DL之DNN:基于sklearn自带california_housing加利福尼亚房价数据集利用GD神经网络梯度下降算法进行回归预测(数据较多时采用mini-batch方式训练会更快)
目录基于sklearn自带california_housing加利福尼亚房价数据集利用GD神经网络梯度下降算法进行回归预测(数据较多时采用mini-batch方式训练会更快)输出结果实现代码基于sklearn自带california_housing加利福尼亚房价数据集利用GD神经网络梯度下降算法进行...

AI顶会ICLR 2022 | WPipe 蚂蚁集团大规模 DNN 训练的流水线并行技术
导言ICLR,全称为 International Conference on Learning Representations (国际学习表征会议) 是三大机器学习领域顶会之一 (另外两个是ICML和NeuriPS)。该会议的主要创办者就包含了深度学习三大巨头的YoShua Be...

不确定性助益学习准确率,GPU训练预测性DNN误差更少、效果更好
这一研究可能促使人们重新审视 GPU 在深度神经网络训练中扮演的角色。最近,有学者发现在 GPU 而不是 CPU 上训练的机器学习系统在训练过程中可能包含更少的误差,并产生更好的结果。这一发现与一般的理解相矛盾,即 GPU 只具有加速功能,而不是使训练结果更好。来自波兹南密茨凯维奇大学、大阪大学、索...
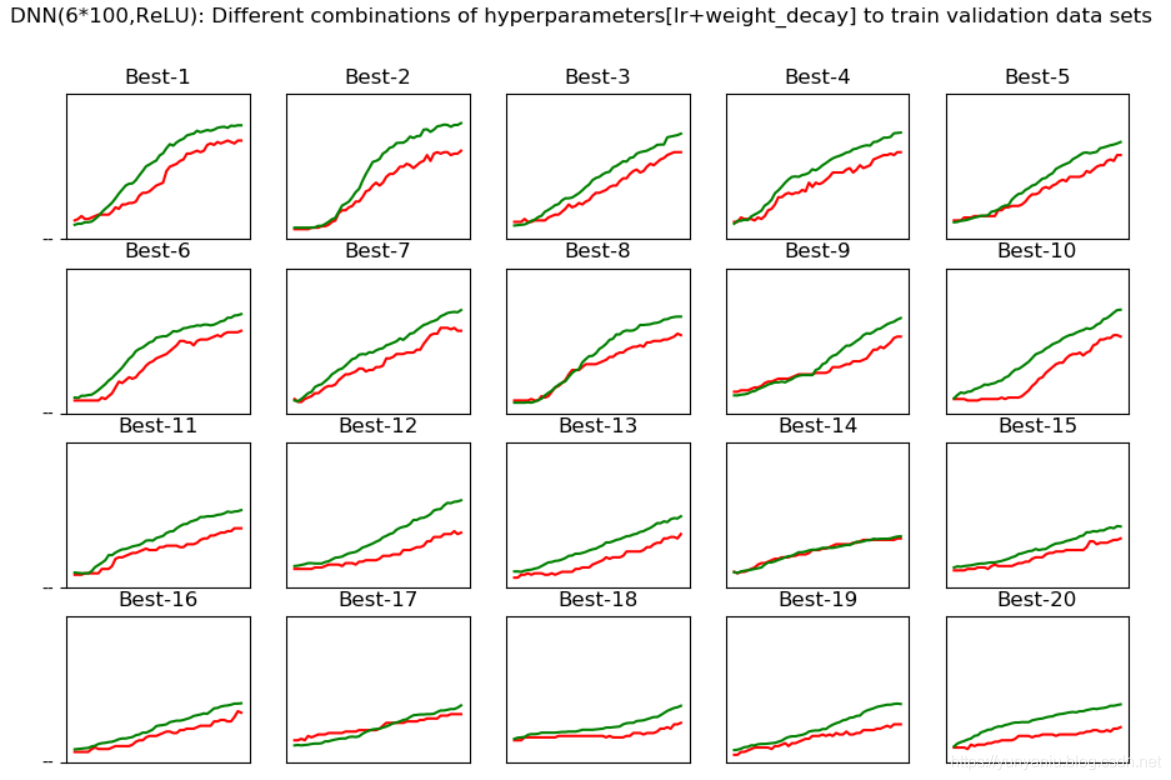
DL之DNN:自定义MultiLayerNet【6*100+ReLU,SGD】对MNIST数据集训练进而比较【多个超参数组合最优化】性能
输出结果val_acc:0.14 | lr:4.370890470178883e-06, weight_decay:1.3601071813862507e-08val_acc:0.09 | lr:0.00014631102405898786, weight_decay:1.1349746520024...
