[帮助文档] Apache Kafka Connect远程代码执行漏洞
2023年02月08日,Apache发布了一则安全公告,修复了Apache Kafka中存在的一个反序列化漏洞,漏洞编号为CVE-2023-25194。在攻击者可以控制Apache Kafka Connect客户端的情况下,通过SASL JAAS配置和基于SASL的安全协议,在其上创建或修改连接器,...
[帮助文档] 配置Kafka开启Ranger权限
本文介绍了Kafka如何开启Ranger权限控制,以及Ranger Kafka权限配置说明。


大数据开发岗面试复习30天冲刺 - 日积月累,每日五题【Day06】——Kafka4
前言大家好,我是程序员manor。作为一名大数据专业学生、爱好者,深知面试重要性,很多学生已经进入暑假模式,暑假也不能懈怠,正值金九银十的秋招接下来我准备用30天时间,基于大数据开发岗面试中的高频面试题,以每日5题的形式,带你过一遍常见面试题及恰如其分的解答。相信只要一路走来,日积月累,我们终会在最...

大数据开发岗常见面试复习30天冲刺 - 日积月累,每日五题【Day05】——Kafka3
不要急着往下滑,默默想5min,看看这5道面试题你都会吗?面试题 01、请简述如何使用Kafka Simple Java API 实现数据消费?描述具体的类及方法 面试题02、请简述Kafka生产数据时如何保证生产数据不丢失? 面试题 03 请简述Kafka生产数据时如何保证生产数据不重复? 面试题...

大数据开发岗大厂面试30天冲刺 - 日积月累,每日五题【Day04】——Kafka2
面试题 01 Kafka中消费者与消费者组的关系是什么?•消费者组负责订阅Topic,消费者负责消费Topic分区的数据•消费者组中可以包含多个消费者,多个消费者共同消费数据,增加消费并行度,提高消费性能•消费者组的id由开发者指定,消费者的id由Kafka自动分配面试题02、Kafka中Topic...
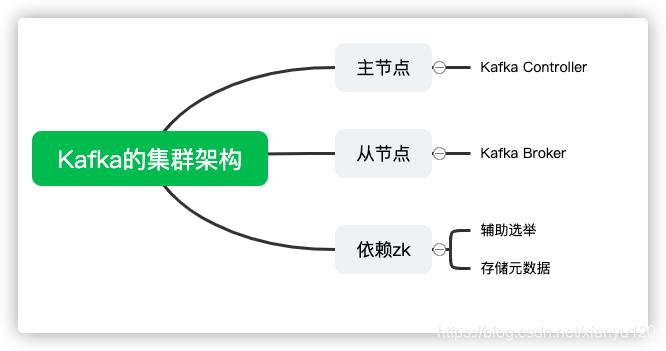
大数据开发岗大厂面试30天冲刺 - 日积月累,每日五题【Day03】——Kafka1
面试题 01 什么是消息队列?消息队列就是用于当两个系统之间或者两个模块之间实现消息传递时,基于队列机制实现数据缓存的中间件面试题 02 消息队列有什么好处?•实现解耦,将高耦合转换为低耦合•通过异步并发,提高性能,并实现最终一致性面试题03、Kafka是什么?•Kafka是一个基于订阅发布模式的高...

【大数据技术】Spark+Flume+Kafka实现商品实时交易数据统计分析实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~Flume、Kafka区别和侧重点1)Kafka 是一个非常通用的系统,你可以有许多生产者和消费者共享多个主题Topics。相比之下,Flume是一个专用工具被设计为旨在往HDFS,HBase等发送数据。它对HDFS有特殊的优化,并且集成了Hadoop的安...
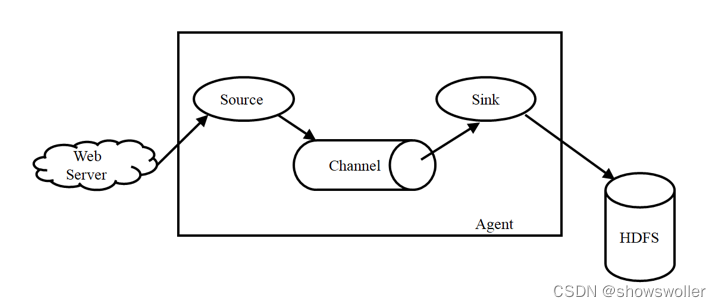
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:...
将Apache Flink任务实时消费Kafka窗口的计算改为MaxCompute
将Apache Flink任务实时消费Kafka窗口的计算改为MaxCompute,需要经过以下几个步骤: 数据接入:首先,你需要将Flink任务产生的数据写入到MaxCompute。这可以通过Flink的DataStream API中的sink函数来实现。你可以选择将数据写入到MaxCompute...
ApacheFLink任务实时消费Kafka窗口的计算要改成maxcompute要怎么实现呢?
在原来的数据处理架构中 有一个Apache FLink任务实时消费Kafka 做一个窗口的计算 现在要改成maxcompute话要怎么实现呢这个实时计算任务呢?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子








云原生大数据计算服务 MaxCompute更多kafka相关
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute实例
- 云原生大数据计算服务 MaxCompute内存
- 云原生大数据计算服务 MaxCompute表结构
- 云原生大数据计算服务 MaxCompute创建表
- 云原生大数据计算服务 MaxCompute rds
- 云原生大数据计算服务 MaxCompute接口
- 云原生大数据计算服务 MaxCompute如何处理
- 云原生大数据计算服务 MaxCompute字段
- 云原生大数据计算服务 MaxCompute hive
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目