DataWorks数据集成的Hive数据源测试连通性报principal initiate f...
DataWorks数据集成的Hive数据源测试连通性报principal initiate failed
DataWorks数据集成hive是不支持数组
DataWorks数据集成hive是不支持数组

DataWorks报错问题之集成hive数据源报错如何解决
问题一:DataWorks中 di节点从mc同步数据到FTP txt文本产生Exception 怎么回事? DataWorks中 di节点从mc同步数据到FTP txt文本产生Exception in thread "pool-2-thread-1" java.lang.OutOfMemoryErr...
Apache Hudi与Hive集成手册
1. Hudi表对应的Hive外部表介绍 Hudi源表对应一份HDFS数据,可以通过Spark,Flink 组件或者Hudi客户端将Hudi表的数据映射为Hive外部表,基于该外部表, Hive可以方便的进行实时视图,读优化视图以及增量视图的查询。 2. Hive对Hudi的集成 这里以Hive3....
DataWorks数据集成中,使用的用户为hive用户,和配置的用户(root)不一致,如何解决?
DataWorks数据集成中,当数据的目的端是hive,发现在进行hive分区truncate操作的时候,datax的临时文件移动到hive分区表目录下时,使用的用户为hive用户,和配置的用户(root)不一致,导致文件操作权限不足,报错。目前数据集成writer端相关配置均为root。 1) "...
DataWorks数据集成中,当数据的目的端是hive,如何设置写入hive的用户为指定用户呢?
DataWorks数据集成中,当数据的目的端是hive,如何设置写入hive的用户为指定用户呢?目前在hive数据源配置了user为root,但实际写入的还是admin用户?
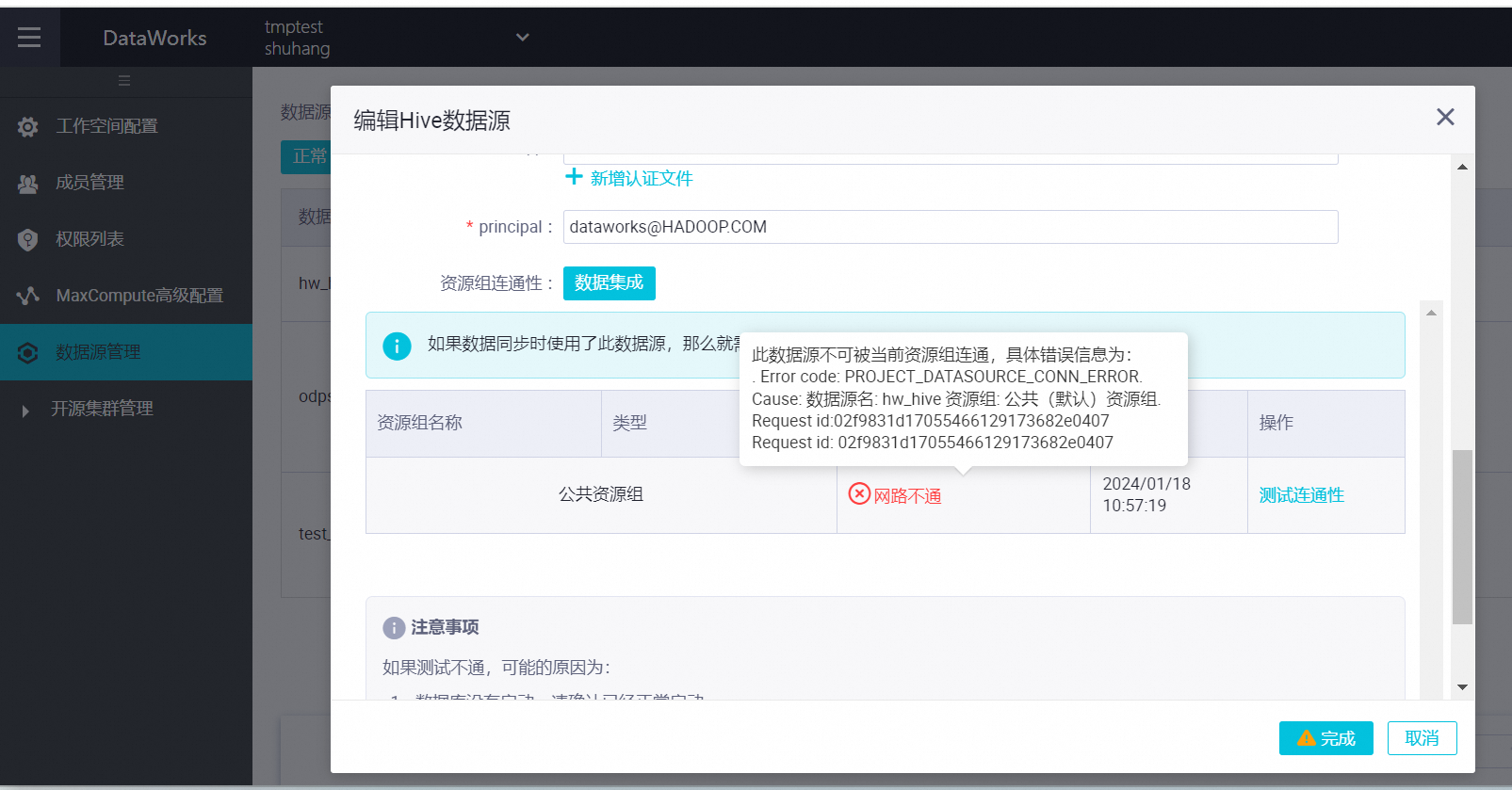
dataworks集成hive数据源报错,网络、票据测试都是ok的,报这个错误应该怎么解决?
dataworks集成hive数据源报错,网络、票据测试都是ok的,报这个错误应该怎么解决?

将Sqoop与Hive集成无缝的数据分析
将Sqoop与Hive集成是实现无缝数据分析的重要一步,它可以将关系型数据库中的数据导入到Hive中进行高级数据处理和查询。本文将深入探讨如何实现Sqoop与Hive的集成,并提供详细的示例代码和全面的内容,以帮助大家更好地了解和应用这一技术。 为什么将Sqoop与Hive集成? 将Sqoop与Hi...
Spark与Hive的集成与互操作
Apache Spark和Apache Hive是大数据领域中两个非常流行的工具,用于数据处理和分析。Spark提供了强大的分布式计算能力,而Hive是一个用于查询和管理大规模数据的数据仓库工具。本文将深入探讨如何在Spark中集成和与Hive进行互操作,以充分利用它们的强大功能。 Spark与Hi...
流数据湖平台Apache Paimon(四)集成 Hive 引擎
第3章 集成 Hive 引擎前面与Flink集成时,通过使用 paimon Hive Catalog,可以从 Flink 创建、删除、查询和插入到 paimon 表中。这些操作直接影响相应的Hive元存储。以这种方式创建的表也可以直接从 Hive 访问。更进一步的与 Hive 集成,可以使用 Hiv...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