DL之DNN:利用MultiLayerNetExtend模型【6*100+ReLU+SGD,dropout】对Mnist数据集训练来抑制过拟合
输出结果 设计思路 核心代码class RMSprop: def __init__(self, lr=0.01, decay_rate = 0.99): self.lr = lr &nb...

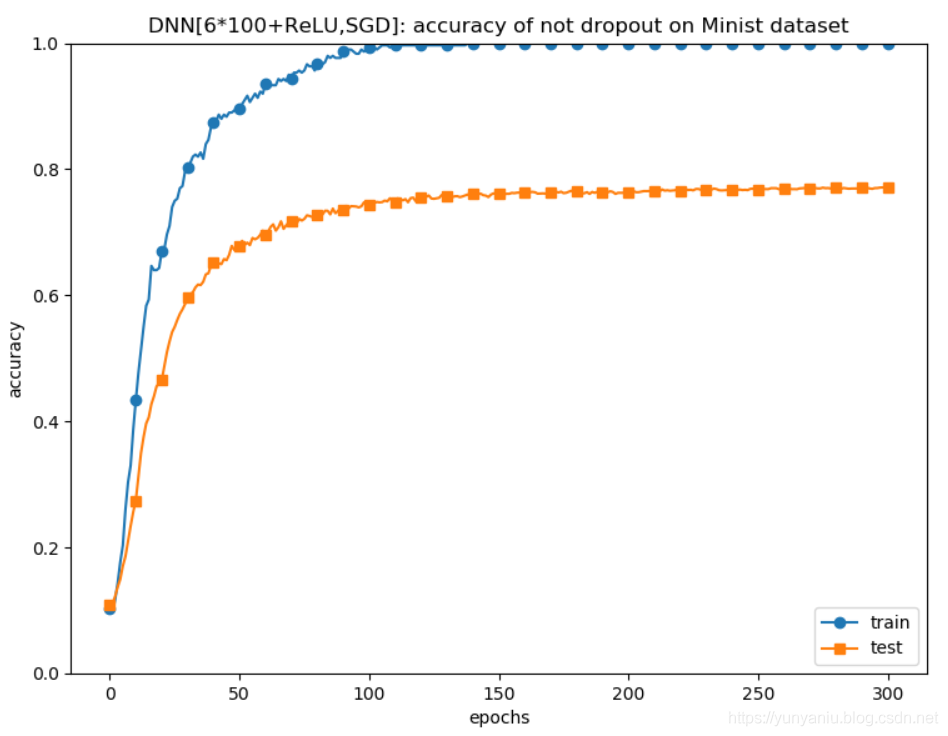
DL之DNN:利用MultiLayerNet模型【6*100+ReLU+SGD,weight_decay】对Mnist数据集训练来抑制过拟合
输出结果 设计思路 核心代码# weight_decay_lambda = 0weight_decay_lambda = 0.1for i in range(1000000): batch_mask = np.random.choice(train_si...

DL之DNN:利用MultiLayerNet模型【6*100+ReLU+SGD】对Mnist数据集训练来理解过拟合现象
输出结果 设计思路 核心代码for i in range(1000000): batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[bat...
