[帮助文档] 在EMR Hive或Spark中访问OSS-HDFS
EMR-3.42及后续版本或EMR-5.8.0及后续版本的集群,支持OSS-HDFS(JindoFS服务)作为数据存储,提供缓存加速服务和Ranger鉴权功能,使得在Hive或Spark等大数据ETL场景将获得更好的性能和HDFS平迁能力。本文为您介绍E-MapReduce(简称EMR)Hive或S...
[帮助文档] EMRHive或Spark如何操作OSS-HDFS
EMR-3.42及后续版本或EMR-5.8.0及后续版本的集群,支持OSS-HDFS(JindoFS服务)作为数据存储,提供缓存加速服务和Ranger鉴权功能,使得在Hive或Spark等大数据ETL场景将获得更好的性能和HDFS平迁能力。本文为您介绍E-MapReduce(简称EMR)Hive或S...

Emr 自选的hive ,spark 版本兼容吗
Emr 自选的hive ,spark 版本兼容吗
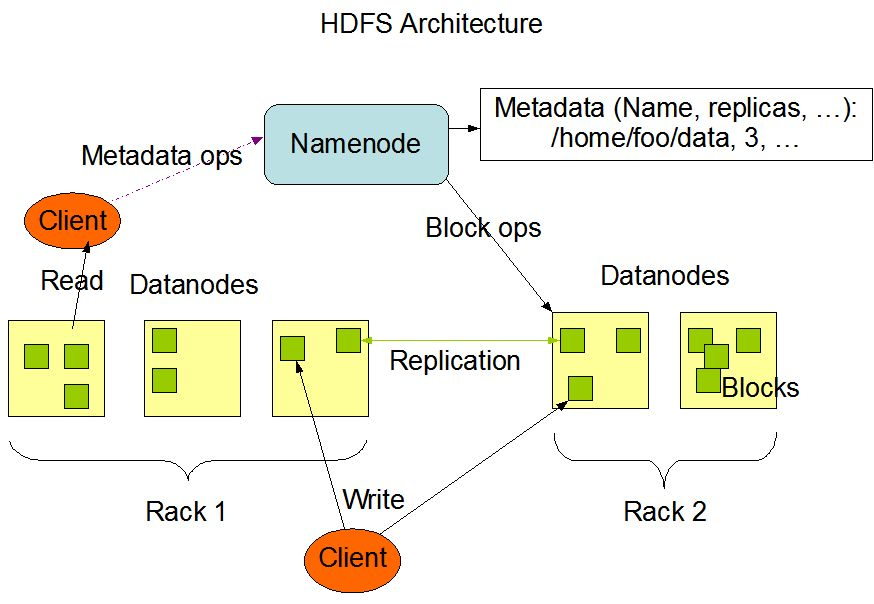
Hadoop、Hive、Spark 之间的关系?
5G 时代,运营商网络不断提速,成本越来越低,流量越来越便宜。给 互联网、物联网、互联网+ 各个行业的高速发展创造了非常好的有利条件,同时也产生了海量数据。如何做好数据分析,计算,提取有价值信息,大数据技术一直是一个热门赛道。今天我们就对 Hadoop、Hive、Spark 做下分析对比。Hadoo...
[帮助文档] 提交Spark任务报错UnabletoinstantiateSparkSessionwithHivesupportbecauseHiveclassesarenotfound.
问题描述Dataphin中提交Spark任务报错“Unable to instantiate SparkSession with Hive support because Hive classes are not found.”是什么原因?问题原因用户使用的计算引擎是hadoop集群,任务执行机器信...
Hive、Spark无法直接使用官方SDK,哪它们将可以怎么使用呢?
Hive、Spark无法直接使用官方SDK,哪它们将可以怎么使用呢?
Hive中Spark有哪些特性?
Hive中Spark有哪些特性?
创建hive sql作业时 hive组件已经配置引擎为spark为啥作业运行时还是跑mr
创建hive sql作业时 hive组件已经配置引擎为spark为啥作业运行时还是跑mr

Hive引擎Spark优化配置参数2
扩展spark driver 动态资源分配 在 Facebook,Spark 集群启用了动态资源分配(Dynamic Executor Allocation),以便更好的使用集群资源,而且在 Facebook 内部,Spark 是运行在多租户的集群上,所以这个也是非常合适的。比如典型的配置如下: s...

Hive引擎Spark优化配置参数1
Hive是大数据领域常用的组件之一,主要是大数据离线数仓的运算,关于Hive的性能调优在日常工作和面试中是经常涉及的的一个点,因此掌握一些Hive调优是必不可少的一项技能。影响Hive效率的主要有数据倾斜、数据冗余、job的IO以及不同底层引擎配置情况和Hive本身参数和HiveSQL的执行等因素。...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark产品
- apache spark k8s
- apache spark深度学习
- apache spark集群
- apache spark分析
- apache spark数据
- apache spark数据库
- apache spark可视化分析
- apache spark决策
- apache spark可视化
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark任务
- apache spark程序