
C#中的序列化和反序列化案例
序列化:是将对象的状态存储到特定存储介质的过程,也可以说是将对象状态转换为可保持或传输的格式的过程。 上面的解释是官方定义,大白话解释就是,将对象以二进制的方式存储在文件中,如果简简单单的将一些数据或者内容存储到文件中的话,很好实现,直接使用IO就可以,但是对象可就不一样了,我们可以通过序列化来实现...
Flink CDC这边能在序列化里面做的,但是至于如何限流,有一些案例参考下吗?
Flink CDC这边能在序列化里面做的,但是至于如何限流,大佬有一些案例参考下吗?
Spark学习--3、WordCount案例、RDD序列化、RDD依赖关系、RDD持久化(二)
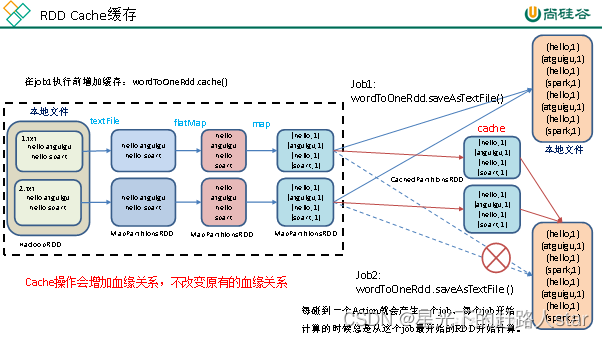
4、RDD持久化4.1 RDD Cache缓存1、RDD Cache缓存(1)RDD通过Cache或者persist方法将前面的计算结果缓存(2)默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。(3)但是并不是这个两个方法被调用时立即缓存,而是触发后面的action算子时,该R...
Spark学习--3、WordCount案例、RDD序列化、RDD依赖关系、RDD持久化(一)
1、WordCount案例实操导入项目依赖<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</art...

django drf 案例--实现url编码和json和dict格式转化小工具(涉及定义模型类,序列化器,类视图,路由),接口测试
整体目录模型类models.pyfrom django.db import models class UrlCoding(models.Model): raw_data = models.CharField(max_length=128, verbose_name='原始数据') coding_co...

【Django学习笔记 - 17】:序列化和反序列化(restful接口小案例、DRF的工程搭建、序列化器与序列化、验证、保存)
restful接口小案例先创建一个子应用,然后在setttings中进行注册在主路由中进行路由的分发在husband_data子应用的views.py文件中写上Json数据,并返回给前端from django.views import View from django.http import Jso...
Java序列化案例demo(包含Kryo、JDK原生、Protobuf、ProtoStuff以及hessian)(二)
三、Protobuf序列化介绍protobuf—Github地址、protobuf-java介绍:Protobuf 出自于 Google,性能还比较优秀,也支持多种语言,同时还是跨平台的。就是在使用中过于繁琐,因为你需要自己定义 IDL 文件和生成对应的序列化代码。这样虽然不然灵活,但是,另一方面导...
Java序列化案例demo(包含Kryo、JDK原生、Protobuf、ProtoStuff以及hessian)(一)
一、Kryo序列化(优先选择)介绍kryo-Gihub仓库地址Kryo 是一个高性能的序列化/反序列化工具,由于其变长存储特性并使用了字节码生成机制,拥有较高的运行速度和较小的字节码体积,并且Kryo 已经是一种非常成熟的序列化实现了,已经在 Twitter、Groupon、Yahoo 以及多个著名...
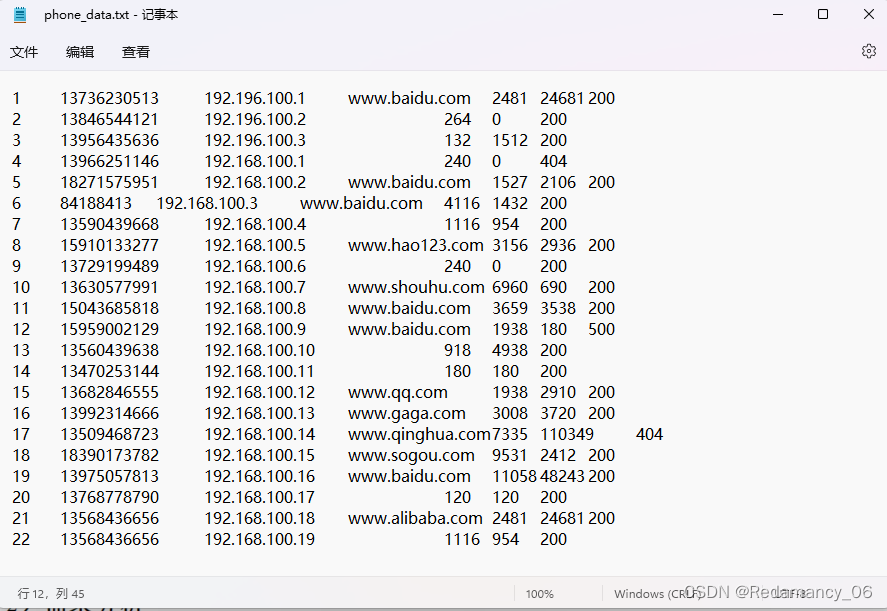
Hadoop序列化、概述、自定义bean对象实现序列化接口(Writable)、序列化案例实操、编写流量统计的Bean对象、编写Mapper类、编写Reducer类、编写Driver驱动类
@[toc]12.Hadoop序列化12.1序列化概述12.1.1什么是序列化序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。 反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。12.1.2为什么要序列化一...
