
Transformer 自然语言处理(一)
Transformer 自然语言处理(一)

【机器学习】Transformer:自然语言处理的巅峰之作
自然语言处理领域自从引入Transformer模型以来,经历了一场技术革命。Transformer不仅仅是一个模型,更是一种范式的颠覆,为自然语言处理技术的进步开创了新的时代。本文将深入剖析Transforme...

全领域涨点 | Transformer携Evolving Attention在CV与NLP领域全面涨点(文末送书)(二)
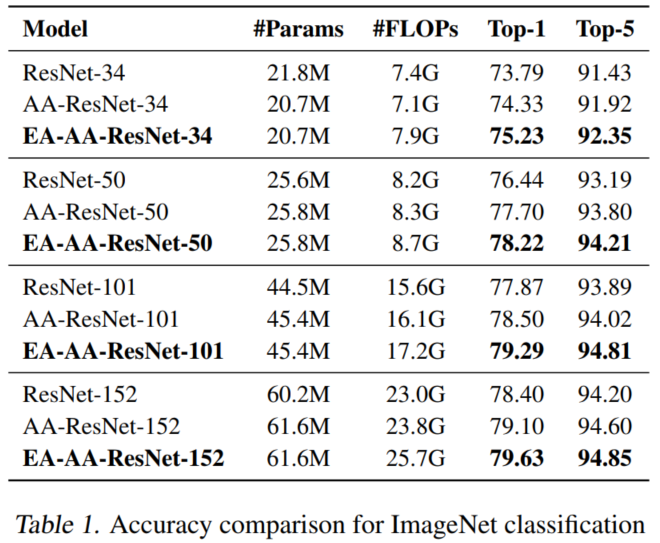
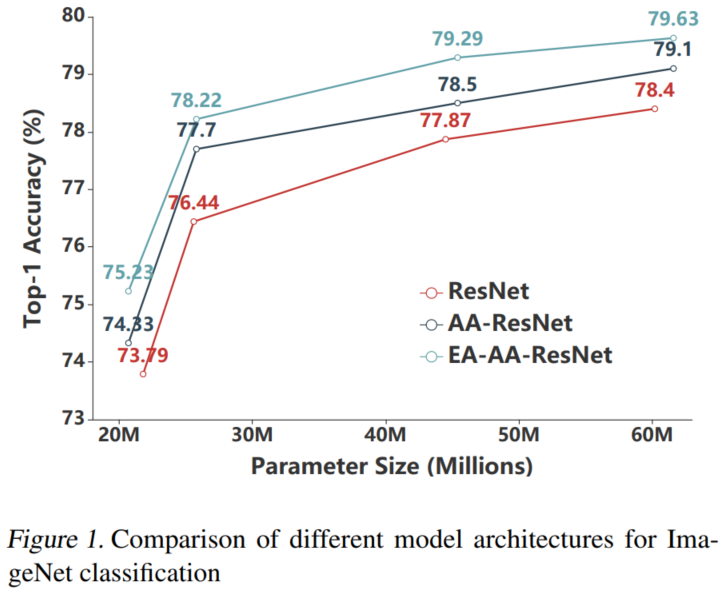
4. 实验4.1 图像分类如表1所示,AA-ResNet的表现始终明显优于相应的ResNet。在AAResNet-34、-50、-101和-152的基础上,EA-AA-ResNets的Top-1准确率分别提高了1.21%、0.67%、0.80%和0.67%。4.2 自然语言理解BERT-style模...
全领域涨点 | Transformer携Evolving Attention在CV与NLP领域全面涨点(文末送书)(一)
1 摘要Transformer是一种普遍存在于自然语言处理的模型,近期在计算机视觉领域引起了广泛关注。而Attention map主要用来编码input tokens之间的依赖关系,其对于一个Transformer模型来说是必不可少的。然而,它们在每一层都是独立学习的,有时无法捕获精确的模式。因此在...

NeurIPS 2022 | Meta 提出二值transformer网络BiT,刷新NLP网络压缩极限
神经网络压缩一直被视为机器学习模型从实验室走向工业应用中的不可或缺的一步,而量化 (quantization) 又是神经网络压缩中最常用的方法之一。今天这篇 NeurIPS 论文 BiT 从实验和理论验证了极端压缩情况下的 1-bit 的 BERT 网络也能在自然语言处理的分类数据集 GLUE 上取...

华为诺亚Transformer后量化技术:效率百倍提升,视觉&NLP性能不减
Transformer 在自然语言处理和视觉任务中取得了令人瞩目的成果,然而预训练大模型的推理代价是备受关心的问题,华为诺亚方舟实验室的研究者们联合高校提出针对视觉和 NLP 预训练大模型的后训练量化方法。在精度不掉的情况下,比 SOTA 训练感知方法提速 100 倍以上;量化网络性能也逼近训练感知...
Transformer培训:《Transformers for NLP 》详细解读打实基础
Github 代码地址:https://github.com/PacktPublishing/Transformers-for-Natural-Language-Processing《Transformers for Natural Language Processing》这本书的作者丹尼斯·罗斯曼...
Transformer培训课程:Transformers for NLP
Transformer的架构、训练及推理等都是在Bayesian神经网络不确定性数学思维下来完成的。Encoder-Decoder架构、Multi-head注意力机制、Dropout和残差网络等都是Bayesian神经网络的具体实现;基于Transformer各种模型变种及实践也都是基于Bayesi...
基于 Transformer 的 NLP 智能对话机器人实战课程(大纲1-10章)
关于 Transformer 和注意力机制提出的 101 个高级思考问题可以查看 Gitee Transformer101Q标签:Transformer,注意力机制,Attention机制,Transfomer课程,Transformer架构,Transformer模型,对话机器人,NLP课程,NL...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践




