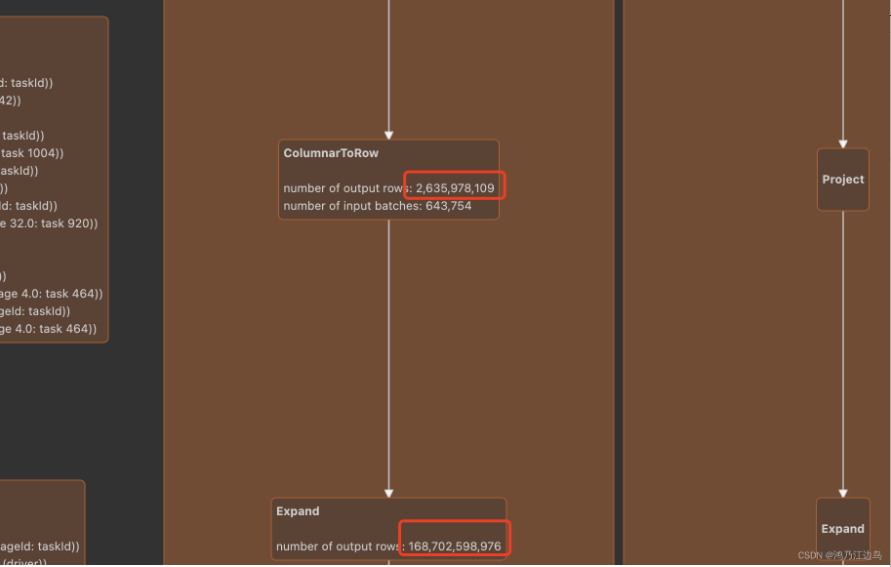
SPARK Expand问题的解决(由count distinct、group sets、cube、rollup引起的)
背景本文基于spark 3.1.2我们知道spark对于count(distinct)/group sets 以及cube、rollup的处理都是采用转换为Expand的方法处理,这样做的优点就是在数据量小的情况下,能有以空间换时间,从而达到加速的目的。但是弊端也是很明显,就是在数据量较大的情况下,...
如何在Spark中实现Count Distinct重聚合
背景 Count Distinct是SQL查询中经常使用的聚合统计方式,用于计算非重复结果的数目。由于需要去除重复结果,Count Distinct的计算通常非常耗时。 以如下查询为例,Count Distinct的实现方式主要有两种: SELECT region, COUNT(DISTINCT u...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark分析
- apache spark数据
- apache spark数据库
- apache spark可视化分析
- apache spark决策
- apache spark可视化
- apache spark Mapreduce
- apache spark SQL
- apache spark Python
- apache spark决策树
- apache spark streaming
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark任务
- apache spark程序