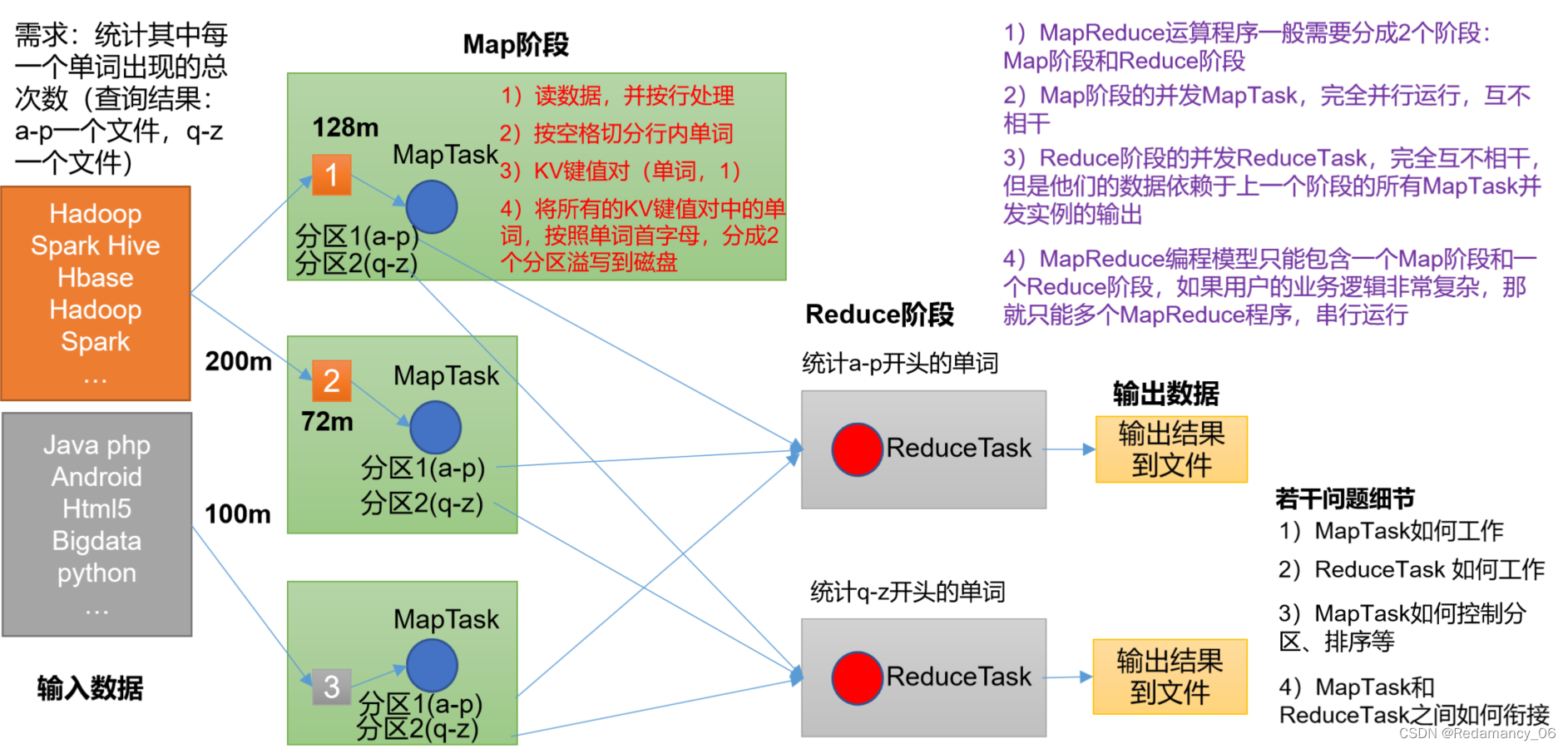
Hadoop中的MapReduce概述、优缺点、核心思想、编程规范、进程、官方WordCount源码、提交到集群测试、常用数据序列化类型、WordCount案例实操
@[toc]11.MapReduce概述11.1MapReduce定义 MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Ha...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。