
典型的Spark应用实例
以下是一些典型的Spark应用实例: 交通流量预测:使用Spark的机器学习库来训练模型,根据历史数据预测未来交通流量,以便优化交通调度和路线规划。 风险评估:使用Spark的图处理功能来分析金融数据,识别异常模式和风险,帮助金融机构做出更好的决策。 日志分析:使用Spark的数据分析...
[帮助文档] 通过PySpark开发Spark应用_云原生数据仓库AnalyticDB MySQL版(AnalyticDB for MySQL)
本文介绍了如何开发AnalyticDB MySQL Spark Python作业,以及如何通过VirtualEnv技术打包Python作业的运行环境。

Apache Spark 的基本概念和在大数据分析中的应用
Apache Spark 是一个开源的分布式计算系统,它旨在处理大规模数据集并提供高性能和易用性。Spark 提供了一个统一的编程模型,可以在多种编程语言中使用,包括 Scala、Java、Python和R。Spark 的主要特点包括: 快速:Spark 使用内存计算技术,可以比传统的批处理系统(如...
介绍 Apache Spark 的基本概念和在大数据分析中的应用。
Spark的基本概念包括:弹性分布式数据集(Resilient Distributed Dataset,简称RDD):它是Spark的核心数据结构,代表分布在集群中的可并行处理的数据集,可以在内存中存储。RDD具有容错能力,即使在节点失败时也可以自动恢复。转换操作(Transformations):...
[帮助文档] 如何通过Java SDK提交Spark作业、查询Spark作业的状态和日志信息、结束Spark作业以及查询Spark历史作业
AnalyticDB MySQL湖仓版(3.0)集群支持通过Java SDK开发Spark应用和Spark SQL作业。本文介绍通过Java SDK提交Spark作业、查询Spark作业的状态和日志信息、结束Spark作业以及查询Spark历史作业的操作步骤。

Spark入门指南:从基础概念到实践应用全解析
在这个数据驱动的时代,信息的处理和分析变得越来越重要。而在众多的大数据处理框架中,「Apache Spark」以其独特的优势脱颖而出。本篇文章,我们将一起走进Spark的世界,探索并理解其相关的基础概念和使用方法。本文主要目标是让初学者能够对Spark有一个全面的认识,并能实际应用到各类问题的解决之...
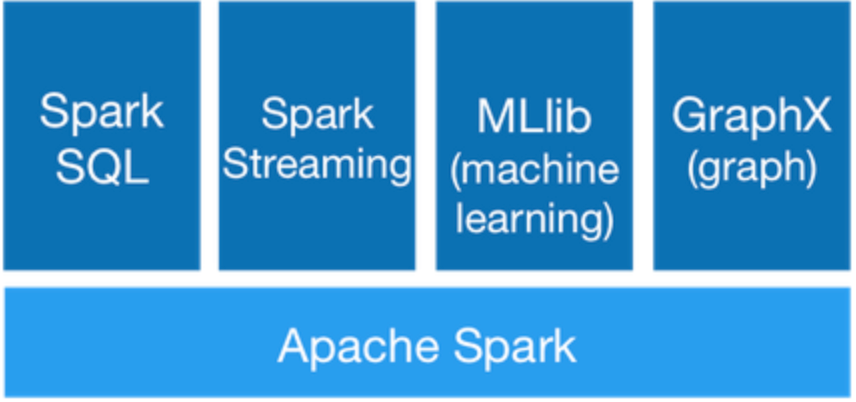
Spark入门指南:从基础概念到实践应用全解析
本文已收录至GitHub,推荐阅读 Java随想录 微信公众号:Java随想录 原创不易,注重版权。转载请注明原作者和原文链接 在这个数据驱动的时代,信息的处理和分析变得越来越重要。而在众多的大数据处理框架中,「Apache Spark」以其独特的优势脱颖而出。 本篇文章,我们将一起走进Spark的...

SPARK 应用如何快速应对 LOG4J 的系列安全漏洞
大家好,我是明哥!1. CDH/HDP/CDP 等大数据平台中如何快速应对 LOG4J2 的JNDI系列漏洞在前段时间发表的博文 “CDH/HDP/CDP等大数据平台中如何快速应对LOG4J的JNDI系列漏洞” 中,我们描述了 CDH/HDP/CDP 等大数据平台中如何快速应对 LOG4J 的 JN...
Apache Spark 的基本概念和在大数据分析中的应用
Apache Spark 是一种流行的开源大数据分析框架,它是建立在强大的分布式计算引擎基础上的,可以处理大规模的数据,并提供高性能的数据处理能力。以下是 Apache Spark 的一些基本概念:1. Resilient Distributed Datasets(RDD):是 Spark 中的核心...
Hadoop生态系统中的机器学习与数据挖掘技术:Apache Mahout和Apache Spark MLlib的应用
Hadoop是一个开源的分布式计算框架,用于处理大规模数据集的存储和处理。随着大数据的快速发展,机器学习和数据挖掘技术在Hadoop生态系统中的应用也变得越来越重要。在本文中,我们将重点介绍Hadoop生态系统中的两个重要机器学习和数据挖掘技术:Apache Mahout和Apache Spark ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多应用相关
apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作