[帮助文档] 在EMR集群运行TPC-DS Benchmark
TPC-DS是大数据领域最为知名的Benchmark标准。阿里云E-MapReduce多次刷新TPC-DS官方最好成绩,并且是第一个通过认证的可运行TPC-DS 100 TB的大数据系统。本文介绍如何在EMR集群完整运行TPC-DS的99个SQL,并得到最佳的性能体验。
[帮助文档] 慢查询、全部查询和运行中大查询
EMR StarRocks Manager针对您提交的查询(Query)记录提供诊断与分析的能力。支持运行中大查询、慢查询及全部查询两种维度的查询记录展示。


MapReduce计数器,Tash的运行机制,shuffle过程,压缩算法
MapReduce当中的计数器计数器是收集作业统计信息的有效手段之一,用于质量控制或应用级统计。计数器还可辅助诊断系统故障。如果需要将日志信息传输到map 或reduce 任务, 更好的方法通常是看能否用一个计数器值来记录某一特定事件的发生。对于大型分布式作业而言,使用计数器更为方便。除了因为获取计...
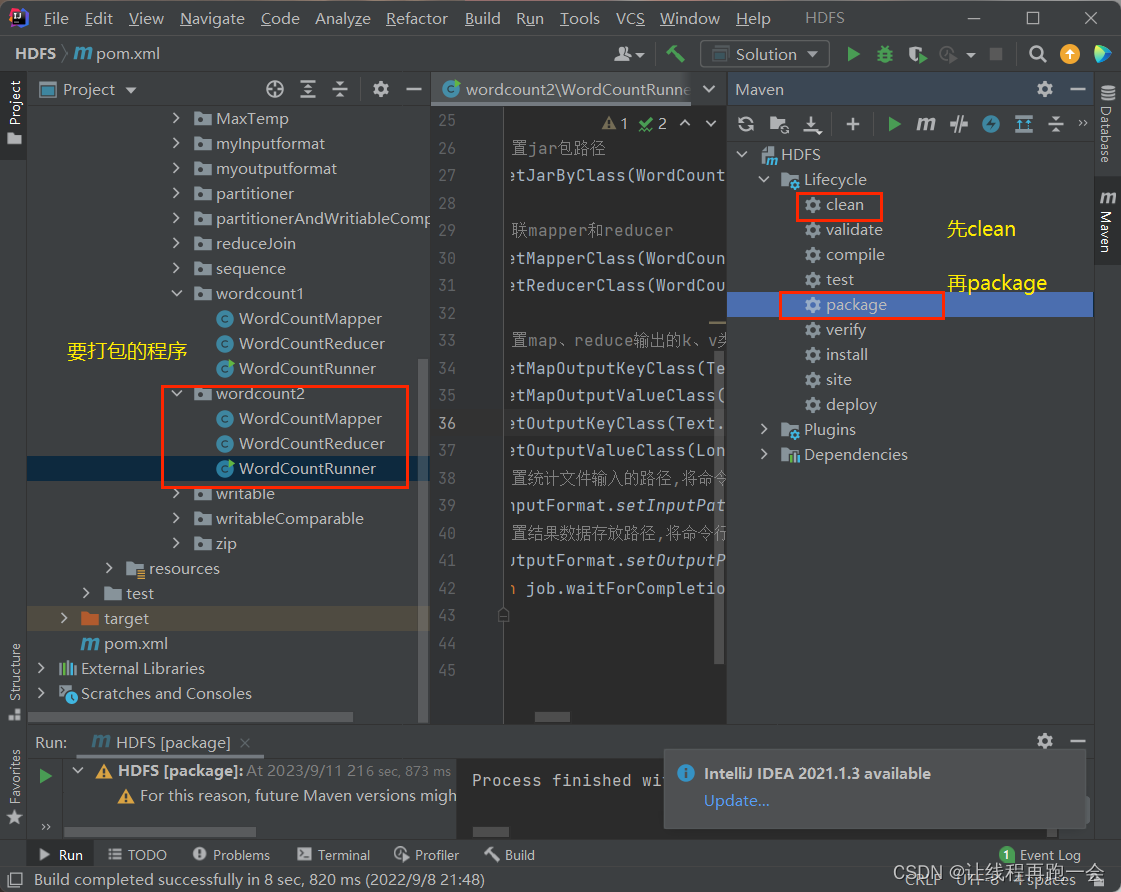
IDEA 打包MapReduce程序到集群运行的两种方式以及XShell和Xftp过期的解决
参考博客【MapReduce打包成jar上传到集群运行】http://t.csdn.cn/2gK1d【Xshell7/Xftp7 解决强制更新问题】http://t.csdn.cn/rxiBGIDEA打包MapReduce程序(方式一)【轻量级打包】这里的打包是打包整个项目,后期等学会怎么打包单个指...