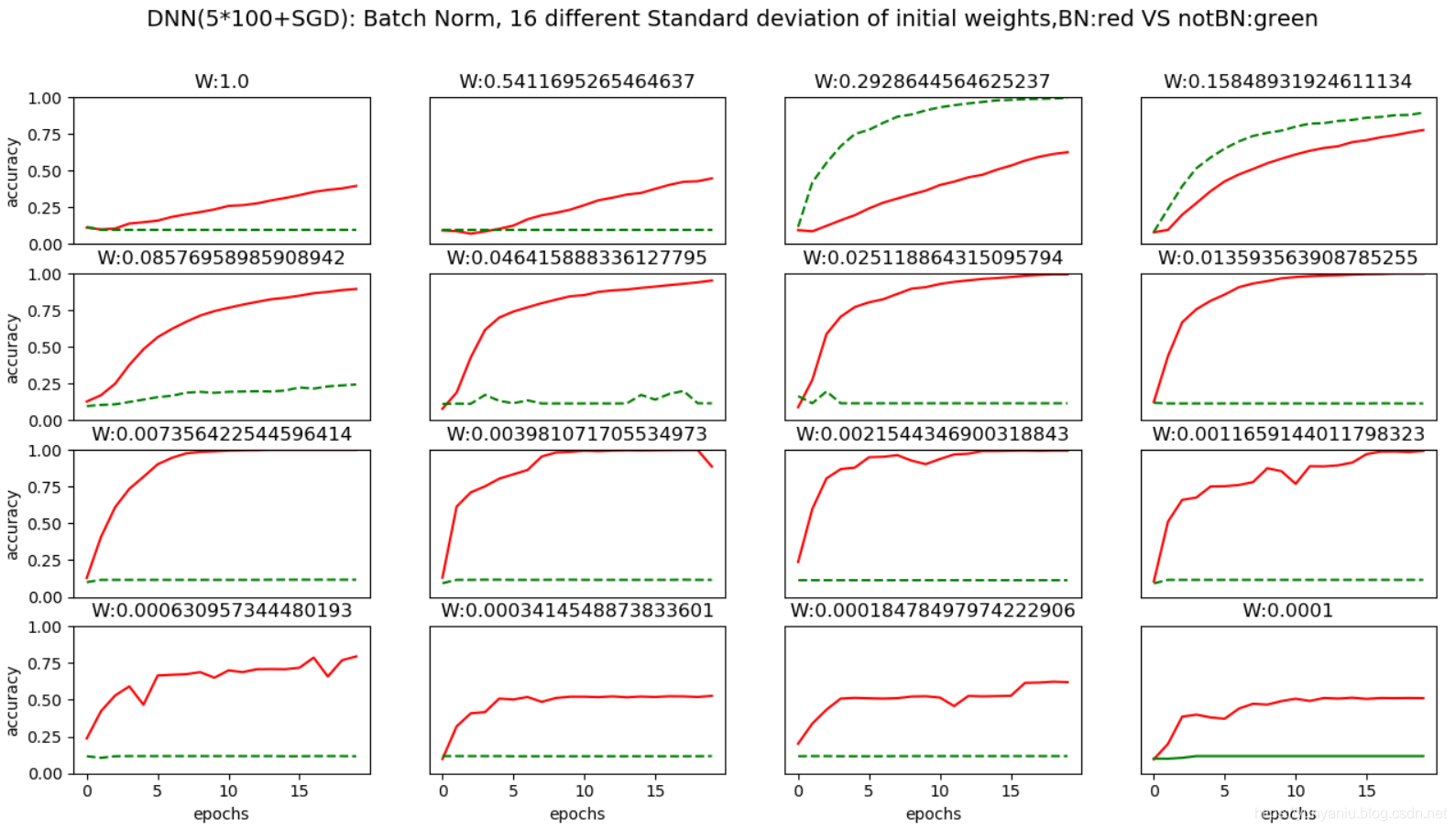
DL之DNN优化技术:自定义MultiLayerNetExtend算法(BN层使用/不使用+权重初始值不同)对Mnist数据集训练评估学习过程
输出结果 设计思路 核心代码(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)x_train = x_train[:1000]t_train = t_train[:1000]max_epochs = ...
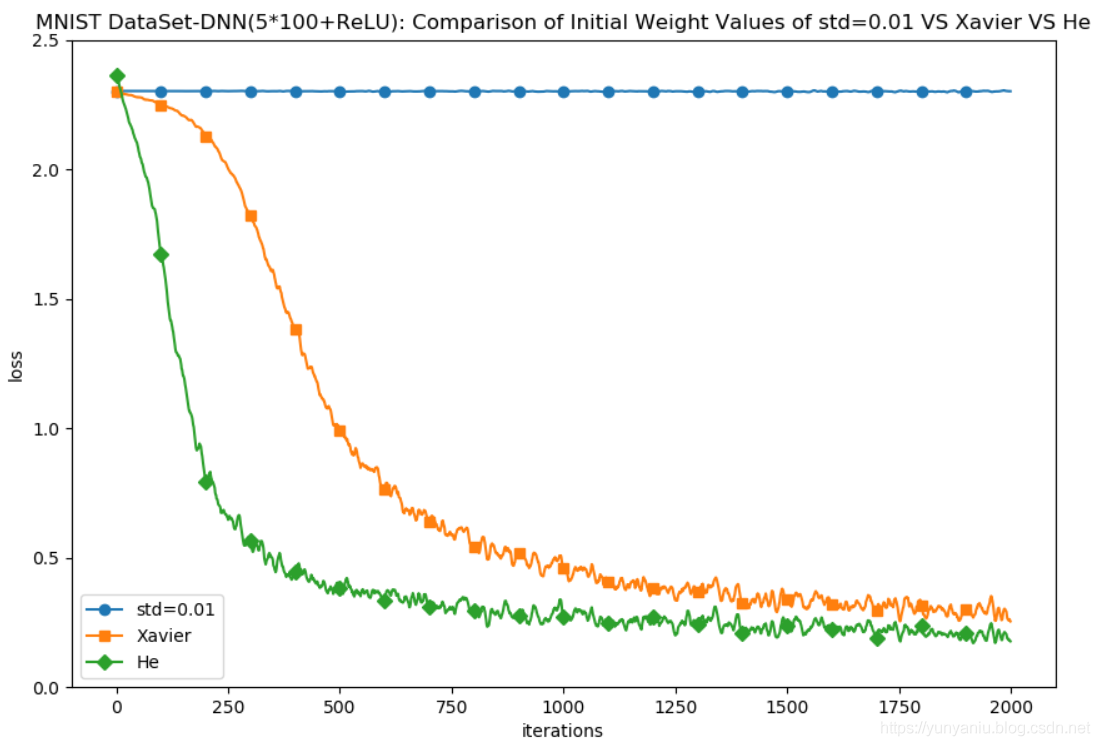
DL之DNN优化技术:自定义MultiLayerNet【5*100+ReLU】对MNIST数据集训练进而比较三种权重初始值(Xavier参数初始化、He参数初始化)性能差异
输出结果===========iteration:0===========std=0.01:2.302533896615576Xavier:2.301592862642649He:2.452819600404312...
