Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
Flink CDC写入了hive 后,hive是spark也不能直接对接页面即时查询。 后续怎么办?
Flink CDC写入了hive 后,hive是spark 也不能直接对接页面即时查询。 后续怎么办? 要实时的出数据在页面展现?


手把手教你大数据离线综合实战 ETL+Hive+Mysql+Spark
引言大家好,我是ChinaManor,直译过来就是中国码农的意思,俺希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,一个平凡而不平庸的人。1.第一章 综合实战概述数据管理平台(Data ManagementPlatform,简称DMP),能够为广告投放提供人群标签进行受众精准定向,并通过投放...
干翻Hadoop系列文章【02】:Hadoop、Hive、Spark的区别和联系
第一章:Hadoop和Hive以及Spark的关系是什么?Hadoop和Hive、Spark都是大数据领域的技术栈。一:大数据领域当中以后两个最为核心的问题1:数据怎么存储2:海量数据怎么计算单机系统时代。所有数据都在一个计算机上进行存储,数据处理任务都是IO密集型,而不是CPU密集型。数据分布式存...
大数据计算MaxCompute我开启了hive兼容,但是这个和hive、spark的有差异,为什么?
大数据计算MaxCompute我开启了hive兼容,但是这个和hive、spark的有差异,这个函数我其它两个产品都用过,别人都是连起来的字段如果中间某个字段是null,是用空白替换,整个字段数量是不变的,结果MC这里导致字段数量少了,非得加nvl判断下。。。
配置Hive使用Spark执行引擎
Hive引擎 概述 在Hive中,可以通过配置来指定使用不同的执行引擎。Hive执行引擎包括:默认MR、tez、spark MapReduce引擎: 早期版本Hive使用MapReduce作为执行引擎。MapReduce是Hadoop的一种计算模型,它通过将数据划分为小块并在集群上并行处理来完成计算...
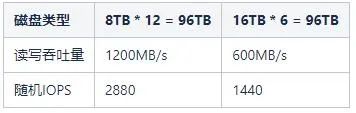
Hive 和 Spark 分区策略剖析
一、概述随着技术的不断的发展,大数据领域对于海量数据的存储和处理的技术框架越来越多。在离线数据处理生态系统最具代表性的分布式处理引擎当属Hive和Spark,它们在分区策略方面有着一些相似之处,但也存在一些不同之处。本篇文章将分析Hive与Spark分区策略的异同点、它们各自的优缺点,以及一些优化措...
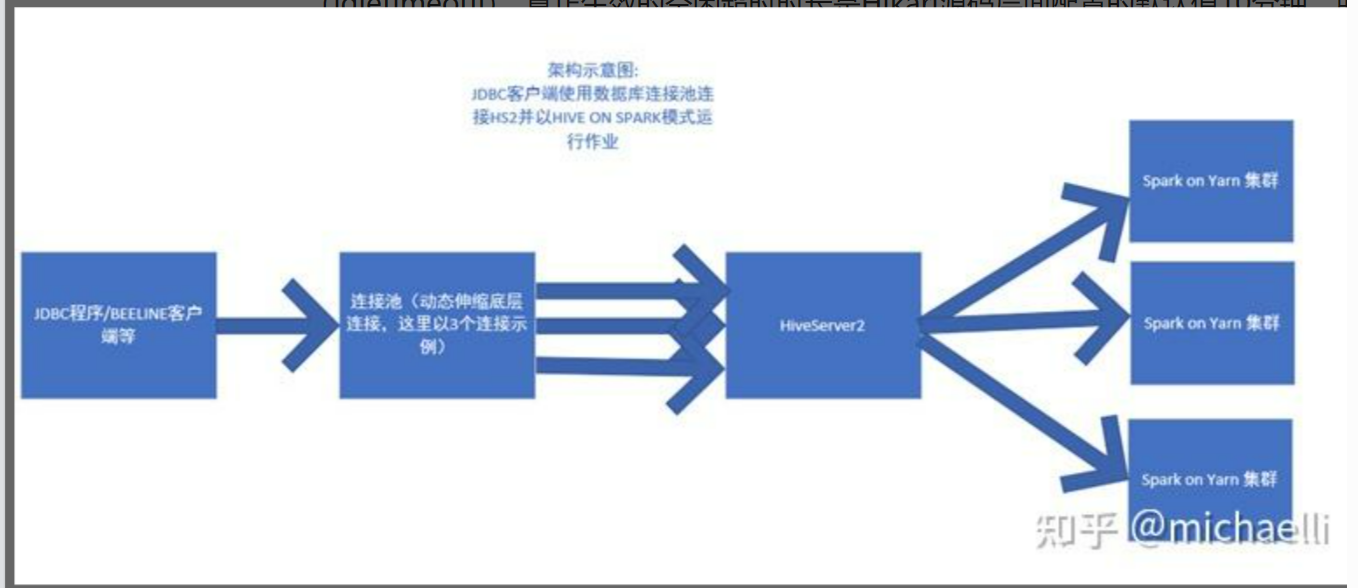
分享一个 hive on spark 模式下使用 HikariCP 数据库连接池造成的资源泄露问题
最近在针对某系统进行性能优化时,发现了一个hive on spark 模式下使用 HikariCP 数据库连接池造成的资源泄露问题,该问题具有普适性,故特地拿出来跟大家分享下。1 问题描述在微服务中,我们普遍会使用各种数据库连接池技术以加快获取数据库连接并执行数据查询的速度,这本质是一种空间换时间的...
