Hadoop基础学习---5、MapReduce概述和WordCount实操(本地运行和集群运行)、Hadoop序列化
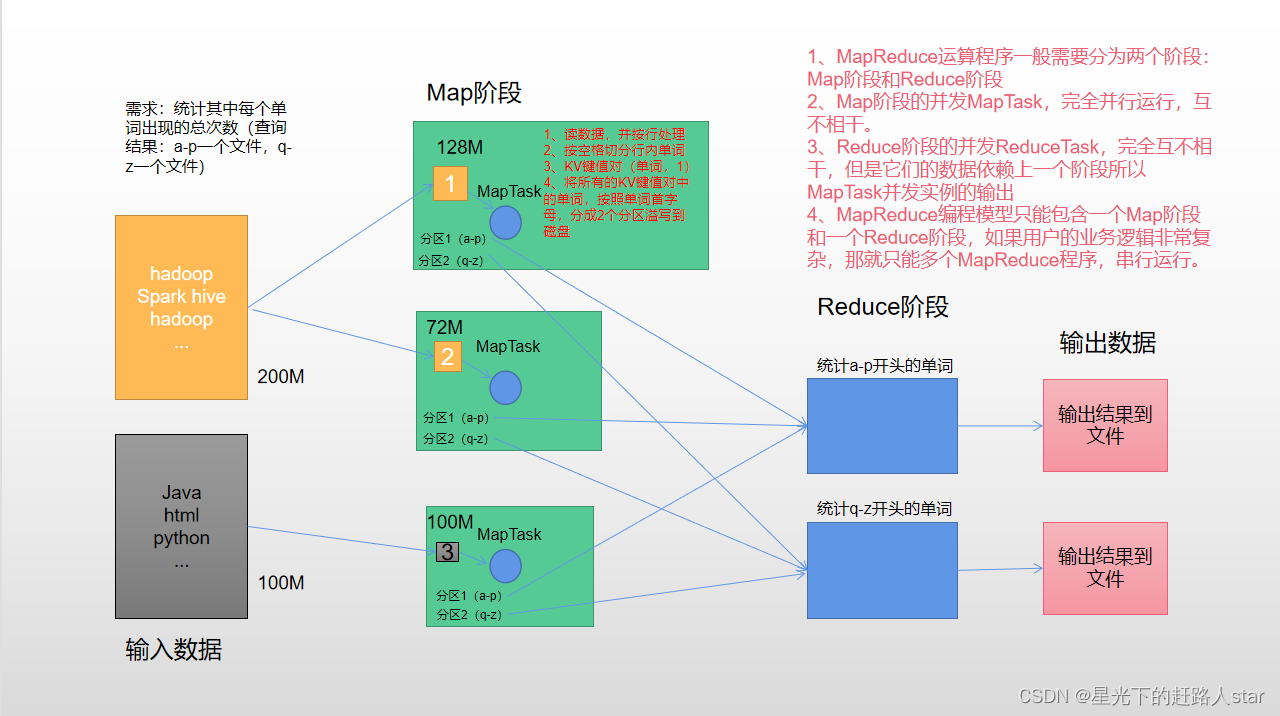
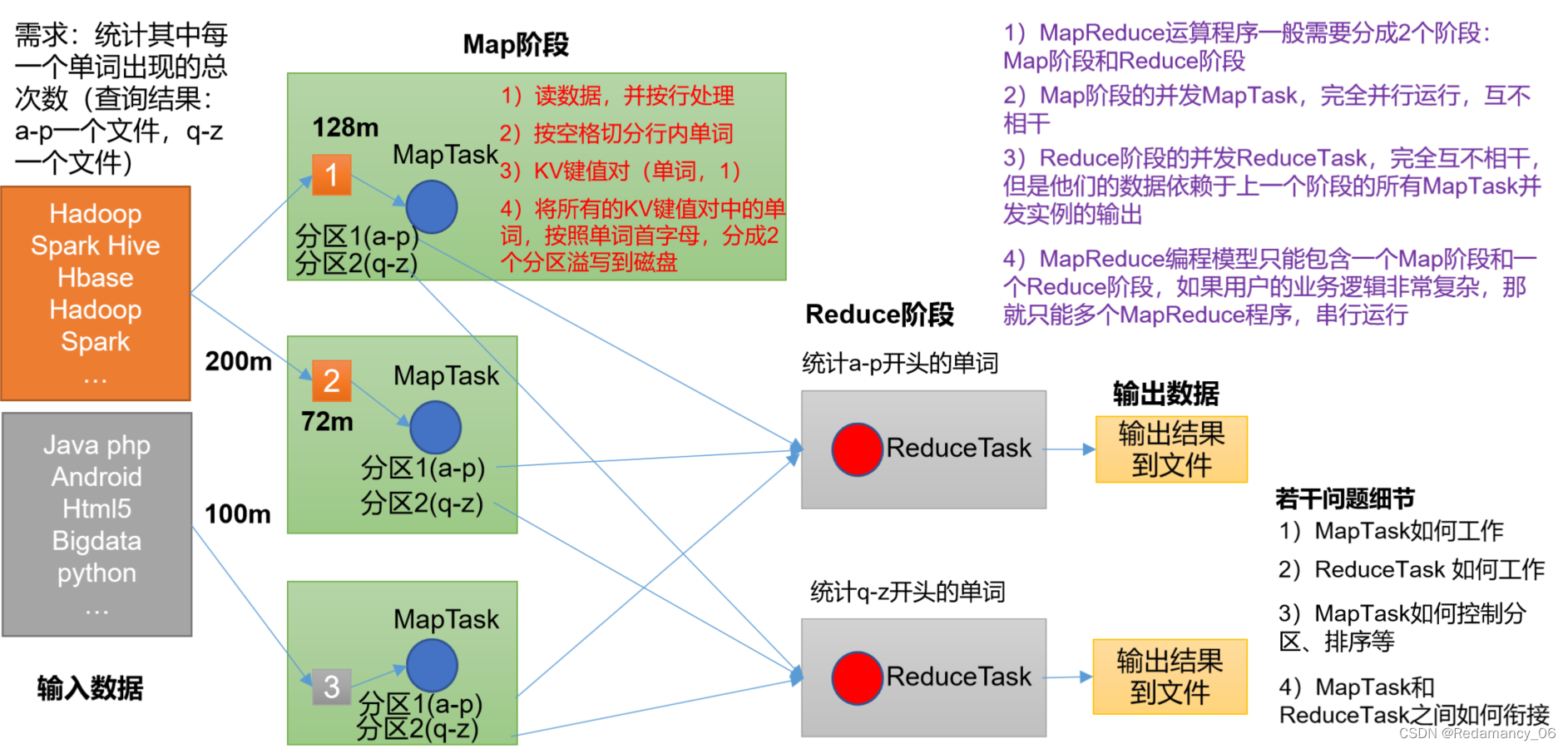
1、MapReduce概述1.1 MapReduce定义MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。1.2...
大数据基础-Hadoop序列化机制与InputFormat分析
Hadoop序列化机制当程序在向磁盘中写数据和读取数据时会进行序列化和反序列化,磁盘IO的这些步骤无法省略,我们可以从这些地方着手优化。当我们想把内存数据写到文件时,写序列化后再写入,将对象信息转为二进制存储,默认Java的序列化会把整个继承体系下的信息都保存,这就比较大了,会额外消耗性能。反序列化...
Hadoop中的MapReduce概述、优缺点、核心思想、编程规范、进程、官方WordCount源码、提交到集群测试、常用数据序列化类型、WordCount案例实操
@[toc]11.MapReduce概述11.1MapReduce定义 MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Ha...
Hadoop的序列化与反序列化实操
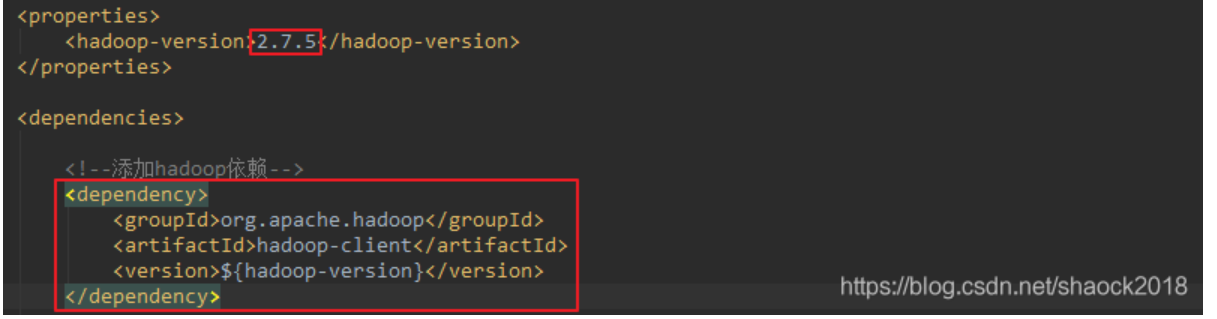
0x00 文章内容编写代码测试结果0x01 编写代码前提:因为需要用到Hadoop,所以需要先引入Hadoop相关的jar包<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>ha...

【Hadoop】(四)Hadoop 序列化 及 MapReduce 序列化案例实操
文章目录1 序列化概述2 自定义bean对象实现序列化接口(Writable)3 序列化案例实操1 序列化概述2 自定义bean对象实现序列化接口(Writable)在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。...
Hadoop序列化是什么?
Hadoop序列化是什么?
Hadoop序列化和反序列化的作用分别是什么呢?
Hadoop序列化和反序列化的作用分别是什么呢?
hadoop使用自己的序列化格式为什么?
hadoop使用自己的序列化格式为什么?
在hadoop分布式计算框架中如何对全排序进行序列化?
在hadoop分布式计算框架中如何对全排序进行序列化?
Hadoop中的序列化框架Google Protocolbuffer的缺点是什么?
Hadoop中的序列化框架Google Protocolbuffer的缺点是什么?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。