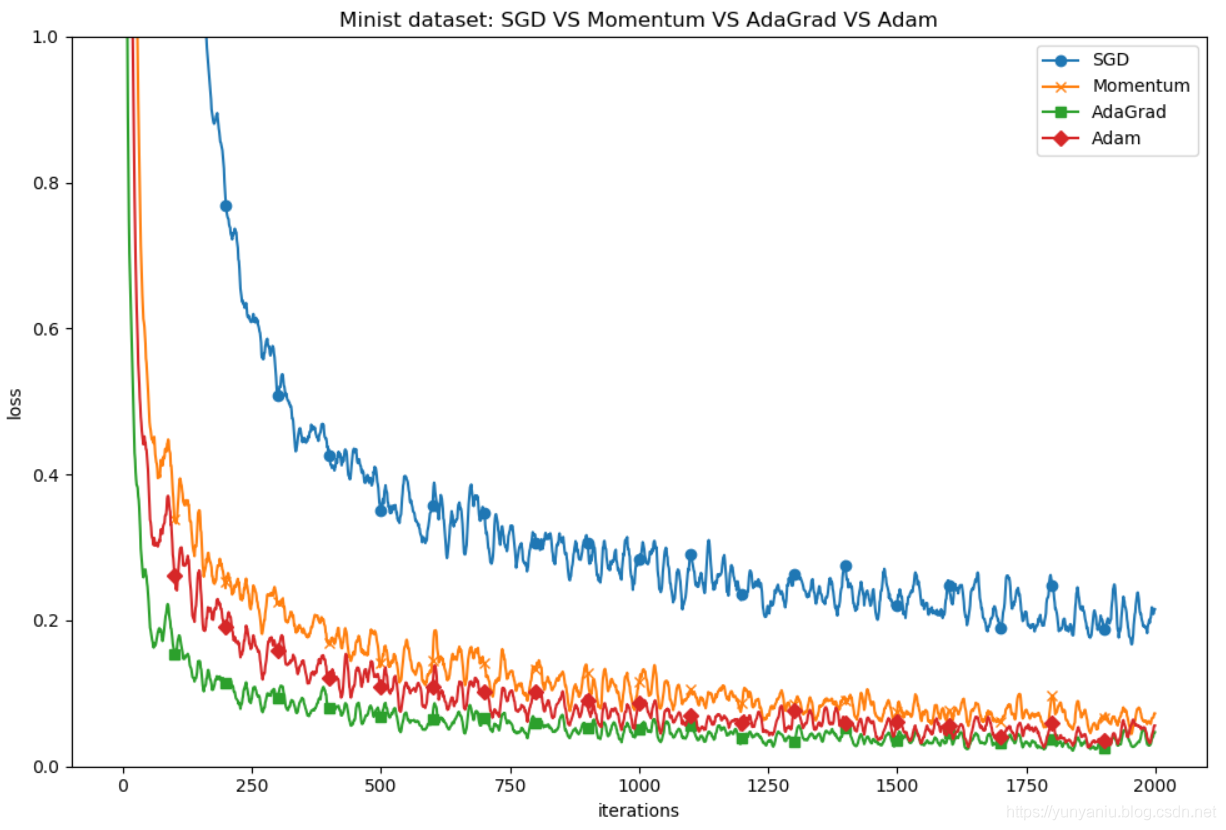
DL之DNN:自定义MultiLayerNet(5*100+ReLU+SGD/Momentum/AdaGrad/Adam四种最优化)对MNIST数据集训练进而比较不同方法的性能
输出结果===========iteration:0===========SGD:2.289282108880558Momentum:2.2858501933777964AdaGrad:2.135969407893337A...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。