MapReduce【自定义分区Partitioner】
实际开发中我们可能根据需求需要将MapReduce的运行结果生成多个不同的文件,比如上一个案例【MapReduce计算广州2022年每月最高温度】,我们需要将前半年和后半年的数据分开写到两个文件中。默认分区默认MapReduce只能写出一个文件: 因为我们在提交job的时候未设置reduc...
29 MAPREDUCE中的分区Partitioner
需求根据归属地输出流量统计数据结果到不同文件,以便于在查询统计结果时可以定位到省级范围进行。分析Mapreduce中会将map输出的kv对,按照相同key分组,然后分发给不同的reducetask。默认的分发规则为:根据key的hashcode%reducetask数来分发。所以:如果要按照我们自己...

Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
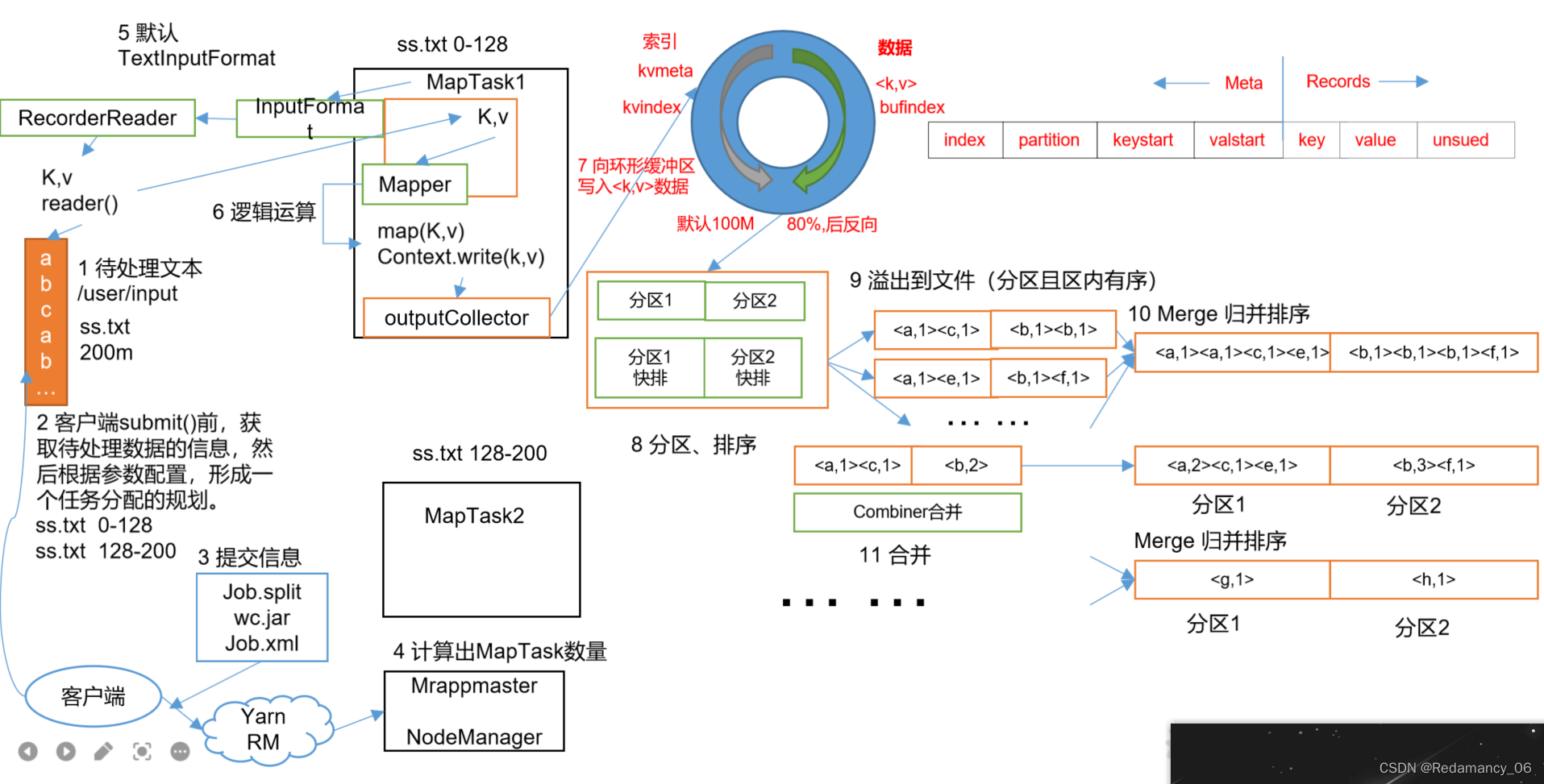
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢...
