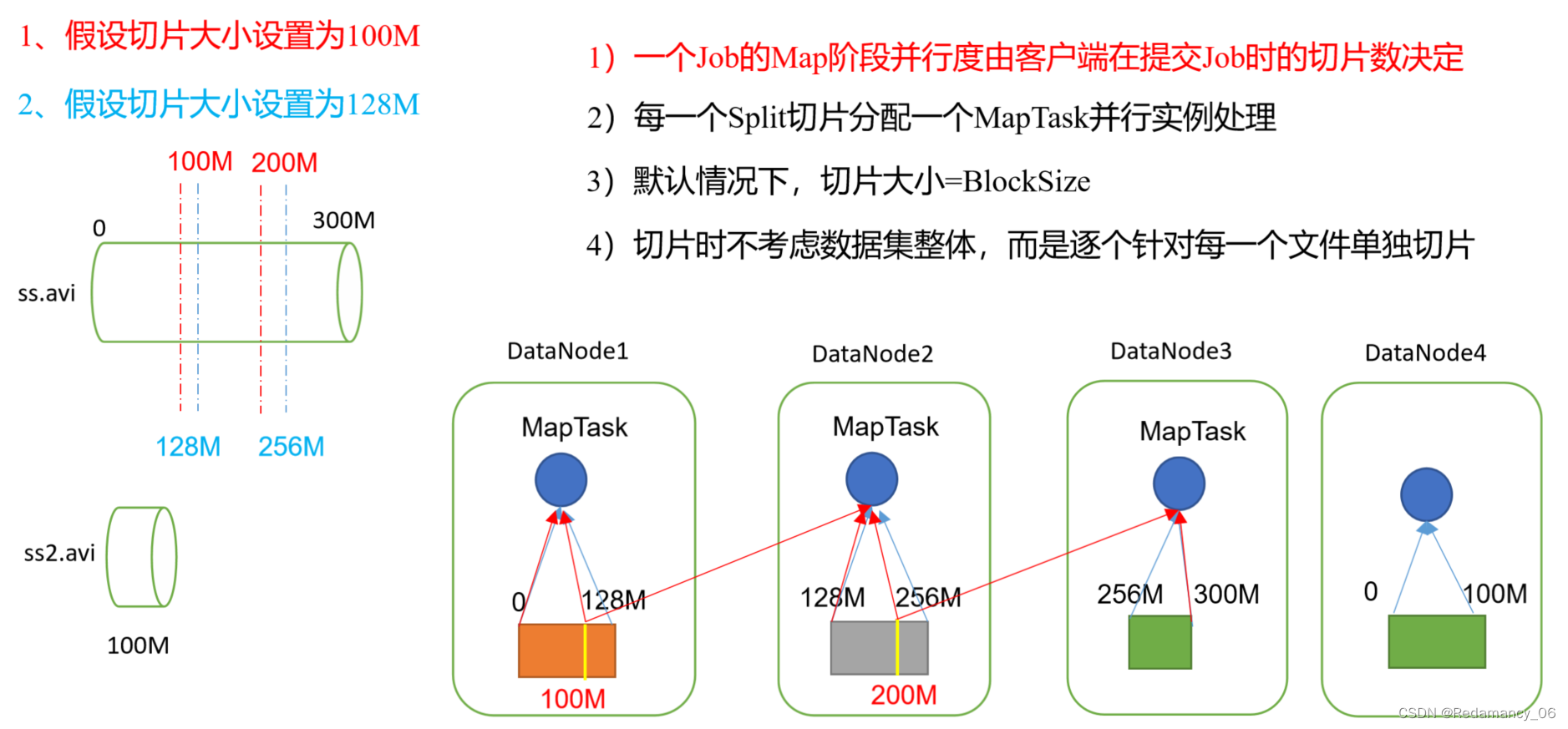
@[toc]13.MapReduce框架原理13.1InputFormat数据输入13.1.1切片与MapTask并行度决定机制13.1.1.1问题引出MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度 思考:1G的数据,启动8个MapTask,可以提高集群的...

