请问bin/spark-sql --master yarn不能进行集群模式运行吗?
请问bin/spark-sql --master yarn不能进行集群模式运行吗? spark版本:spark-3.4.2 现在想通过bin/spark-sql --master yarn来运行纯sql脚本,但是发现不能通过--deploy-mode cluster这种集群模式运行,只能通过clie...
云数据仓库ADB,检测是否存在运行中的Spark SQLEngine?
云数据仓库ADB,ExistRunningSQLEngine - 检测是否存在运行中的Spark SQLEngine?

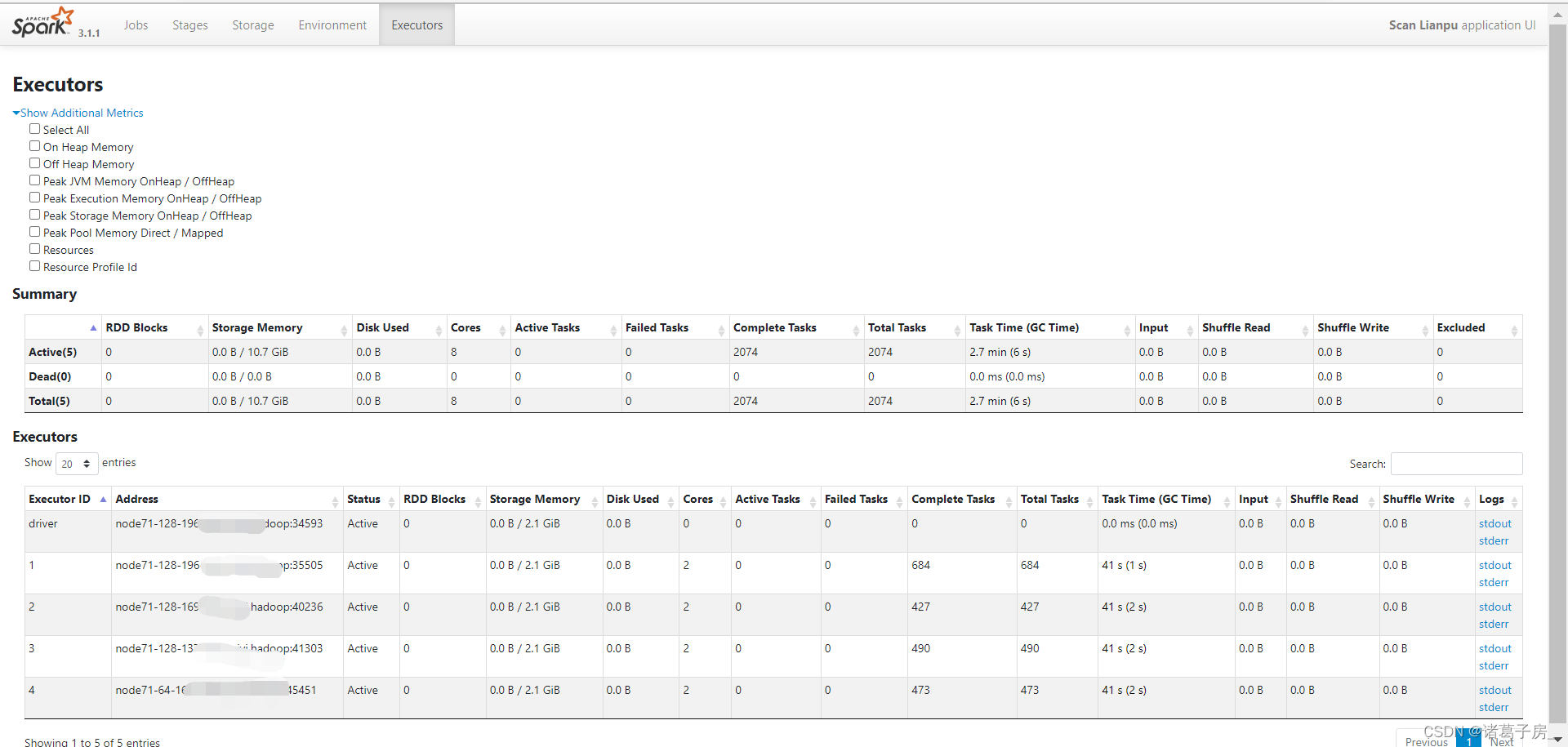
Spark 任务运行时日志分析
1.spark job 运行时2.System.out.println() 日志输出位置 3.stderrlog.error 输出日志位置
大数据计算MaxCompute为什么 odps spark 任务运行那么慢,?
大数据计算MaxCompute为什么 odps spark 任务运行那么慢, 正常sql在 odps sql 运行只需要十几秒, 在 spark 要四五分钟, 而且形同数据量 spark 写入表里的存储大小, 是 sql 写的 10倍大 ?
【大数据技术Hadoop+Spark】Spark RDD设计、运行原理、运行流程、容错机制讲解(图文解释)
一、RDD的概念RDD(Resilient Distributed Dataset),即弹性分布式数据集,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并且还能控制数据的分区。不同RDD之间可以通过转换操作形成依赖关系实现管道化,从而避免了中间结果的I/O操作,提高数据处理...
DataWorks一个spark节点一直报这种错误是可能什么原因呢?都未运行看不到详情日志?
DataWorks一个spark节点一直报这种错误是可能什么原因呢?都未运行看不到详情日志?执行器数给的5,并行给的4
在大数据计算MaxCompute中,我手动或者定时去执行合并是否会影响到我正在运行的spark?
我手动或者定时去执行合并是否会影响到我正在运行的spark流式写入的任务呢?

Spark2:运行架构
一、运行架构1.概念• Application: 用户基于spark的代码,由一个Driver和多个Executor组成。• Executor: 在工作节点(如standalone的Worker和yarn的NM)上的进程,可以运行task,也可以将数据保存在内存和磁盘中。每个应用程序都有自己的Exe...
大数据计算MaxCompute在idea下的Local模式下运行Spark,报错怎么排查这个问题啊?
大数据计算MaxCompute在idea下的Local模式下运行Spark,报错怎么排查这个问题啊?Cannot create CupidSession with empty CupidConf.
dataworks里面支持spark3吗,spark2运行是没问题?
dataworks里面支持spark3吗,spark2运行是没问题?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多运行相关
- 运行apache spark
- apache spark集群模式运行
- apache spark yarn模式运行
- apache spark master运行
- apache spark集群运行
- 数据计算apache spark运行
- apache spark运行原理
- 运行apache spark报错
- apache spark版本运行
- apache spark作业运行
- 集群运行apache spark
- apache spark运行程序
- apache spark原理运行学习笔记
- apache spark运行架构分析
- 运行apache spark应用程序
- scala apache spark运行
- apache spark原理运行stage
- apache spark application运行
- apache spark编译运行
- apache spark运行节点
apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作