MapReduce编程例子之Combiner与Partitioner
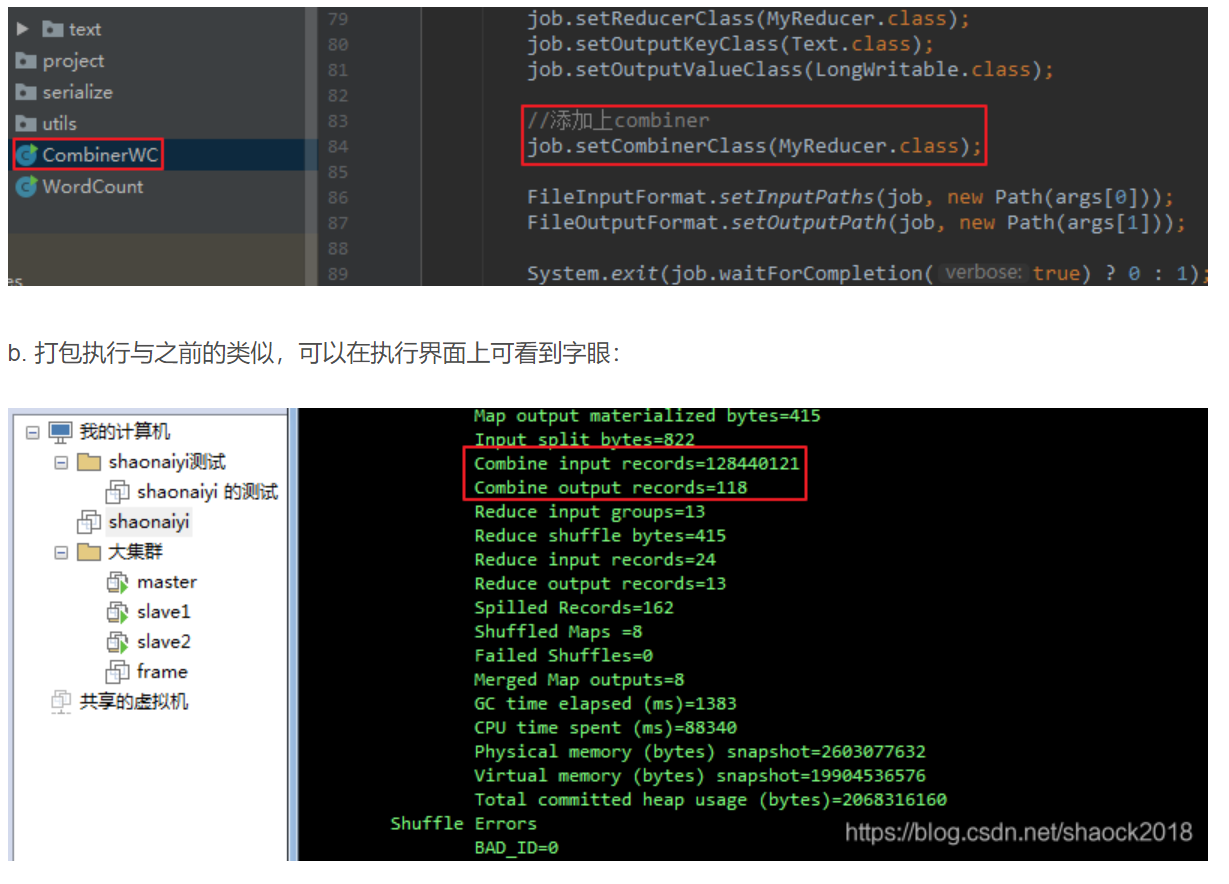
0x00 教程内容本教程是在“MapReduce入门例子之单词计数”上做的升级,请查阅此教程。包括了实现Combiner与Partitioner编程,都是一些编程技巧。0x01 Combiner讲解1. 优势a. 其实就是本地的reducer,在本地先聚合一次b. 可以减少Map Tasks输出的数...
mapReduce中如果没有定义partitioner,数据在送达reducer前是如何被分区的呢?
mapReduce中如果没有定义partitioner,数据在送达reducer前是如何被分区的呢?
Hadoop shuffle中mapreduce提供partitioner接口有什么作用?
Hadoop shuffle中mapreduce提供partitioner接口有什么作用?
MapReduce提供Partitioner接口作用是什么?
MapReduce提供Partitioner接口作用是什么?
MapReduce在Map端的Combiner和在Reduce端的Partitioner
1.Map端的Combiner. 通过单词计数WordCountApp.java的例子,如何在Map端设置Combiner... 只附录部分代码: 1 /** 2 * 以文本 3 * hello you 4 * hello me 5 * 为例子. 6 * map方法调用了两次,因为有两行...
MapReduce中的partitioner
1.日志源文件: 1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200 1363157995052 13826544101 5C-0E-8B-C7-F...
使用Mapreduce案例编写用于统计文本中单词出现的次数的案例、mapreduce本地运行等,Combiner使用及其相关的知识,流量统计案例和流量总和以及流量排序案例,自定义Partitioner
工程结构: 在整个案例过程中,代码如下: WordCountMapper的代码如下: package cn.toto.bigdata.mr.wc; import java.io.IOException; import org.apache.hadoop.io.IntWri...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
mapreduce您可能感兴趣
- mapreduce hive
- mapreduce oss
- mapreduce访问
- mapreduce配置
- mapreduce sdk
- mapreduce策略
- mapreduce优化
- mapreduce模型
- mapreduce编程
- mapreduce实战
- mapreduce hadoop
- mapreduce集群
- mapreduce hdfs
- mapreduce spark
- mapreduce maxcompute
- mapreduce程序
- mapreduce yarn
- mapreduce数据
- mapreduce运行
- mapreduce任务
- mapreduce wordcount
- mapreduce map
- mapreduce大数据
- mapreduce作业
- mapreduce案例
- mapreduce入门