使用Spark进行机器学习
使用Spark进行机器学习主要通过其提供的MLlib库来实现,以下是使用Spark MLlib进行机器学习的步骤: 准备数据:需要对数据进行预处理,包括清洗、转换和特征提取等,以便于机器学习算法能够更好地理解和处理。选择算法:根据具体的机器学习任务,如分类、回归或聚类,选择合适的算法。...
Spark MLlib简介与机器学习流程
在大数据领域,机器学习是一个关键的应用领域,可以用于从海量数据中提取有价值的信息和模式。Apache Spark MLlib是一个强大的机器学习库,可以在分布式大数据处理环境中进行机器学习任务。本文将深入介绍Spark MLlib的基本概念、机器学习流程以及提供详细的示例代码。 什么是Spark M...

Spark中的机器学习库MLlib是什么?请解释其作用和常用算法。
Spark中的机器学习库MLlib是什么?请解释其作用和常用算法。Spark中的机器学习库MLlib是一个用于大规模数据处理的机器学习库。它提供了一组丰富的机器学习算法和工具,可以用于数据预处理、特征提取、模型训练和评估等任务。MLlib是基于Spark的分布式计算引擎构建的,可以处理大规模数据集,...

机器学习(一)Spark机器学习基础
1. Spark机器学习基础l 学习目标掌握机器学习与大数据的区别和联系掌握机器学习概念掌握机器学习如何构建机器学习模型过程1.0机器学习和大数据的区别和联系首先,回顾大数据的4V特征:1.数据量大TB-PB-ZBHDFS分布式文件系统2.数据种类多结构化数据-Mysql为主的存储和处理非结构化数据...
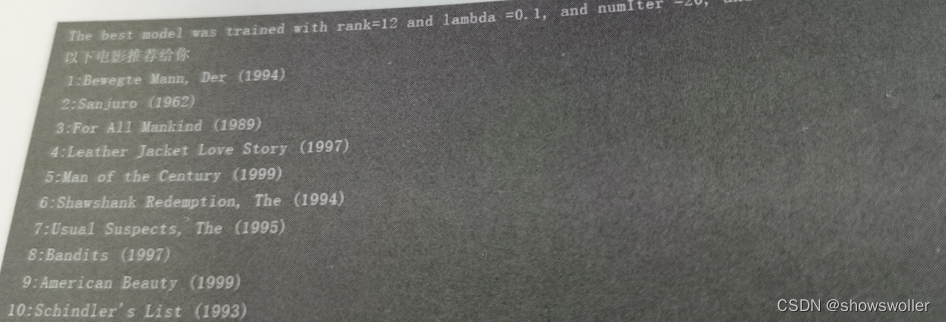
【大数据技术】Spark MLlib机器学习协同过滤电影推荐实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~协同过滤————电影推荐协同过滤是利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。在协同过滤算法中有着两个分支,分别是基于群体用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。在电影推荐系统中,通常分为针对用户推荐电...

【大数据技术】Spark MLlib机器学习线性回归、逻辑回归预测胃癌是否转移实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~线性回归过工具类MLUtils加载LIBSVM格式样本文件,每一行的第一个是真实值y,有10个特征值x,用1:double,2:double分别标注,即建立需求函数:y=a_1x_1+a_2x_2+a_3x_3+a_4x_4+…+a_10x_10通...
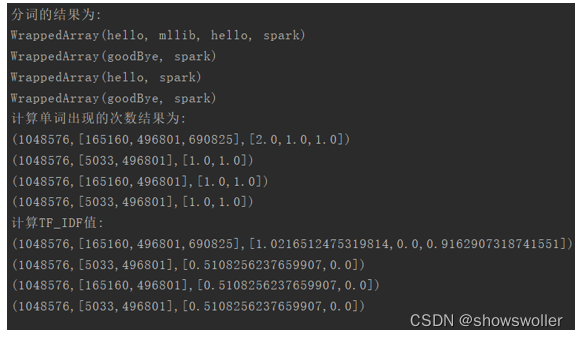
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词...
【大数据技术】Spark MLlib机器学习库、数据类型详解(图文解释)
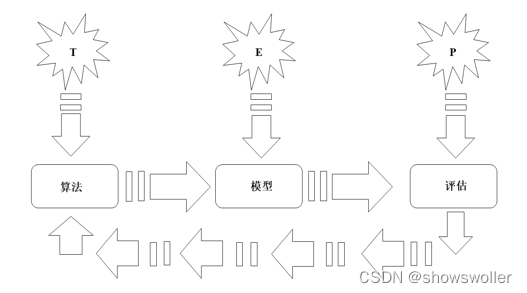
机器学习的定义机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。机器学习的构建过程是利用数据通过算法构建出模型并对模型进行评估,评估的性能如果达到要求就拿这个模型来测试其他的数据,如果达不到要求就要调整算法来重新建立模型,再次进行评估,如此循环往复,最终获得满意的经验来处理其他的数...
机器学习PAI这里有没有spark的群?
机器学习PAI这里有没有spark的群?
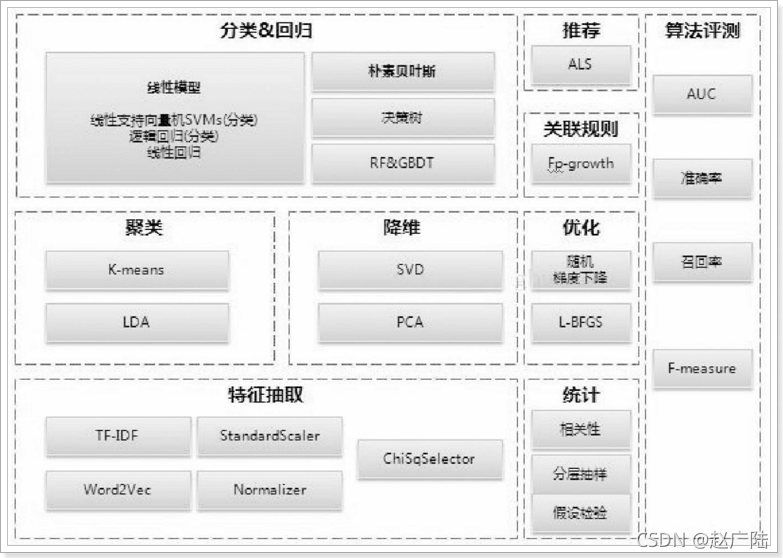
大数据Spark MLlib机器学习
1 什么是Spark MLlib?MLlib是Spark的机器学习(ML)库。旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。MLlib目前分为两个代码包:spark....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多机器学习相关
apache spark您可能感兴趣
- apache spark可视化分析
- apache spark决策
- apache spark可视化
- apache spark分析
- apache spark Mapreduce
- apache spark SQL
- apache spark Python
- apache spark数据
- apache spark决策树
- apache spark资源消耗
- apache spark streaming
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark大数据分析