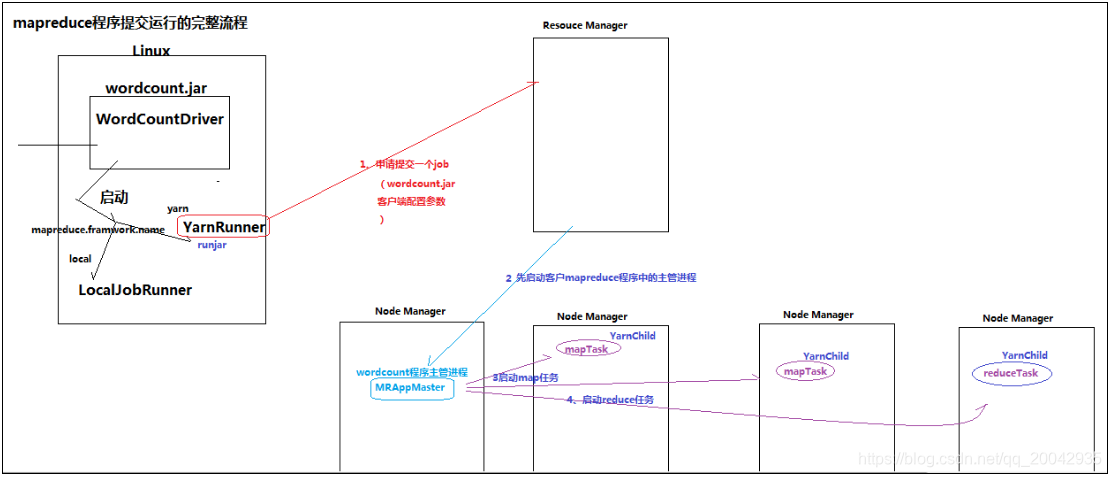
23 MAPREDUCE程序运行模式
本地运行模式1)mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行2)而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上3)怎样实现本地运行?写一个程序,不要带集群的配置文件(本质是你的mr程序的conf中是否有mapreduce.framework.na...
机器学习PAI这个Mapreduce需要在max compute环境里面运行,本地怎么运行啊?
机器学习PAI这个Mapreduce需要在max compute环境里面运行,本地怎么运行啊8月22日 12:23?

伪分布式安装部署(运行MapReduce程序)
启动HDFS并运行MapReduce程序1. 配置集群(a)配置:hadoop-env.shLinux系统中获取JDK的安装路径:echo $JAVA_HOME修改JAVA_HOME 路径: 把这一行代码改成下面的代码,前一半都是export JAVA_HOME=,很好找。export J...