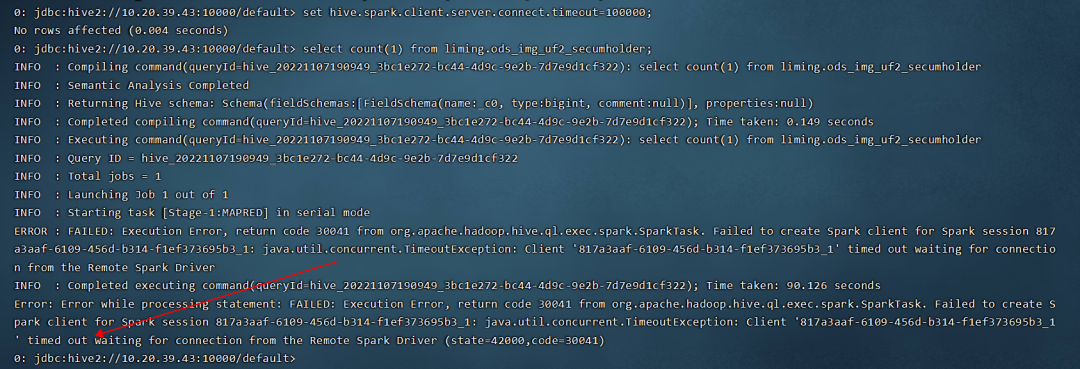
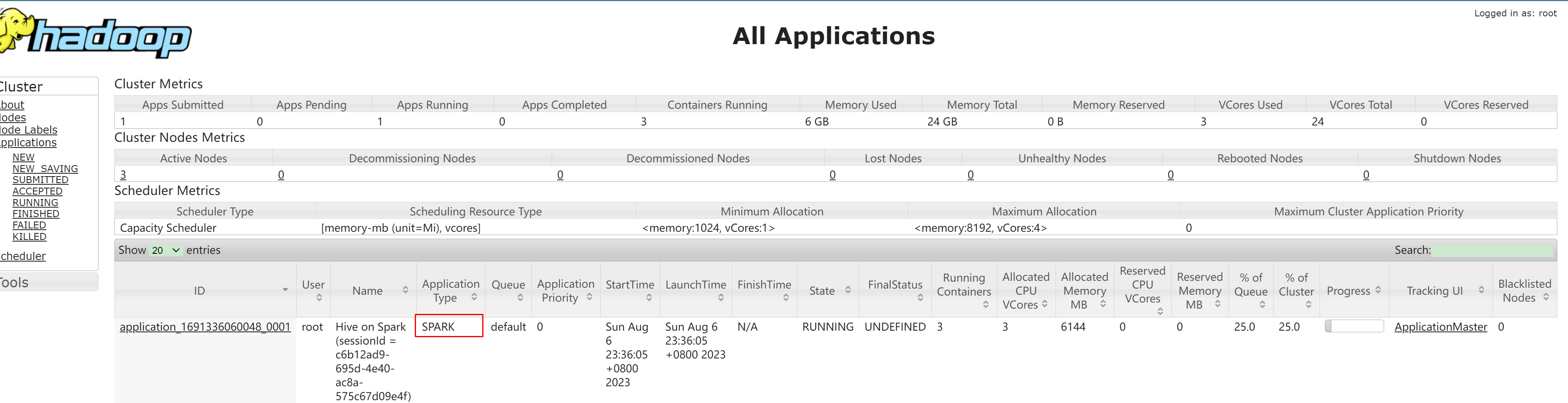
线上 hive on spark 作业执行超时问题排查案例分享
线上 hive on spark 作业执行超时问题排查案例分享大家好,在此分享一个某业务系统的线上 hive on spark 作业在高并发下频现作业失败问题的原因分析和解决方法,希望对大家有所帮助。1 问题现象某业务系统中,HIVE SQL 以 hive on spark 模式运行在 yarn上指...
成功解决This table may be a Hive-managed ACID table, or require some other capability that Spark问题
问题背景最近在使用 Create table 备份表 as select * from 源表的方式进行备份数据时,发现备份表是acid表,使用spark sql读取该表的时候,出现如下异常:they have the following capabilities: CONNECTORREAD,HIV...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作