MapReduce中MapTask工作机制中的溢写阶段详情是什么?
MapReduce中MapTask工作机制中的溢写阶段详情是什么?
MapReduce中MapTask工作机制中的Combine阶段的工作是什么?
MapReduce中MapTask工作机制中的Combine阶段的工作是什么?
MapReduce中MapTask工作机制中的Spill阶段的工作是什么?
MapReduce中MapTask工作机制中的Spill阶段的工作是什么?
MapReduce中MapTask工作机制中的Collect收集阶段的工作是什么?
MapReduce中MapTask工作机制中的Collect收集阶段的工作是什么?
MapReduce中MapTask工作机制中的Read阶段和Map阶段的工作是什么?
MapReduce中MapTask工作机制中的Read阶段和Map阶段的工作是什么?
MapReduce中的MapTask工作机制有哪些阶段?
MapReduce中的MapTask工作机制有哪些阶段?
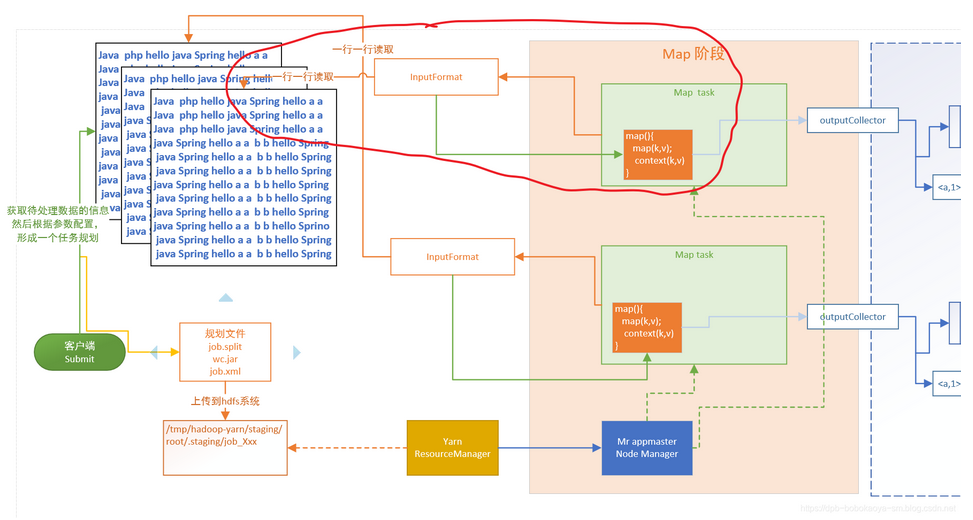
MapReduce原理分析之MapTask读取数据
通过前面的内容介绍相信大家对于MapReduce的操作有了一定的了解,通过客户端源码的分析也清楚了split是逻辑分区,记录了每个分区对应的是哪个文件,从什么位置开始到什么位置介绍,而且一个split对应一个Map Task任务,而MapTask具体是怎么读取文件的呢?本文来具体分析下。...
MapTask并行度决定机制、FileInputFormat切片机制、map并行度的经验之谈、ReduceTask并行度的决定、MAPREDUCE程序运行演示(来自学笔记)
1.3 MapTask并行度决定机制 maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度 那么,mapTask并行实例是否越多越好呢?其并行度又是如何决定呢? 1.3.1mapTask并行度的决定机制 一个job的map阶段并行度由客户端在提交job时...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
mapreduce您可能感兴趣
- mapreduce notebook
- mapreduce dataworks
- mapreduce hive
- mapreduce oss
- mapreduce访问
- mapreduce配置
- mapreduce sdk
- mapreduce策略
- mapreduce优化
- mapreduce模型
- mapreduce hadoop
- mapreduce集群
- mapreduce编程
- mapreduce数据
- mapreduce hdfs
- mapreduce运行
- mapreduce spark
- mapreduce maxcompute
- mapreduce程序
- mapreduce yarn
- mapreduce任务
- mapreduce wordcount
- mapreduce map
- mapreduce大数据
- mapreduce作业
- mapreduce案例
- mapreduce入门