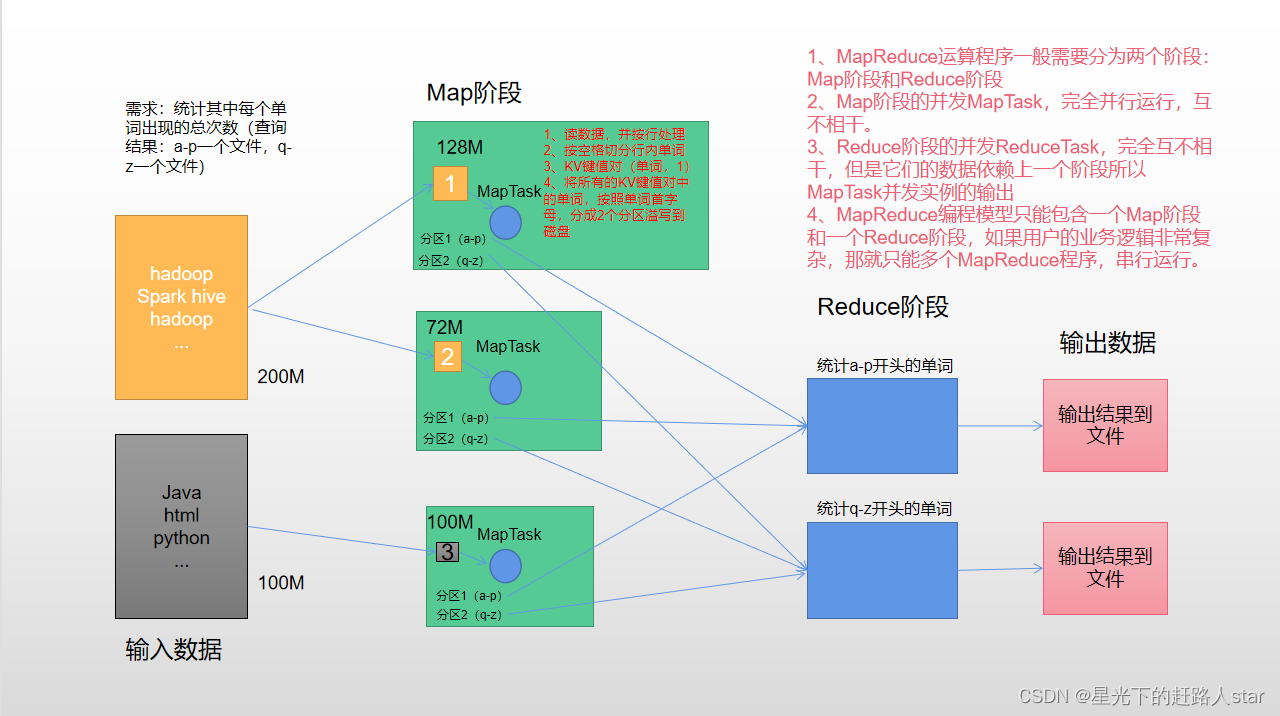
Hadoop基础学习---5、MapReduce概述和WordCount实操(本地运行和集群运行)、Hadoop序列化
1、MapReduce概述1.1 MapReduce定义MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。1.2...
MapReduce程序运行部署的几种方式 - 结尾附源码
概述MapReduce是一个计算模型和框架,Hadoop将其实现并整合,因此我们可以脱离Hadoop软件环境直接在项目中编码测试。在实际的生产环境中,每个计算任务都是以jar包的形式存在,周期性的以不同的参数提交执行,这是离线计算任务的常见模式。当然,在测试阶段,可能也会使用yarn方式远程提交集群...
[帮助文档] 如何使用Arm节点运行Spark作业
EMR on ACK默认部署在X86架构的节点上,您也可以通过配置,将Spark作业运行在Arm类型的弹性容器实例(ECI)上。本文为您介绍如何使用Arm节点运行Spark作业。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
mapreduce更多运行相关
mapreduce您可能感兴趣
- mapreduce分布式
- mapreduce编程
- mapreduce灰色
- mapreduce shell
- mapreduce role
- mapreduce notebook
- mapreduce控制台
- mapreduce任务
- mapreduce文件
- mapreduce源代码
- mapreduce hadoop
- mapreduce集群
- mapreduce spark
- mapreduce数据
- mapreduce作业
- mapreduce hdfs
- mapreduce maxcompute
- mapreduce程序
- mapreduce配置
- mapreduce yarn
- mapreduce oss
- mapreduce框架
- mapreduce案例
- mapreduce优化
- mapreduce wordcount
- mapreduce大数据